Os 4 níveis de autonomia em Agentic Code: do autocompletar ao agente que faz deploy sozinho
A frase que mais ouço em call de cliente nos últimos meses é: "agora é só dar o problema pro agente e ele resolve". Bonito de slide. Péssimo de roadmap. Quem está rodando agentes em código de verdade já entendeu que a régua não é "o agente faz" ou "o agente não faz". A régua é quem aprova, quem reverte e quem audita cada ação que ele toma.
A própria Anthropic, no estudo de autonomia em produção, mostra que 80% das ações de agentes em código têm algum mecanismo de salvaguarda e 73% ainda passam por algum tipo de envolvimento humano. Apenas 0,8% são irreversíveis. Não é por covardia: é porque autonomia sem gate é prejuízo esperando para acontecer.
Neste post a gente arruma a casa. Vou destrinchar quatro níveis de autonomia agentic code que você consegue mapear hoje no seu time, com critério objetivo de promoção, exemplos reais (Copilot, Cursor, Claude Code, agentes em CI) e os gates de engenharia que sustentam cada degrau.
TL;DR
- O que é: uma escala prática de níveis de autonomia agente em desenvolvimento de software, com critérios objetivos de aprovação, reversão e auditoria.
- Stack/Modelos citados: GitHub Copilot, Cursor (tab + Composer), Claude Code (default + plan + auto), Claude Opus/Sonnet 4.x, GitHub Actions.
- Para quem: tech lead, staff, head de engenharia ou dev sênior que quer subir o time de nível sem virar manchete por agente que dropou tabela em produção.
- Fonte central: Measuring AI agent autonomy in practice — Anthropic e o 2026 Agentic Coding Trends Report.
O que define um "nível" — e o que NÃO define
Vamos tirar o hype do caminho.
Nível de autonomia em agentic code não é quão "esperto" o modelo é. Opus 4.7 rodando atrás de um humano que aprova cada keystroke é nível 1. Sonnet 4.6 rodando dentro do GitHub Actions, abrindo PR sozinho, é nível 4. Mesmo modelo, comportamentos completamente diferentes.
O que define o nível são três perguntas operacionais:
- Quem aprova a próxima ação? O dev clica? O dev aprova um plano antes? Ninguém aprova e o agente toca?
- Quem reverte se der ruim? O dev volta no CTRL+Z? Existe rollback automatizado? O blast radius é local ou bate em produção?
- Quem audita depois? Tem log? Tem trilha em git? Tem eval rodando contra cada saída? Ou ninguém olha?
Os quatro níveis abaixo são, no fundo, quatro combinações dessas três respostas. Quanto mais alto o nível, mais cara fica a infraestrutura ao redor — não o modelo. Esse é o ponto que a galera vendendo "agente que faz tudo" sempre esquece de contar.
Nível 1 — Assistente (humano sempre no loop)
Exemplo canônico: GitHub Copilot tab completion, Cursor inline tab, autocompletar do Codeium.
O agente sugere. O humano aceita. Não tem ação executada sem o dev tocar no teclado, não tem comando rodado, não tem arquivo modificado fora do que aparece como diff inline.
- Quem aprova: o dev, em cada token aceito.
- Quem reverte: CTRL+Z, ou simplesmente não aceitar.
- Quem audita: ninguém precisa. O humano é a auditoria em tempo real.
Esse nível é o "modo seguro" do agentic code. É também o que a Anthropic chama de HITL puro — human-in-the-loop, com o humano dentro do laço de controle. Funciona bem para tarefas curtas, código boilerplate, scaffolding de testes. É o nível com menor blast radius e o de adoção mais rápida no time.
A armadilha é confundir nível 1 com produtividade alta. Aceitar 200 sugestões de tab por dia te faz digitar mais rápido. Não te faz entregar feature mais rápido. Quem trata Copilot como ChatGPT que escreve linha por linha está deixando ROI na mesa.
Nível 2 — Copiloto agente (humano aprova bloco)
Exemplo canônico: Claude Code no modo default, Cursor Composer/Agent.
Aqui o agente já planeja em multi-arquivo, propõe diffs maiores, executa comando, lê output de teste e itera. Mas pausa antes de cada ação não-trivial: "posso rodar pnpm test?", "posso editar src/auth/middleware.ts?", "posso commitar?".
- Quem aprova: o dev, por bloco de ação. Cada
Edit,Bash,Writepassa por um prompt. - Quem reverte: git, reset, e a memória do dev de qual arquivo o agente mexeu.
- Quem audita: o histórico da sessão + o diff do branch.
