Portfólio de AI Engineer: 5 projetos que abrem porta sem precisar de mestrado
Recrutador olha seu GitHub por 11 segundos. Se a primeira coisa que ele vê é um notebook chamado fine-tune-llama-colab.ipynb, parabéns: você acabou de virar mais um.
Não é maldade. Eye-tracking em recrutador é coisa séria — estudo da TheLadders mediu 7,4 segundos, Workopolis cravou 11s pra 60% dos avaliadores. Em compensação, recrutadores engajam 80% mais com projetos no GitHub que têm código rodando ou demo viva. Ou seja: o jogo não é colecionar 30 repos. É ter 5 que provam que você sabe construir.
Esse post lista os 5 projetos que separam dev curioso de AI engineer empregável. Cada um leva 1 a 3 fins de semana. Nenhum exige mestrado, GPU própria ou paper na NeurIPS. Todos têm um problema técnico real que o recrutador entende em 30 segundos. E no final, te mostro como descrever cada um em 3 linhas no LinkedIn — sem soar a "criei uma IA revolucionária".
TL;DR
- O que é: 5 projetos de portfólio para AI engineer, do agente com tool use ao harness em produção.
- Stack: Python, Anthropic SDK (ou OpenAI), Promptfoo, Ragas, Langfuse, GitHub Actions.
- Custo: chave de API paga, ~$5 a $20 por projeto se você não enrolar.
- Tempo: 1 a 3 fins de semana cada.
- Pré-requisito: saber Python no nível "leio e escrevo sem AI". O resto a gente cobre.
Por que o portfólio óbvio falha
Tem um padrão de portfólio de "AI engineer junior" que circula em todo bootcamp e não convence ninguém:
- Notebook de fine-tuning de Llama 7B no Colab que treinou por 20 minutos e nunca rodou de novo.
- Wrapper de ChatGPT em Streamlit com prompt fixo.
- "Chatbot" que é só
chat.completion.create()num while loop. - Clone de RAG do tutorial de tal influencer, com PDF aleatório, sem nenhuma métrica.
O problema não é a tecnologia. É que esses projetos não respondem nenhuma das perguntas que o recrutador de AI engineering faz em 2026. Segundo o relatório da LinkedIn de skills em alta para 2026, AI engineering, engenharia de prompt e tuning de modelo são as habilidades que mais cresceram globalmente, e o que aparece embaixo é sempre o mesmo: retrieval, agentes autônomos, eval, deployment.
Note o que não está na lista. "Treinou modelo do zero" não está. "Sabe a matemática do transformer" não está. "Leu o paper original" não está.
O que entra no lugar: você consegue colocar uma feature de IA na frente de um usuário sem que ela exploda?
Os cinco projetos abaixo são desenhados pra responder isso. Em ordem crescente de seriedade.
Projeto 1 — Agente de atendimento com tool use real (não eco)
A diferença entre "agente" de bootcamp e agente de verdade é uma palavra: decisão. O bootcamp manda o LLM responder texto, dá um nome bonito pro while, e diz que é agente. Não é. Agente é quando o modelo decide qual tool chamar, com quais argumentos, e o que fazer se a tool falhar.
A documentação da Anthropic descreve o ciclo com clareza: o modelo recebe a definição das tools, escolhe uma com argumentos válidos, sua infra executa, devolve o resultado e o modelo decide o próximo passo. Você implementa esse loop com 3 a 5 tools de verdade.
Tema do projeto: agente de suporte que olha pedido, consulta status de entrega, registra reclamação e dispara reembolso. Tudo mockado em SQLite + funções locais — o ponto não é integrar com Shopify, é mostrar arquitetura.
from anthropic import Anthropic
client = Anthropic()
tools = [
{
"name": "get_order",
"description": "Busca um pedido por ID. Retorna status, itens e data de envio.",
"input_schema": {
"type": "object",
"properties": {"order_id": {"type": "string"}},
"required": ["order_id"],
},
},
{
"name": "issue_refund",
"description": "Emite reembolso parcial ou total. Use só após confirmar elegibilidade.",
"input_schema": {
"type": "object",
"properties": {
"order_id": {"type": "string"},
"amount_cents": {"type": "integer"},
"reason": {"type": "string"},
},
"required": ["order_id", "amount_cents", "reason"],
},
},
]
def run_agent(user_msg: str) -> str:
messages = [{"role": "user", "content": user_msg}]
while True:
resp = client.messages.create(
model="claude-sonnet-4-6",
max_tokens=1024,
tools=tools,
messages=messages,
)
if resp.stop_reason == "end_turn":
return resp.content[0].text
messages.append({"role": "assistant", "content": resp.content})
messages.append({
"role": "user",
"content": [handle_tool(b) for b in resp.content if b.type == "tool_use"],
})
O que prova ao recrutador:
- Você entende o protocolo de tool use (não é "function calling de exemplo").
