Code Review com IA sem virar carimbador: padrões que pegam bug e ignoram estilo

Todo PR abre, o bot comenta a mesma coisa.
"Considere adicionar testes." "Pode ser refatorado em um método auxiliar." "Verifique se essa variável precisa ser pública." Em dois dias o time aprendeu o reflexo: rolar até o fim, ignorar o avatar do bot, aprovar. Em uma semana, alguém mutou o canal do GitHub no Slack. Em um mês o bot virou enfeite caro — paga API, gera ruído, não pega o bug que importou.
Code review com IA não é um problema de modelo. É um problema de filtro. O modelo certo, com o prompt errado, comenta em tudo. O mesmo modelo, com um harness que valida confiança antes de postar, pega regressão de verdade e some quando não tem nada útil a dizer. A diferença é assertividade — quanto o bot está disposto a calar a boca.
Neste post vamos montar um setup de code review automatizado com Claude rodando no GitHub Actions, num projeto Laravel. Prompt com três camadas de contexto, ferramentas que executam testes e abrem commits anteriores, scoring de confiança 0–100 com threshold de 80 e workflow YAML pronto para colar. No final, um jeito honesto de medir precision e recall do bot contra os comentários de humanos do time.
TL;DR
- O que é: pipeline de code review com IA no GitHub Actions que filtra por confiança antes de comentar.
- Stack/Modelos: GitHub Actions, anthropics/claude-code-action@v1, Claude Sonnet 4.6 (ou Opus 4.7 para revisões críticas), Laravel 11+, PHPUnit, Pint, Larastan.
- Custo/Acesso: chave Anthropic paga; ~$0.05–0.30 por PR médio no Sonnet, ~3–5x mais no Opus 4.7.
- Link útil: docs oficiais de Claude Code GitHub Actions e o plugin /code-review (referência do prompt).
O fail-mode do code review com IA hoje
O comportamento padrão de um LLM revisando código é o pior possível: ele quer ser útil. Você pede pra ele revisar um diff e ele vai achar algo pra falar. Em todo diff. Mesmo que o diff seja trocar a versão de um pacote.
Isso aparece nos benchmarks. O time do Augment rodou um benchmark com 7 ferramentas em 50 PRs reais de Sentry, Grafana, Cal.com, Discourse e Keycloak. Os números:
| Ferramenta | Precision | Recall | F1 |
|---|---|---|---|
| Augment | 65% | 55% | 59% |
| Cursor Bugbot | 60% | 41% | 49% |
| Greptile | 45% | 45% | 45% |
| Codex Code Review | 68% | 29% | 41% |
| CodeRabbit | 36% | 43% | 39% |
| Claude Code (raw) | 23% | 51% | 31% |
| GitHub Copilot | 20% | 34% | 25% |
Olha o Claude Code (raw) ali em baixo — 23% de precisão. Três em cada quatro comentários do modelo direto, sem harness, não viram mudança de código. É o mesmo modelo que aparece no topo quando alguém investe em filtro. A capacidade está no modelo. A assertividade está em volta dele.
Como o Augment resumiu: "alta precisão mantém o dev engajado; alto recall é o que torna a ferramenta genuinamente útil." O Qodo foi mais direto no anúncio do 2.0: "precisão pode ser ajustada com filtro e priorização depois que as issues são encontradas. Recall não pode." Traduzindo pra dor de produção: peça pro modelo achar tudo, depois jogue fora 80% antes de comentar.
O dev que silencia o bot não está errado. Ele está reagindo a um sinal real: o ruído passou do limite. Para o bot voltar a ser lido, ele precisa comentar menos.
Anatomia de um prompt de code review que não vira carimbo
Três camadas de contexto, nessa ordem:
1. Contexto do PR. Título, descrição, issue linkada, lista de arquivos alterados. Sem isso o modelo revisa um diff sem entender o que o dev se propôs a fazer. Resultado: ele reclama de "responsabilidades muito amplas" num PR cujo título é "split monolítico do controller de orders".
2. Contexto do diff. Hunk a hunk, com nome de arquivo, número de linha e ±10 linhas de contexto em volta. Não jogue o diff inteiro como string única — o modelo perde a referência de qual arquivo está olhando depois de 200 linhas.
3. Contexto do repositório. CLAUDE.md na raiz com convenções do projeto, ADRs relevantes em docs/adr/, e um sinal sobre como o time pensa code review (ex: "valorizamos PRs pequenos, não comentamos em estilo, linter pega isso").
