Engenheiro de IA em 2026: o que faz, e por que não é só usar ChatGPT no trabalho
Em 2024, "Engenheiro de IA" era cargo inventado por recrutador no LinkedIn. Tinha post viral toda semana dizendo que era a próxima profissão do futuro. Em 2026, é o sênior mais disputado dos Estados Unidos.
A diferença é que agora ele entrega coisa de verdade. Não é prompt mágico. Não é "automatizar o trabalho com ChatGPT". É construir, operar e manter sistemas que rodam LLMs em produção, com eval, observability, custo controlado e produto em cima.
Neste post você vai entender, na prática, o que faz um Engenheiro de IA em 2026 — sem o hype de recrutador. Diferença para ML Engineer e Data Scientist, as 5 entregas que aparecem em qualquer JD sênior, o stack típico do dia a dia e por que a maioria dos AI Engineers veio de backend, não de Data Science.
TL;DR
- O que é: dev que constrói produtos sobre LLMs — do protótipo ao serviço em produção.
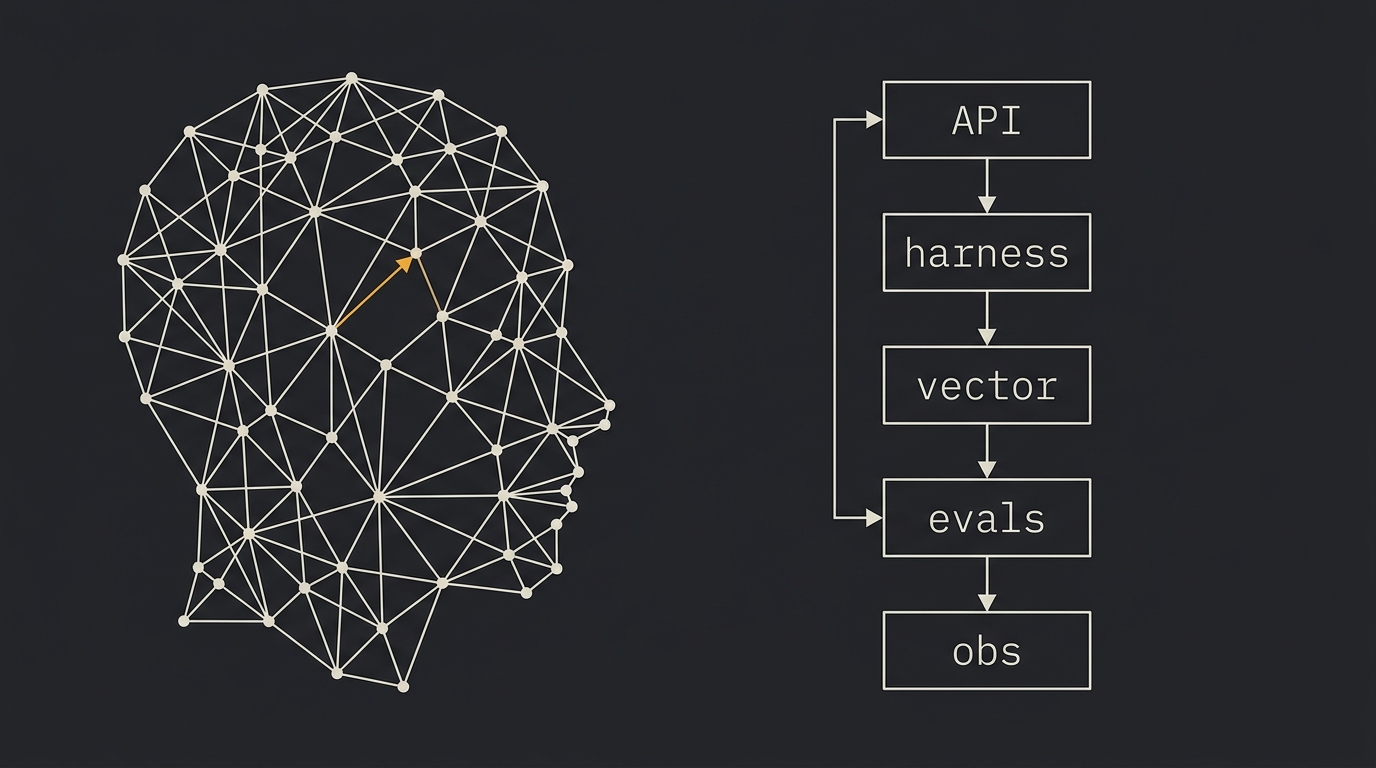
- Stack típico em 2026: LLM API + harness/orquestração + vector store + evals + observability.