- Sabe lidar com
stop_reason, erro de tool, e parada do loop. - Pensou em descrição de tool — porque descrição ruim é igual a agente que chama tool errada.
Repositório precisa ter: script CLI rodável, dataset de 10 cenários (cliente irritado, pedido inexistente, tentativa de fraude), README de 5 minutos com gif do agente atendendo.
Projeto 2 — RAG sobre documentação interna com avaliação de qualidade
RAG todo mundo faz. O que separa o seu é uma palavra: eval.
A diferença entre "RAG funcionou no meu computador" e "RAG está em produção" é o número que você consegue mostrar. E em 2026 esse número tem nome: Ragas. O framework é open-source e mede as quatro métricas que dão visibilidade completa: context precision, context recall, faithfulness e answer relevancy. Threshold prático: faithfulness e context precision acima de 0,85 para sistema customer-facing. Abaixo disso, está vazando alucinação.
Tema do projeto: RAG sobre a documentação da empresa onde você trabalha (ou docs do Laravel, Django, Postgres — algo que você conhece bem). Não precisa ser um corpus gigante. 50 documentos curados batem 5000 aleatórios.
from ragas import evaluate
from ragas.metrics import faithfulness, answer_relevancy, context_precision, context_recall
from datasets import Dataset
ds = Dataset.from_list([
{
"question": "Como faço cache de query no Eloquent?",
"ground_truth": "Use o método remember() do query builder...",
"contexts": [doc.page_content for doc in retriever.invoke(q)],
"answer": rag_chain.invoke(q),
}
# ... 49 outros
])
result = evaluate(ds, metrics=[
faithfulness, answer_relevancy, context_precision, context_recall,
])
print(result)
# {'faithfulness': 0.91, 'answer_relevancy': 0.87,
# 'context_precision': 0.84, 'context_recall': 0.79}
O que prova:
- Você entende que RAG sem eval é chute.
- Sabe construir um dataset de avaliação curado.
- Reconhece o trade-off entre recall e precision na retrieval.
Diferencial: rodar o mesmo eval contra dois embeddings diferentes (OpenAI vs Voyage, por exemplo) e mostrar qual ganhou em que métrica. Isso te coloca em outro nível de candidato.
Projeto 3 — Pipeline de eval contínuo no GitHub Actions
Agora a gente começa a peneirar.
A maioria dos candidatos não tem eval nenhum. Quem tem, roda na mão de vez em quando. Quem tem eval rodando no CI a cada PR está em outro patamar — e é exatamente o tipo de coisa que faz um engineering manager sênior pausar a leitura do GitHub e abrir a aba.
A ferramenta canônica pra isso é o Promptfoo, que tem GitHub Action oficial e foi adquirido pela OpenAI mantendo MIT license. Cinco linhas de YAML resolvem.
name: LLM eval
on:
pull_request:
paths: ["prompts/**", "src/agents/**"]
jobs:
eval:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- uses: promptfoo/promptfoo-action@v1
with:
config: 'promptfoo.config.yaml'
api-keys: |
ANTHROPIC_API_KEY=${{ secrets.ANTHROPIC_API_KEY }}
fail-on-threshold: 0.9
No promptfoo.config.yaml você define 20 a 30 casos com assertion (contains, llm-rubric, not-contains, regex). Quando alguém mexer no prompt, o PR roda os casos contra Claude/GPT/Gemini e falha se o score cair abaixo do threshold.
O que prova:
- Você trata prompt como código — versionado, testado, com gate de qualidade.
- Pensa em regressão antes de produção.
- Sabe que "funcionou na minha máquina" não escala em time.