Esse é o nível em que a maioria dos times está hoje, e é também o nível em que a relação entre o dev e o agente começa a parecer trabalho de dupla. O dev abandona o teclado, vai pegar café, volta, aprova o próximo passo, intervém quando o agente vai para o caminho errado. A própria Anthropic observa esse comportamento na base de usuários do Claude Code: usuários novos auto-aprovam ~20% das ações; usuários com mais de 750 sessões pulam para mais de 40%, mas em compensação aumentam a taxa de interrupção (de ~5% para ~9%).
Tradução prática: quanto mais maduro o usuário, mais ele migra de HITL (aprovo tudo) para HOTL — human-on-the-loop, onde o humano monitora e intervém quando o agente sai do trilho. É uma transição de papel, não de carga de trabalho.
Custo desse nível: você paga em tokens, em interrupções de fluxo do dev e na fadiga de aprovação. Quem nunca clicou "yes" automático sem ler o prompt do Claude Code que atire o primeiro CTRL+C.
Nível 3 — Agente supervisionado (humano aprova plano)
Exemplo canônico: Claude Code com plan mode, Cursor com plano explícito, qualquer harness customizado em cima do Claude Agent SDK.
A diferença para o nível 2 é cirúrgica e enorme: a aprovação humana migra do plano de ação em vez da ação isolada. O dev olha o plano completo ("vou criar X, modificar Y, rodar Z, abrir PR"), aprova uma vez, e o agente executa sem pedir licença para cada passo.
- Quem aprova: o dev, no plano, antes da execução.
- Quem reverte: git checkpoint antes do plano + rollback automático em caso de teste vermelho.
- Quem audita: trilha completa em git, log da sessão, e idealmente um eval rodando sobre o resultado.
É aqui que o Claude Code documentado pela InfoQ no anúncio do Auto Mode começa a brilhar. O classificador em dois estágios deixa ações seguras passarem direto e escala apenas o que é incerto. O dev consegue, na prática, "abandonar" a sessão por 20–45 minutos e voltar para revisar o resultado. A própria Anthropic relata que a duração média da sessão autônoma do Claude Code quase dobrou em três meses, de menos de 25 minutos para mais de 45.
Esse nível só existe com infraestrutura ao redor. Sem testes confiáveis, plan mode é roleta. Sem pre-commit hook, é commit envenenado. Sem branch isolado, é conflito garantido. Subir do 2 para o 3 é menos sobre o agente e mais sobre higiene de engenharia.
Nível 4 — Agente autônomo (humano só revisa output final)
Exemplo canônico: GitHub Copilot Coding Agent rodando em ambiente efêmero do GitHub Actions, harness próprio em CI/CD que pega issue do backlog e abre PR sozinho, FlakyGuard da Uber corrigindo 197 testes flaky em 6 meses sem intervenção humana por tarefa.
O dev não está na sessão. O agente é acionado por um trigger (issue atribuída, label, schedule, webhook), abre o PR, roda os testes, ajusta até verde, e entrega para review humano só no fim.
- Quem aprova: ninguém durante a execução. O humano aprova o PR final antes do merge.
- Quem reverte: rollback de deploy, revert do PR, kill switch do harness.
- Quem audita: logs estruturados, métricas de custo por job, evals automáticas no output, RBAC granular do que cada agente pode tocar.
Aqui mora a parte que a galera não fala em conferência: o agente nível 4 só funciona em escopos bem delimitados. Bug fix isolado, atualização de dependência, refactor mecânico, geração de boilerplate. Tarefa ambígua continua precisando de humano. O relatório 2026 da Anthropic tem um número que coloca isso no chão: devs hoje usam IA em ~60% do trabalho, mas só conseguem delegar totalmente entre 0% e 20% das tarefas. Os outros 40% que estão no meio é exatamente onde os níveis 2 e 3 vivem.
E custo? No nível 4 você paga em compute (cada job do agente é uma sessão completa), em janela de evals (você precisa medir continuamente), em RBAC (cada permissão que o agente recebe é um vetor de ataque). Não é coincidência que o caso da Rakuten relatado pela Anthropic, com 79% de redução no time-to-market (de 24 para 5 dias úteis), tenha vindo acompanhado de "centenas de agentes internos" com governança específica.
Os quatro gates que sustentam qualquer nível
Não importa o nível em que você está — o que muda de degrau para degrau é a profundidade desses quatro gates. Cada subida exige todos eles em estado mais maduro.