- Mercado: #1 cargo que mais cresce nos EUA segundo o LinkedIn Jobs on the Rise 2026. Mediana de 3,7 anos de experiência prévia. Salário sênior US partindo de US$ 200k base.
- Origem mais comum: Software Engineer, Data Scientist, Full Stack — nessa ordem.
De cargo inventado pelo LinkedIn ao mais disputado de 2026
A briga sobre se "AI Engineer" era cargo de verdade ou marketing terminou. Os números resolveram.
O relatório LinkedIn Jobs on the Rise 2026 colocou Engenheiro de IA como o cargo que mais cresce nos Estados Unidos. Entre 2023 e 2025 o LinkedIn somou 639 mil vagas relacionadas a IA no país, das quais cerca de 75 mil eram especificamente para AI Engineer. A demanda cresceu 74% ano a ano em 2026, contra 38% para ML Engineer e 12% para Data Scientist.
Salário sênior nos EUA parte de US$ 200k base e vai até US$ 312k, com pacotes em big techs cruzando US$ 900k de total comp. No Brasil ainda é mais discreto, mas a curva está subindo no mesmo ritmo. Empresas que não fecham os US$ 200k base nos EUA estão levando 114 dias em média para preencher a vaga.
Não é hype. É escassez real de gente que sabe o que está fazendo.
AI Engineer não é ML Engineer e não é Data Scientist
A confusão entre os três cargos é a maior fonte de candidatura no lugar errado.
Resumo grosseiro mas útil:
- Data Scientist responde perguntas de negócio. Roda experimento, faz forecast, comunica para stakeholder. Saída do trabalho dele é insight.
- ML Engineer treina, deploya e opera modelos próprios em produção. Saída é o modelo servindo tráfego.
- AI Engineer embute LLM, RAG, agentes e tools dentro de aplicação. Saída é uma feature em produção que usa IA.
A análise da AI Shipping Labs sobre 889 JDs publicadas em janeiro de 2026 deixa explícito: 70% das vagas de AI Engineer são "AI-First" — trabalho direto com LLMs, RAG e agentes — e menos de 2% pedem ML clássico (treinar modelo, escolher algoritmo, ajustar hiperparâmetro).
Quem aplica para AI Engineer pensando que vai treinar modelo está candidato à vaga errada. Quem aplica para ML Engineer pensando que vai construir RAG, mesma coisa.
As 5 entregas que aparecem em qualquer JD sênior de AI Engineer
Olhando as JDs reais, sempre as mesmas cinco coisas:
1. Aplicação end-to-end alimentada por LLM. Do protótipo no notebook até o serviço com SLA. Backend, infra, fila, retry, observabilidade. Exatamente o trabalho de um SRE/backend dev, com a diferença de que parte da lógica é probabilística.
2. RAG sobre dados proprietários. Ingestão de documentos, chunking, embeddings, vector store, retrieval, reranking, montagem de contexto. Não é "plugar Pinecone e rezar". É decidir qual chunk size usa, qual reranker entra, como cita fonte, como mede recall.
3. Pipelines de avaliação e observability. Esse aqui separa o sênior do resto. Trace de cada chamada, eval automatizada, regressão antes de cada deploy, dashboard de drift. "Deu boa" não é métrica. Saber que o pipeline alucinou em 8% dos casos da última semana e cair pra 2% antes da próxima sprint é métrica.
4. Operação de APIs de modelos externos. Custo por requisição, latência p95, fallback entre provedores, rate limit, cache, retries com backoff. Quem nunca operou serviço externo em produção apanha aqui.