Bônus killer: deixar o histórico de evals no Pages, gerando um gráfico de evolução do score por commit. Recrutador entra e vê uma curva. Curva fala mais que README.
Projeto 4 — Subagentes coordenados em task multi-passo
Aqui a gente sai do território "todo mundo já fez" e entra no que o mercado realmente está testando em 2026.
Tasks multi-passo (pesquisa, planejamento, execução, revisão) sobrecarregam um agente único. O context window enche, o modelo perde o fio, e o output vira papinha. A solução é decompor em subagentes especializados — cada um com seu system prompt, suas tools, seu modelo, seu context próprio. A Anthropic descreve o padrão direto na doc: cada subagent roda em seu próprio context window, com prompt customizado, acesso a tools específicas e permissões independentes.
Tema do projeto: assistente que recebe "construa um POC para X" e coordena três subagentes — researcher (pesquisa fontes oficiais), builder (gera código) e reviewer (audita o código contra um checklist de segurança e boas práticas).
Estrutura de arquivos:
.claude/agents/
├── researcher.md # tools: web_search, web_fetch — modelo: haiku
├── builder.md # tools: file_write, bash — modelo: sonnet
└── reviewer.md # tools: file_read, grep — modelo: sonnet
Cada arquivo tem frontmatter com tools, model, e um system prompt curto e cirúrgico. O orquestrador dispara em paralelo onde dá (researcher independente do builder) e sequencial onde precisa (reviewer só roda depois do builder).
O que prova:
- Você sabe quando um modelo só não dá conta.
- Entende o trade-off entre context isolado (limpa, mas perde co-pensamento) e contexto compartilhado (acopla, mas integra).
- Sabe alocar Haiku pra task barata e Sonnet pra task que exige raciocínio — economia direta de custo.
Diferencial pesado: medir o tempo total de uma task de ponta a ponta com 1 agente vs com 3 subagentes paralelos, e mostrar o delta. Número fechado é argumento.
Projeto 5 — Harness em produção com observabilidade
Esse é o projeto-filtro. Se você só faz os quatro anteriores, é um candidato decente. Se faz esse também, é um candidato raro.
"Harness" é o termo que descreve a infraestrutura ao redor do modelo: prompt management, retry, cache, fallback, eval online, logging estruturado, métricas de custo, alerta de regressão. É o que separa demo de produto. E em 2026 isso parou de ser opcional — observabilidade de agente virou requisito básico de produção, com plataformas como Langfuse, LangSmith e Helicone disputando o espaço.
Tema do projeto: pegue um dos projetos anteriores (o agente de suporte é o ideal) e coloque uma camada de observabilidade séria em volta. O Claude Agent SDK expõe três sinais OpenTelemetry independentes (métricas, logs e events) com toggles próprios pra cada um. Você conecta isso ao Langfuse (open source, self-hostável) ou SigNoz, e tem visibilidade real.
export OTEL_EXPORTER_OTLP_ENDPOINT="https://cloud.langfuse.com/api/public/otel"
export OTEL_EXPORTER_OTLP_HEADERS="Authorization=Basic <token>"
export CLAUDE_CODE_ENABLE_TELEMETRY=1
A partir daí: cada chamada de tool, cada token gasto, cada latência de retrieval vira span. Você monta dashboards de:
- Custo médio por sessão de usuário.
- Latência p95 por tipo de tool.
- Taxa de retry / fallback.
- Distribuição de razões de parada (
end_turn,tool_use,max_tokens).
E em cima disso, você liga eval online: 1 a cada 50 respostas vai pro Ragas, gerando um score contínuo de faithfulness em produção. Quando o score cai 5%, alerta.
O que prova:
- Você opera sistema com IA, não só prototipa.
- Entende que LLM em produção é caro e que medir custo é parte da engenharia, não do financeiro.
- Sabe que prompt drift e modelo drift são reais — e tem como detectar.
Esse é exatamente o tipo de stack que destrinchamos ao vivo no Harness Engineering com Claude Code: do loop autônomo à observabilidade, com código rodando e decisão de arquitetura na mesa.
Como descrever cada projeto em 3 linhas no LinkedIn
Recrutador não lê parágrafo. Lê bullet com número.
Padrão que funciona:
Construí [O QUÊ TÉCNICO].