Testes
No nível 1 e 2, teste é a régua que o dev usa antes de aceitar. No nível 3 e 4, teste é a única régua. Se o agente rodou, os testes passaram e o pre-commit aprovou, é porque está bom. Se a sua suíte é flaky ou tem cobertura furada, não suba para nível 3. Você vai estar dando autonomia para uma régua quebrada.
Evals
Teste valida correção de código. Eval valida correção de comportamento do agente. No nível 4, ter um conjunto de casos rodando contra cada saída do agente (LLM-as-a-judge, golden dataset, comparação contra baseline) deixa de ser luxo e vira fundação. Sem eval, você não tem como saber se o agente está degradando ao longo do tempo.
RBAC e blast radius
Quanto mais alto o nível, mais explícito tem que ser o que o agente pode tocar. No nível 1, blast radius é o arquivo aberto. No nível 4, é o repo inteiro, o cluster, o banco de produção. Isolamento por ambiente efêmero, allowlist de comandos, segredos via vault, limite de escrita por path — tudo isso vira pré-requisito, não nice-to-have.
Custo
Custo é o gate que ninguém quer falar e que mata projeto silencioso. Nível 1 cobra mensalidade fixa. Nível 4 cobra por job, por minuto de execução, por tokens consumidos em iteração. Sem budget por sessão, sem limite de retry, sem alerta de gasto, o seu agente nível 4 vai virar um terror financeiro antes de virar um terror de segurança.
Como subir um nível sem queimar o time nem a empresa
Quem tenta saltar do 1 direto pro 4 quebra a cara. A subida saudável é por estágio, e cada subida começa fora do agente, na infraestrutura.
Antes de subir do nível 1 para o 2, garanta que o time tem disciplina mínima de branch isolado e sabe ler um diff grande sem aprovar no automático. O risco aqui é fadiga de aprovação virar carimbo de borracha.
Antes de subir do nível 2 para o 3, exija: suíte de testes verde como linha de base, pre-commit hook que pega o que escapar, e um agente com plano explícito — não plan mode interno, mas plano que o dev leu e validou. Plan mode sem testes fortes é só Russian roulette mais lenta.
Antes de subir do nível 3 para o 4, monte: ambiente isolado por job (container efêmero, sandbox), RBAC explícito por operação, eval rodando sobre cada saída, kill switch acessível ao dev de plantão e budget máximo por job. Comece com um único caso de uso bem definido (ex: bump de dependência semver-minor com testes verdes) antes de soltar para escopo aberto.
Esse processo de subir de nível com critério, montar os gates antes do agente, escolher onde delegar e onde manter humano, é exatamente o tema do workshop ao vivo Harness Engineering com Claude Code, onde a gente constrói um harness próprio em cima do Claude Agent SDK do nível 2 ao 4, com testes, evals, RBAC e o loop autônomo rodando em produção.
FAQ rápido
"Plan mode não é nível 4 já?" Não. Plan mode é nível 3: o dev aprova o plano antes da execução. Nível 4 é o agente sendo acionado por trigger (issue, schedule, webhook) sem dev na sessão.
"Vibe coding entra em qual nível?" Depende do que você chama de vibe coding. Se é o dev mandando "faz aí" no Cursor Composer e aceitando tudo, é nível 2 com gate fraco — risco alto de débito técnico. Se é prompt único disparando harness com testes e plan mode, é nível 3 disfarçado.
"Posso ter níveis diferentes para tarefas diferentes no mesmo time?" Sim, e é o cenário mais comum. Bump de dependência em nível 4. Migration de schema em nível 2. Refactor de domínio crítico em nível 1, com pair programming. A escala não é dogma — é critério por escopo.
"Eval automatizado é mesmo obrigatório no nível 4?" Sim, no momento em que o agente é acionado sem dev na sessão. Sem eval contínuo, você só descobre que o agente regrediu pelo cliente reclamando. Promptfoo, custom judges com LLM-as-a-judge ou golden datasets em CI são as portas de entrada baratas.
O que fica
Os quatro níveis não são uma escada que todo mundo precisa subir. São uma régua para você parar de discutir agentic code em termos de "o agente é mágico" ou "o agente é furada", e começar a discutir em termos de gate, blast radius e auditoria.
Quem está no nível 1 hoje e tenta vender nível 4 internamente vai perder credibilidade. Quem está no nível 3 e segue tratando como nível 2 vai perder produtividade. O ganho real está em saber exatamente em que degrau cada parte do seu fluxo de engenharia mora — e em construir os gates certos para subir um por vez, sem queimar o time nem a empresa.