5. Workflows multi-step com agentes. Tools, function calling, orquestração de passos, guardrails, recuperação de erro no meio do loop. É onde harness aparece — o scaffolding que envolve o modelo e dá controle ao engenheiro.
Essas cinco entregas são o dia a dia. Não tem prompt mágico em nenhuma.
O stack típico do AI Engineer em 2026
Da análise das 889 JDs, as skills mais pedidas em ordem:
| Skill | % das JDs |
|---|---|
| Python | 82,5% |
| AWS | 40,1% |
| RAG | 35,9% |
| Docker | 31,0% |
| CI/CD | 29,3% |
| Prompt Engineering | 29,1% |
| Kubernetes | 29,1% |
| LLM Integration | 25,4% |
| TypeScript | 23,4% |
| PyTorch | 22,0% |
Note o que essa tabela está dizendo: quatro das dez skills mais pedidas são puramente de engenharia de software (AWS, Docker, CI/CD, Kubernetes). Apenas duas são especificamente de IA (RAG, Prompt Engineering). PyTorch aparece, mas com peso menor que TypeScript.
Em 2026 o stack canônico de um time de AI Engineering tem cinco camadas:
- Modelo: LLM via API (Claude, GPT, Gemini), com fallback entre provedores. Fine-tuning ainda existe, mas é minoria das vagas.
- Harness: o scaffolding em volta do modelo. Loop de execução, ferramentas, contexto, memória, guardrails. A OpenAI formalizou o termo "harness engineering" em fevereiro de 2026, descrevendo como construíram seu próprio harness para rodar Codex em escala. Ryan Lopopolo, da OpenAI, resumiu: "construímos o Harness para oferecer um modo confiável de executar workloads em escala".
- Memória e retrieval: vector store (Pinecone, pgvector, Qdrant) + camada que decide quando puxar do vector e quando puxar da memória do agente.
- Evals: Braintrust (usado por Stripe, Notion, Dropbox, Perplexity), Langfuse (open-source), Promptfoo, RAGAS, DeepEval. Pelo menos um deles está em qualquer time sério.
- Observability: trace por requisição, custo, latência, taxa de erro, drift de qualidade. LangSmith, Langfuse, Phoenix, AgentOps.
Quem só sabe a primeira camada (chamar a API do modelo) é júnior. Sênior domina as cinco.
Por que a maioria dos AI Engineers veio de backend, não de Data Science
O LinkedIn Jobs on the Rise 2026 listou as três principais origens dos AI Engineers atuais: Software Engineer, Data Scientist e Full Stack Engineer — nessa ordem.
Isso surpreende quem achava que IA era território de PhD. Mas faz sentido quando você olha as cinco entregas acima. Quatro delas são, no fim, problemas de engenharia de sistemas distribuídos: deploy confiável, latência, retry, observability, custo. O backend dev já apanhou nessas dores antes. Falta aprender prompt design, RAG, harness e eval — semanas de estudo, não anos.
O Data Scientist tem a vantagem do raciocínio sobre dado e métrica, mas precisa aprender o lado de engenharia: CI/CD, container, infra, observability. Por isso a transição mais comum hoje é justamente DS → AI Engineer.
A mediana de experiência prévia é de 3,7 anos. Não é cargo de júnior recém-formado. É cargo de pleno virando sênior em uma especialização nova.
Como é o dia 1 num projeto real
Para tirar a poeira da abstração, dia 1 num projeto real costuma ser assim:
O ticket que cai na sua mesa não é "treine um modelo". É algo do tipo: "esse pipeline de RAG está alucinando em 8% dos casos do dataset de regressão. Investigue, baixe pra menos de 2%, sem aumentar custo de inferência."
Você abre o dashboard de tracing, filtra os casos que falharam, reproduz cada um. Descobre que três quartos dos erros vêm de retrieval ruim (chunk errado entrou no contexto), não de problema de prompt. Ajusta o reranker, reescreve dois prompts, adiciona um tool de validação no harness. Roda a suíte de evals offline, valida que o número caiu para 1,4%. Faz o deploy canário em 5% do tráfego, monitora por 24h, promove se a métrica online bater a offline.