Em cima dessas camadas, duas listas explícitas no prompt: o que pegar e o que ignorar. A Anthropic publicou o prompt do plugin /code-review oficial e a lista do "DO NOT FLAG" é a parte mais importante. Adaptada para PHP/Laravel:
FLAG SOMENTE ISSUES DE ALTO SINAL:
- código que não vai compilar (syntax, classe inexistente, namespace errado)
- código que vai produzir resultado errado (erro de lógica claro, off-by-one,
comparação invertida, esquece break em match/switch)
- violação inequívoca do CLAUDE.md (cite a regra exata)
- regressão de comportamento (chamada removida, contrato quebrado, migração
que invalida dados existentes)
- problema de segurança (SQL injection, mass assignment não controlado,
validação faltando em input do usuário)
NÃO FLAGGAR:
- estilo de código ou formatação (Pint resolve)
- nomenclatura subjetiva ("acho que getUser seria mais claro")
- issues que já existiam antes do PR
- nitpicks pedantes ("essa string poderia ser uma constante")
- coisas que parecem bug mas estão corretas dado o contexto
- sugestões de refatoração sem ganho mensurável
- código com lint-ignore explícito
- "considere adicionar um teste" sem indicar o caso de teste específico
A última linha é a mais cara. "Considere adicionar testes" é o comentário mais comum de bot ruim e o mais inútil. Se o modelo não consegue dizer qual caso de teste está faltando e por quê, ele não tem nada a dizer.
Em cima disso, scoring. Cada finding sai com um número de 0 a 100. A escala que o plugin oficial usa:
- 0: falso positivo
- 25: talvez seja real
- 50: real, mas menor
- 75: real e importante
- 100: tenho certeza absoluta
E aí o filtro: só comenta no PR o que está em 80 ou acima. Tudo abaixo fica no log do job — você pode revisar depois pra calibrar o prompt, mas o dev não vê.
Tools que mudam o jogo (do prompt-only ao agentic)
Aqui é onde o setup deixa de ser "manda diff, recebe parecer" e vira agente.
Prompt-only tem um teto. O modelo lê o diff, lê o CLAUDE.md, faz a melhor inferência possível. Mas ele não sabe se o teste passa. Não sabe se essa função foi recém-extraída de um lugar maior. Não sabe se essa decisão de arquitetura foi tomada na ADR-007 com motivo registrado.
Agentic muda isso. Você dá ferramentas e ele decide quando usar:
- Rodar testes contra o branch do PR.
php artisan test --filterem cima dos arquivos alterados. Se o teste quebra, o modelo já tem evidência concreta — não inferência. Comentário vira: "linha 47 quebra o testeOrderControllerTest::test_creates_order_with_valid_payload, output do PHPUnit em anexo". - Abrir o commit anterior do arquivo.
git log -pno arquivo modificado. O modelo pega o contexto histórico: "essa função era chamada em mais 3 lugares antes do commit a3f9b2c, dois deles ainda existem noOrderServicee não foram atualizados". - Consultar ADR e CLAUDE.md.
grepemdocs/adr/. "ADR-007 estabelece que jobs devem ser idempotentes; oProcessRefundJobintroduzido aqui não verifica$this->batch()->cancelled()antes de chamar a gateway." - Executar linter e static analysis. Larastan, Pint. Não pra reportar (isso o CI já faz), mas pra suprimir comentários: se o problema já vai aparecer no Larastan, o bot não comenta.
O plugin oficial vai mais longe: roda quatro agentes em paralelo, cada um com foco específico (compliance com CLAUDE.md em dois agentes redundantes, detecção de bug olhando só o diff, análise de lógica e segurança), e depois um scorer independente avalia cada finding antes de filtrar. É overkill pra um time de 5 devs e essencial pra um repo de 200 contribuidores. Comece com um agente e o filtro de confiança; expanda quando a precisão estagnar.
Filtro de assertividade na prática
A separação importante: quem acha não é quem filtra. O agente de revisão é instruído a achar tudo — incluindo coisas duvidosas. Depois um judge separado, com prompt diferente, vê cada finding e dá um score. Isso evita o autoengano clássico do modelo, que filtra sozinho e nem te conta o que descartou.
Schema da saída do reviewer:
{
"findings": [
{
"file": "app/Http/Controllers/OrderController.php",
"line": 47,
"severity": "bug",
"summary": "Race condition em criação de pedido sem lock",
"evidence": "OrderController::store chama Order::create e depois Inventory::decrement sem transação. Dois requests simultâneos podem decrementar o mesmo item duas vezes.",
"suggested_fix": "Envolver em DB::transaction e usar lockForUpdate no item.",
"confidence": 90
},
{
"file": "app/Http/Controllers/OrderController.php",
"line": 12,
"severity": "style",
"summary": "Variável poderia ser readonly",
"evidence": "Propriedade $repository nunca é reatribuída.",
"suggested_fix": "Adicionar readonly.",
"confidence": 35
}
]
}
Threshold 80 corta o segundo finding antes de chegar no PR. Sobra um comentário, com evidência específica, citando arquivo e linha, propondo fix concreto. Esse comentário vai ser lido.
