Tutoriais
Guias práticos passo a passo sobre Laravel, Filament e ecossistema PHP.
Como construir um agente de bolão da Copa 2026 no WhatsApp com Evolution API e N8N
Como construir um agente de IA que gerencia o bolão da Copa 2026 no WhatsApp — com Evolution API, N8N e Google Sheets. Guardrails, engenharia de prompt e de contexto na prática, com o flow real na mesa.

CLAUDE.md: as 4 cláusulas do Karpathy e a 5ª que a comunidade adicionou
O post mais votado da semana no r/ClaudeAI partiu das 4 cláusulas de CLAUDE.md sugeridas pelo Karpathy e somou uma 5ª, a que mais muda o comportamento do agente. Um guia prático pra escrever um claude.md que o Claude Code realmente obedece.
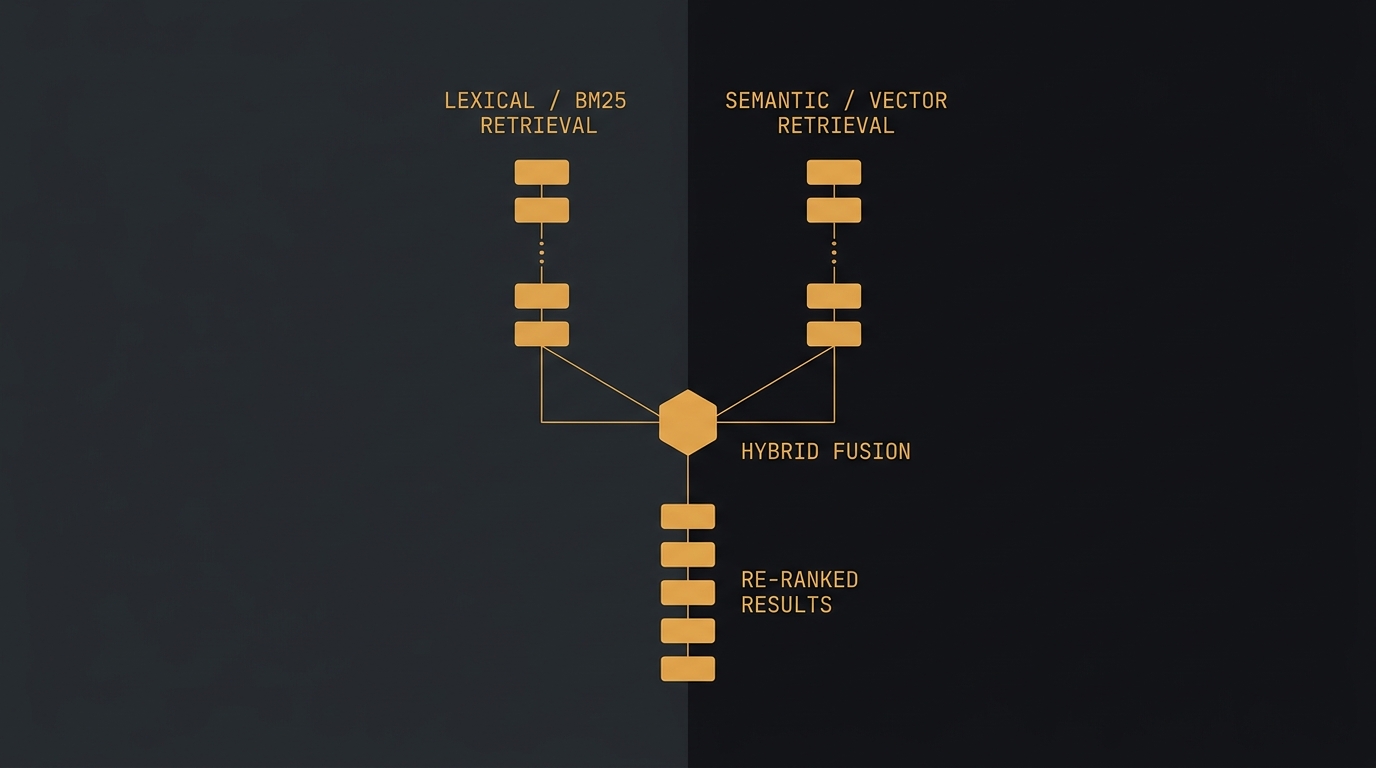
RAG híbrido na prática: BM25, embeddings e reranker
Embedding sozinho erra mais do que você imagina. Veja como combinar busca lexical (BM25), busca semântica e um reranker cross-encoder para subir a qualidade do RAG em produção, com código em Python e LangChain.

Como criar evals para agentes de IA com LLM-as-a-judge
Monte um pipeline de avaliação de agentes de IA com LLM-as-a-judge: dataset de falhas reais, rubricas, scoring com barra de erro e gate no CI. Sem eval, deploy é no escuro.

Como criar um bot no Slack com Claude: um agente de dados no seu workspace
Tutorial de um bot de Slack que responde perguntas sobre seus dados com Claude, baseado no cookbook da Anthropic. Do app_mention ao agente em produção.

Como criar um servidor MCP do zero: tools, resources e prompts, do stdio ao HTTP
Tutorial mão na massa pra escrever um servidor MCP em Python do zero — uma tool, um resource e um prompt — rodando em stdio e HTTP, plugado no Claude.

Agent improvement loop: o ciclo que faz o agente melhorar o próprio código
Como montar um loop de auto-melhoria de agente — gera, testa, avalia, corrige — inspirado no agent improvement loop do Agents SDK da OpenAI. Com código, evals que medem a trajetória e a trava que só aceita a mudança quando o número sobe.
Claude Code em monorepo: como não estourar contexto em base grande
Estratégias para usar Claude Code em monorepo e large codebase sem estourar o context window: escopo de sessão, CLAUDE.md em camadas, code intelligence e subagentes.

Claude Code hooks, slash commands e MCP: os três recursos que mudam seu fluxo
Guia prático dos três pontos de extensão do Claude Code — hooks, slash commands e MCP. Os arquivos de config exatos pra transformar o agente de autocomplete em parte do seu fluxo de engenharia.
Codex CLI: como usar goals para guiar o agente sem microgerenciar
O recurso /goal do Codex CLI faz o agente da OpenAI perseguir um objetivo sozinho. Aprenda a escrever um goal como contrato — com escopo, verificação e condição de parada — em vez de um prompt com esperança embutida.
Sistemas multiagentes: arquitetura e orquestração assíncrona na prática
O que são sistemas multiagentes, quando vale dividir o trabalho em vários agentes e como orquestrar de forma assíncrona com asyncio. Arquitetura orquestrador-worker, o padrão de produção da Anthropic e quando NÃO dividir.
Ferramentas de engenharia de contexto que eu uso em produção
Lista prática e opinativa das ferramentas de engenharia de contexto que seguram um agente em produção: gestão de janela, compressão, recuperação e observabilidade. Com APIs nativas, números reais e o que dá errado.