Esse dia 1 é mais parecido com SRE que com pesquisador. E é exatamente isso que o mercado está pagando US$ 200k+ para encontrar — alguém que sabe construir, medir e operar um harness próprio sobre LLM, com a disciplina de quem já operou serviço crítico em produção. É esse pipeline inteiro — harness, evals, tracing, decisão de arquitetura — que vamos abrir ao vivo no Harness Engineering com Claude Code, do loop autônomo até o agente em produção.
Armadilhas do mercado e como ler uma JD
Nem toda vaga "AI Engineer" é vaga de AI Engineer. Como o cargo virou label quente, recrutador joga ele em qualquer coisa.
Sinais de vaga ruim:
- Pede "criar prompts e automações com ChatGPT" e nada de evals, observability ou produção. É vaga de prompt engineer com salário disfarçado.
- Não menciona métricas, custo, latência, regressão. Provavelmente é PowerPoint Engineer.
- Pede 5 anos de experiência em LLM (que tem 3 anos de existência prática).
- Faixa salarial junior para responsabilidades de sênior. Aproveitando o hype.
Sinais de vaga boa:
- Cita stack de eval (Braintrust, Langfuse, Promptfoo) ou observability (LangSmith, Phoenix).
- Menciona "production", "RAG", "agentes", "tools", "harness", "guardrails".
- Pede experiência com infra (AWS, Docker, K8s, CI/CD).
- Descreve o problema de negócio, não só a tecnologia.
Quando a JD cita as cinco entregas — end-to-end, RAG, eval, operação de API, agentes — está claro que tem alguém sênior do outro lado escrevendo. Vale entrar.
FAQ rápido
Preciso de mestrado ou PhD? Não. Para a maioria das vagas, conhecimento de produção e arquitetura pesa muito mais que paper. PhD ajuda em research labs, não em time de produto.
Tenho que aprender PyTorch? Bom de saber, mas só aparece em 22% das JDs. Se você não vai treinar modelo (e a maioria não vai), priorize Python, RAG, evals e observability.
LangChain ou direto na API? As duas. Para protótipo rápido, LangChain ou similar acelera. Para produção séria, muita gente caí no SDK direto do provedor para ter controle de tracing, custo e fallback. Saber escolher é o diferencial.
Vale migrar de Data Science para AI Engineer? Em 2026, é a transição mais popular nos EUA segundo o LinkedIn. A base estatística e Python transferem. O que precisa adicionar é engenharia de software de verdade: CI/CD, container, observability, retry, custo. É absorvível em meses, não anos.
Conclusão
Engenheiro de IA em 2026 não é o cargo que o LinkedIn imaginou em 2024. É um papel técnico bem definido, com cinco entregas claras e um stack canônico: LLM API, harness, vector store, evals, observability. Cargo de pleno virando sênior, na faixa salarial mais agressiva do mercado, e ainda escasso de gente boa.
A parte do trabalho que mais separa o profissional do hype é exatamente o harness — o scaffolding em volta do modelo onde mora a engenharia de verdade. Quem domina harness deixa de ser "o cara que usa ChatGPT no trabalho" e passa a ser quem coloca IA em produção sem o time acordar de madrugada. Se você quer ver isso aplicado num projeto real, com loop autônomo, evals e agente de fato em produção, é o que vamos construir ao vivo no Harness Engineering com Claude Code.
A próxima onda do dev sênior não é virar pesquisador de IA. É construir o harness por trás do produto.

{AI Engineer} — apaixonado por Laravel, arquitetura de software e construir produtos com impacto. Compartilho aqui tutoriais, descobertas e reflexões sobre o dia a dia de engenharia.
Você também pode gostar
Engenheiro de IA: o que faz no dia a dia em 2026
O que um engenheiro de IA realmente faz no dia a dia em 2026: a rotina real, o stack que ele toca, o que NÃO faz e como entrar na área vindo de dev backend. Spoiler: não é treinar modelo o dia inteiro.
Desenvolvedor de IA vs Engenheiro de IA: 7 diferenças que importam
Desenvolvedor de IA e engenheiro de IA não são dois nomes pra mesma vaga. Comparativo direto de escopo, skills, salário e carreira, e onde o dev de produto cruza a linha.