Setup completo no GitHub Actions com Laravel + Claude
Workflow pra colar em .github/workflows/claude-review.yml. Disparo em todo pull_request aberto ou atualizado, com actions:read pra ler resultados de CI já existentes:
name: Claude Code Review
on:
pull_request:
types: [opened, synchronize, reopened]
jobs:
review:
if: github.event.pull_request.draft == false
runs-on: ubuntu-latest
permissions:
contents: read
pull-requests: write
issues: write
id-token: write
actions: read
steps:
- name: Checkout
uses: actions/checkout@v6
with:
fetch-depth: 0
- name: Setup PHP
uses: shivammathur/setup-php@v2
with:
php-version: '8.3'
tools: composer:v2
- name: Install dependencies
run: composer install --no-interaction --prefer-dist --no-progress
- name: Run Claude Code Review
uses: anthropics/claude-code-action@v1
with:
anthropic_api_key: ${{ secrets.ANTHROPIC_API_KEY }}
prompt: |
Você está revisando o PR #${{ github.event.pull_request.number }}.
Título: ${{ github.event.pull_request.title }}
Siga estritamente as regras de FLAG / NÃO FLAGGAR descritas no
CLAUDE.md deste repositório. Use as ferramentas disponíveis para
rodar testes e consultar ADRs antes de comentar. Só comente em
findings com confidence >= 80.
claude_args: |
--model claude-sonnet-4-6
--max-turns 15
--allowedTools "Bash(php artisan test:*),Bash(./vendor/bin/pint --test),Bash(./vendor/bin/phpstan analyse:*),Bash(git log:*),Bash(git diff:*),Read,Grep"
--append-system-prompt "Você é um reviewer rigoroso. Sua reputação cai mais por falso positivo do que por falso negativo. Quando em dúvida, não comente."
Algumas decisões dentro desse YAML que não são óbvias:
fetch-depth: 0— sem o histórico completo, o agente não consegue rodargit logno arquivo pra entender contexto.if: github.event.pull_request.draft == false— draft é rascunho, dev não quer review ainda. Bot que comenta em draft é o primeiro a ser silenciado.--max-turns 15— limite pra evitar que o agente entre em loop rodando teste atrás de teste. 15 turnos é o suficiente pra revisar a maioria dos PRs sem explodir custo.--allowedTools— lista explícita do que o agente pode executar.php artisan test:*deixa rodar qualquer filtro, mas não deixa rodartinkeroumigrate:fresh. Listas pequenas são mais seguras que*.--append-system-prompt— a frase sobre reputação é deliberada. LLM tende a ser educado e útil; aqui você dá permissão pra ele calar a boca.
Para PRs críticos (mudança em billing, segurança, migrações destrutivas), troque o modelo para claude-opus-4-7 em um job separado disparado por label. Opus 4.7 é 3–5x mais caro, mas em revisão de código a diferença em recall é notável — e os PRs onde recall importa são exatamente os que você quer que ele veja.
Como medir precision e recall do bot vs humano
Sem métrica você não calibra. E sem calibração o bot só piora com o tempo, porque você nunca sabe se o threshold de 80 está apertado demais ou frouxo demais.
Métrica honesta, baseada no que o time do CodeAnt fez em 200k PRs reais: um comentário do bot só é considerado "verdadeiro positivo" se o dev mudou o código em resposta a ele dentro daquele PR. Se o comentário foi ignorado e a linha continuou igual no merge, é falso positivo.
Script simples, em cron semanal, que consome a API do GitHub:
// Para cada PR mergeado na semana:
foreach ($pullRequests as $pr) {
foreach ($pr->reviewComments()->whereAuthor('claude-bot') as $comment) {
$lineAtMerge = $pr->fileAtMerge($comment->file)->line($comment->line);
$lineAtComment = $comment->originalLine;
$acted = $lineAtMerge !== $lineAtComment;
Metric::record([
'pr' => $pr->number,
'comment_id' => $comment->id,
'acted' => $acted,
'confidence' => $comment->extra['confidence'] ?? null,
]);
}
}
// Precision = comentários com $acted == true / total de comentários
// Recall = (precisa de gold dataset — humanos revisando os mesmos PRs)
Precision o GitHub te dá de graça. Recall exige um esforço extra: pegar os mesmos PRs e ter um humano (sênior, do time, que conhece o contexto) marcando os bugs reais que existiram. Em vez de fazer isso pra todo PR, faça pra 30 PRs aleatórios por mês. Dá pra calcular recall com intervalo de confiança decente e o custo de revisão humana fica controlado.