A próxima onda dos agentes de código não vai ser "modelo mais inteligente". Vai ser "harness mais maduro". E quem vai colher o ganho são os times que pararem de tratar autonomia como configuração de produto e começarem a tratar como decisão de engenharia.

{AI Engineer} — apaixonado por Laravel, arquitetura de software e construir produtos com impacto. Compartilho aqui tutoriais, descobertas e reflexões sobre o dia a dia de engenharia.
Você também pode gostar
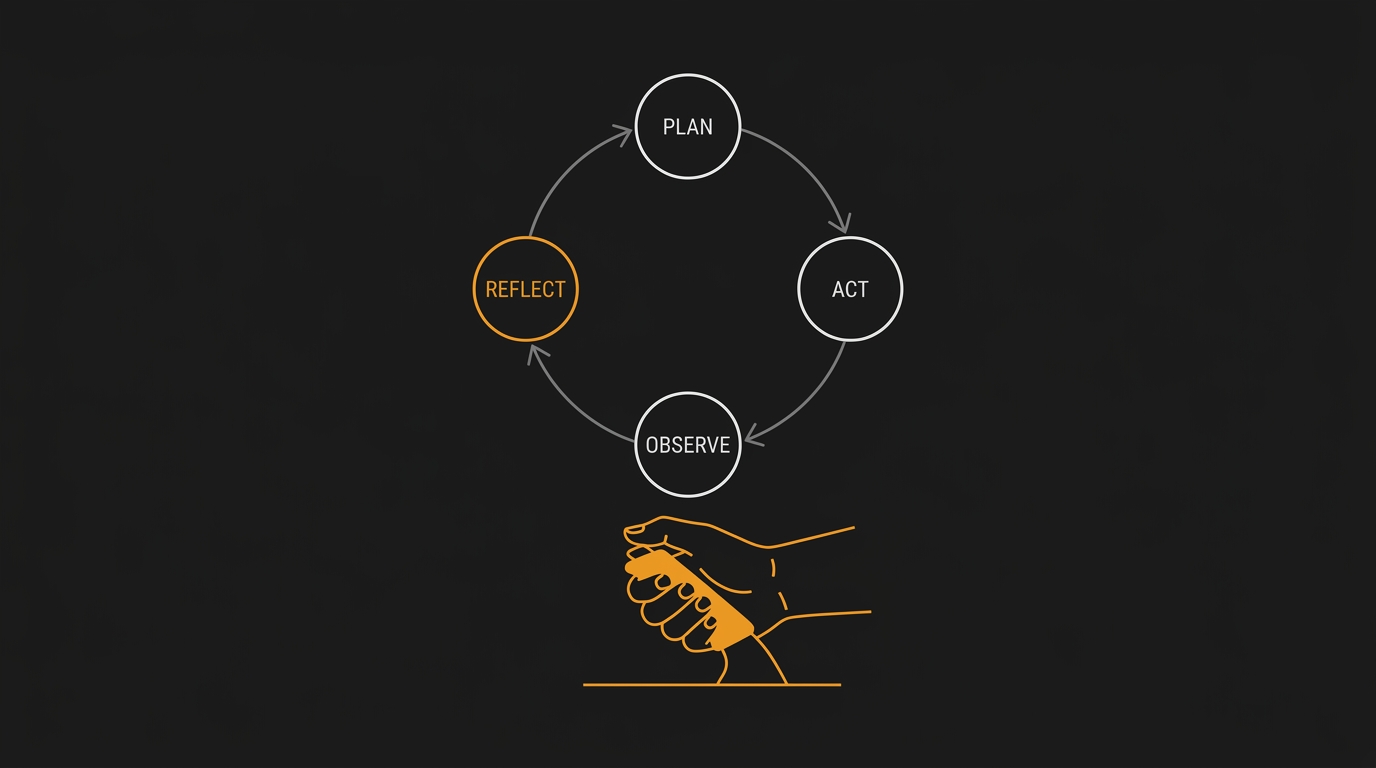
Agentic Code: o que muda quando o agente escreve, executa e testa o próprio código
Vibe coding deixou o dev no volante. SDD desenhou o mapa. Agentic Code tira o dev do carro e dá a chave pro agente, com freio de mão na mão. Cunhagem do termo em PT-BR, taxonomia de 4 níveis de autonomia, anatomia do ciclo plan/act/observe/reflect, demo comparativa de CRUD em três paradigmas, modos de falha reais e o que o harness precisa garantir pra rodar agente em produção sem quebrar tudo.