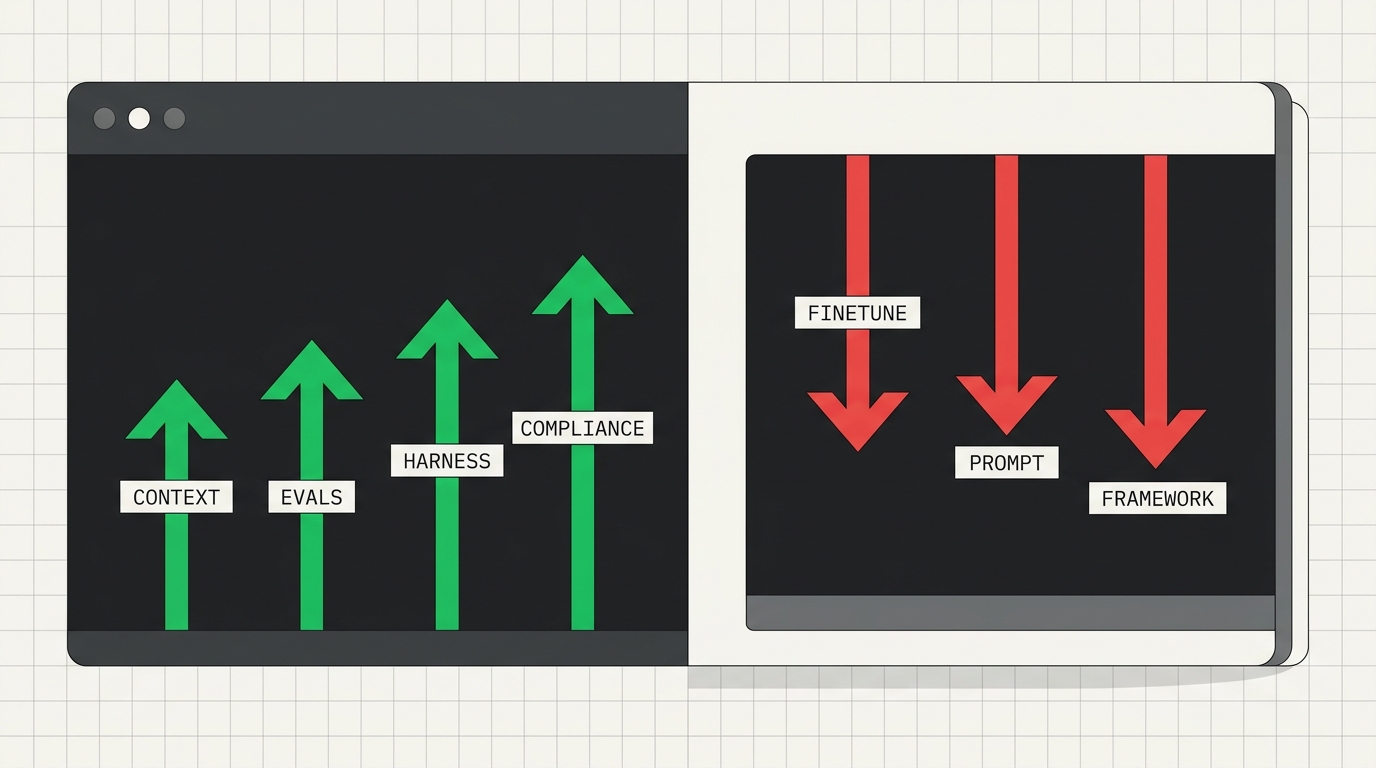
AI engineer no 2º semestre de 2026: o que o recrutador vai pedir
Li 200 vagas de AI engineer postadas em maio de 2026 e separei sinal de ruído: quatro skills que sobem (context engineering, evals, harness e compliance), três que perdem peso e um roteiro de 90 dias pra entrar na shortlist do segundo semestre.

Quanto ganha um Engenheiro de IA no Brasil em 2026? Salário real por nível e stack
Faixas reais de salário de Engenheiro de IA no Brasil em 2026: CLT por nível, PJ no Brasil, contrato gringo via Deel, diferença por stack e como negociar com fonte na mão.