Mediu [MÉTRICA NUMÉRICA + COMPARAÇÃO].
Resolveu [PROBLEMA REAL DE PRODUTO].
Aplicado aos cinco:
- Projeto 1. Construí agente de suporte com tool use orquestrando 5 APIs internas, com retry e fallback. Mediu 92% de acerto na escolha de tool em 30 cenários. Resolveu volume de FAQ repetitiva em demo de e-commerce.
- Projeto 2. Construí pipeline RAG sobre docs internas com chunking, reranking e eval em Ragas. Mediu 0.91 de faithfulness em dataset curado de 50 perguntas, ganhando 12% sobre baseline GPT-4o. Resolveu busca interna que retornava docs irrelevantes.
- Projeto 3. Implementei eval contínuo com Promptfoo no GitHub Actions, 30 casos por PR. Mediu quality gate de 0.9 obrigatório para merge, capturando 4 regressões em 2 meses. Resolveu deploy de mudança de prompt sem validação.
- Projeto 4. Construí orquestração com 3 subagentes (research, build, review) em Claude Code SDK. Mediu redução de 12min para 4min em task de POC ponta a ponta, com paralelismo e alocação Haiku/Sonnet. Resolveu agente único que estourava context em task multi-passo.
- Projeto 5. Operei harness em produção sobre Claude com observabilidade Langfuse e eval online via Ragas. Mediu p95 de 1.8s, custo médio $0.04/sessão, e alerta automático de drift de faithfulness. Resolveu falta de visibilidade de qualidade e custo em sistema com LLM.
Cinco bullets desses no perfil, repositório linkado, README de 5 minutos com gif. Acabou.
FAQ rápido
"Mas eu não tenho dados reais, vou usar dado fake. Ainda conta?" Conta, se você for honesto. Coloque no README: "dataset sintético de 50 casos representando cenário X". O recrutador respeita método. O que ele despreza é número inventado sem dataset.
"Preciso fazer os 5 ou posso parar nos 3 primeiros?" Três primeiros te tiram do filtro automático. Quatro te colocam em entrevista. Cinco te dão proposta. Sua decisão.
"Esses projetos rodam local ou precisam de cloud?" Rodam local. Apenas o projeto 5 fica mais bonito com Langfuse cloud (free tier resolve) ou SigNoz self-hosted (Docker compose em 10 minutos).
"E o custo de API? Sou estudante." Os 5 projetos juntos dão pra fazer com menos de $30 de crédito, se você cachear desenvolvimento e usar Haiku para tasks baratas. Anthropic e OpenAI dão crédito inicial para conta nova.
Conclusão
A diferença entre dev curioso de IA e AI engineer empregável não é mestrado, não é paper, não é fine-tuning. É ter cinco projetos pequenos que respondem cinco perguntas concretas: você sabe orquestrar tools? Você sabe medir RAG? Você sabe colocar eval no CI? Você sabe decompor task em subagentes? Você sabe operar isso em produção?
Cada um leva 1 a 3 fins de semana. Cada um cabe em 3 linhas no LinkedIn. Cada um responde uma pergunta que o recrutador de 2026 está fazendo todo dia.
E se quiser ver o quinto projeto destrinchado de ponta a ponta, do harness ao trace no dashboard, é o que a gente faz ao vivo no Harness Engineering com Claude Code.
O próximo passo é abrir o terminal e começar pelo Projeto 1. Não pelo paper.

{AI Engineer} — apaixonado por Laravel, arquitetura de software e construir produtos com impacto. Compartilho aqui tutoriais, descobertas e reflexões sobre o dia a dia de engenharia.