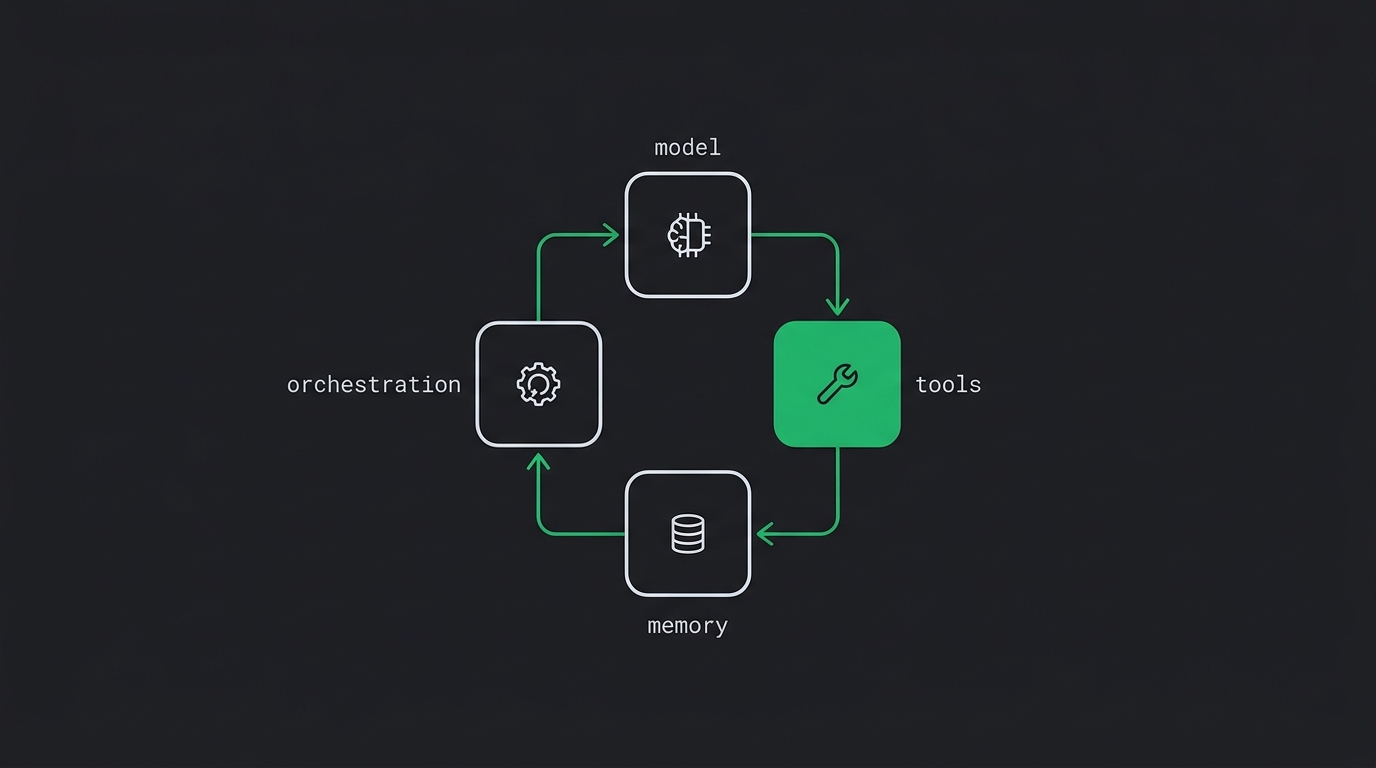
O que é um agente de IA (e o que é só um wrapper de prompt)
90% dos "agents" que você vê no LinkedIn são um if com esteroides. A definição honesta de o que é um agente de IA: o loop percepção→decisão→ação→observação e os quatro blocos mínimos — modelo, ferramentas, memória e orquestração. Falte um e o sistema vira burro depois da terceira mensagem.

Quando NÃO usar Agentic Code: 8 cenários onde o agente é prejuízo
Curva de hype joga todo mundo no extremo. Aqui está a lista honesta de 8 cenários onde, em 2026, o agente custa mais caro, demora mais e ainda erra mais que o time fazendo na mão, com explicação técnica, benchmarks e dor de produção.

Agent improvement loop: o ciclo que faz o agente melhorar o próprio código
Como montar um loop de auto-melhoria de agente — gera, testa, avalia, corrige — inspirado no agent improvement loop do Agents SDK da OpenAI. Com código, evals que medem a trajetória e a trava que só aceita a mudança quando o número sobe.