Você também pode gostar
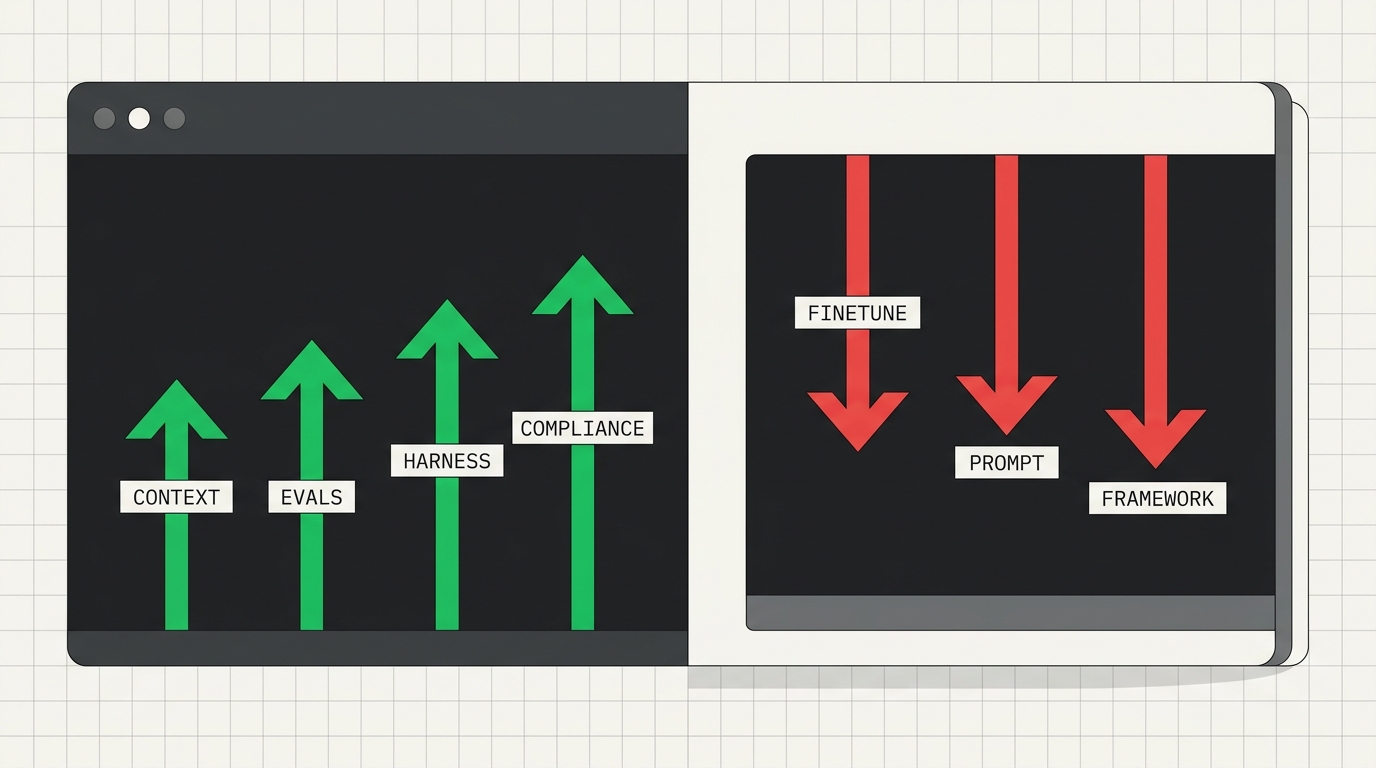
AI engineer no 2º semestre de 2026: o que o recrutador vai pedir
Li 200 vagas de AI engineer postadas em maio de 2026 e separei sinal de ruído: quatro skills que sobem (context engineering, evals, harness e compliance), três que perdem peso e um roteiro de 90 dias pra entrar na shortlist do segundo semestre.

Roadmap AI Engineer em 90 dias: do dev backend ao primeiro agente em produção
Caminho real de 13 semanas para dev backend experiente virar AI engineer aplicada. Tool use, harness próprio, RAG, memória, evals e um projeto fim-a-fim que cabe no portfólio. Sem refazer fundamentos, sem detour por framework da moda. Entregáveis por semana e foco no que recrutador olha de verdade.

AI Engineer no Brasil: as 6 senioridades que o mercado realmente paga (e o que cada uma entrega)
RH pede 5 anos em IA agêntica para um campo que não tem 5 anos. A escala real é outra. Mapa de 6 senioridades de AI Engineer no Brasil em 2026 com entregáveis por nível, faixa salarial e o critério de promoção que recrutador respeita.

Quanto ganha um Engenheiro de IA no Brasil em 2026? Salário real por nível e stack
Faixas reais de salário de Engenheiro de IA no Brasil em 2026: CLT por nível, PJ no Brasil, contrato gringo via Deel, diferença por stack e como negociar com fonte na mão.