Meta razoável para começar: precision ≥ 70%, recall ≥ 40%. Se a precision cair de 70 entre semanas, aperta o threshold (de 80 pra 85). Se subir muito acima de 80 e o recall despencar, afrouxa.
Limitações e armadilhas
Forks não veem secrets. pull_request de fork roda sem ANTHROPIC_API_KEY. Tem gente que usa pull_request_target pra contornar — péssima ideia. O pull_request_target checa out o base ref por padrão (revisão errada), e se você mudar pra fazer checkout do head ref, está executando código de atacante com seus secrets. A solução correta é desligar o bot pra forks ou ter um maintainer rebaseando em um branch interno antes da revisão.
PRs gigantes estouram o context window. PR com 80 arquivos e 4.000 linhas alteradas vai mal. O agente perde o fio, comenta em coisa estranha, gasta turnos navegando arquivos. Configure um guard no início do prompt: se o diff total passa de 1.500 linhas, peça pro autor quebrar — e o bot comenta uma vez só, com a sugestão de split.
Linter já pega. Tudo que Pint, Larastan ou PHPStan resolvem não pode entrar no escopo do bot. Coloque a regra no prompt e rode o linter como parte do agente — não pra reportar, pra suprimir.
Código de domínio que o modelo não conhece. Em código que mexe com lei/regulação específica (LGPD, cálculo fiscal, contratos), o modelo inventa preocupações genéricas. Marque essas pastas com um arquivo CLAUDE.md local: "esta pasta implementa regras de cálculo de ICMS validadas pelo time fiscal; não sugira mudanças sem evidência de bug específico".
Custo escala com PR ativo. Não esqueça do synchronize. Toda força-push dispara nova revisão. Em PRs muito iterativos isso vira 10 reviews. Configure debounce com concurrency no workflow pra cancelar review em andamento quando novo push chegar.
FAQ rápido
Posso usar Sonnet ou tem que ser Opus?
Sonnet 4.6 dá conta da maioria. Use Opus 4.7 num job separado, disparado por label needs-deep-review, para PRs em billing, segurança ou migrações. Diferença de custo é real, mas o ganho de recall em código crítico justifica.
Quanto custa por PR? Em PRs médios (até 500 linhas alteradas) com Sonnet 4.6, fica entre $0.05 e $0.30 por revisão. PRs grandes com agente rodando teste e abrindo histórico podem chegar a $1–2. Opus 4.7 multiplica por 3–5x.
Como evitar comentário em PRs draft?
if: github.event.pull_request.draft == false no job. Quando o autor marca pronto pra review, o evento ready_for_review dispara — adicione esse trigger se quiser revisão ao sair de draft.
Funciona com fork sem dor?
Não com a chave da Anthropic acessível. Para projetos open source com forks ativos, use o trigger pull_request_target com cuidado extremo e checkout fixo no base ref, ou rebata os PRs de fork em um branch interno antes da revisão.
Conclusão
Code review com IA não compete em volume de comentário. Compete em sinal. O bot que comenta uma vez e acerta vale dez bots que comentam em todo PR e o dev ignora. Tudo que separa um do outro está no harness em volta do modelo: três camadas de contexto, lista explícita do que ignorar, ferramentas pra validar antes de palpitar, scoring de confiança e um filtro que prefere errar pelo silêncio.
O próximo passo é tratar o bot como qualquer outro reviewer do time: ele tem métrica, tem feedback, tem PR de calibração no prompt quando começa a falar demais. Aí ele para de ser carimbo e vira par.
Esse padrão — modelo dentro de um harness com tools, scoring e filtro — é o mesmo que está por trás de qualquer agente de IA que aguenta produção. Se quiser destrinchar a engenharia disso ao vivo, do loop autônomo ao agente em produção, é o tema do workshop Harness Engineering com Claude Code que estamos rodando no Beer & Code.

{AI Engineer} — apaixonado por Laravel, arquitetura de software e construir produtos com impacto. Compartilho aqui tutoriais, descobertas e reflexões sobre o dia a dia de engenharia.
Você também pode gostar

5 padrões de prompt que sobem o sinal do code review com LLM de 12% pra 67%
Bot de code review que comenta "considere adicionar testes" em todo PR vira meme rápido. Cinco padrões — diff-anchored, severity gate, tool use antes do palpite, citation obrigatória e self-grading com threshold — sobem o signal ratio acima de 60% e mantêm o time confiando no review. Inclui workflow Laravel pronto.
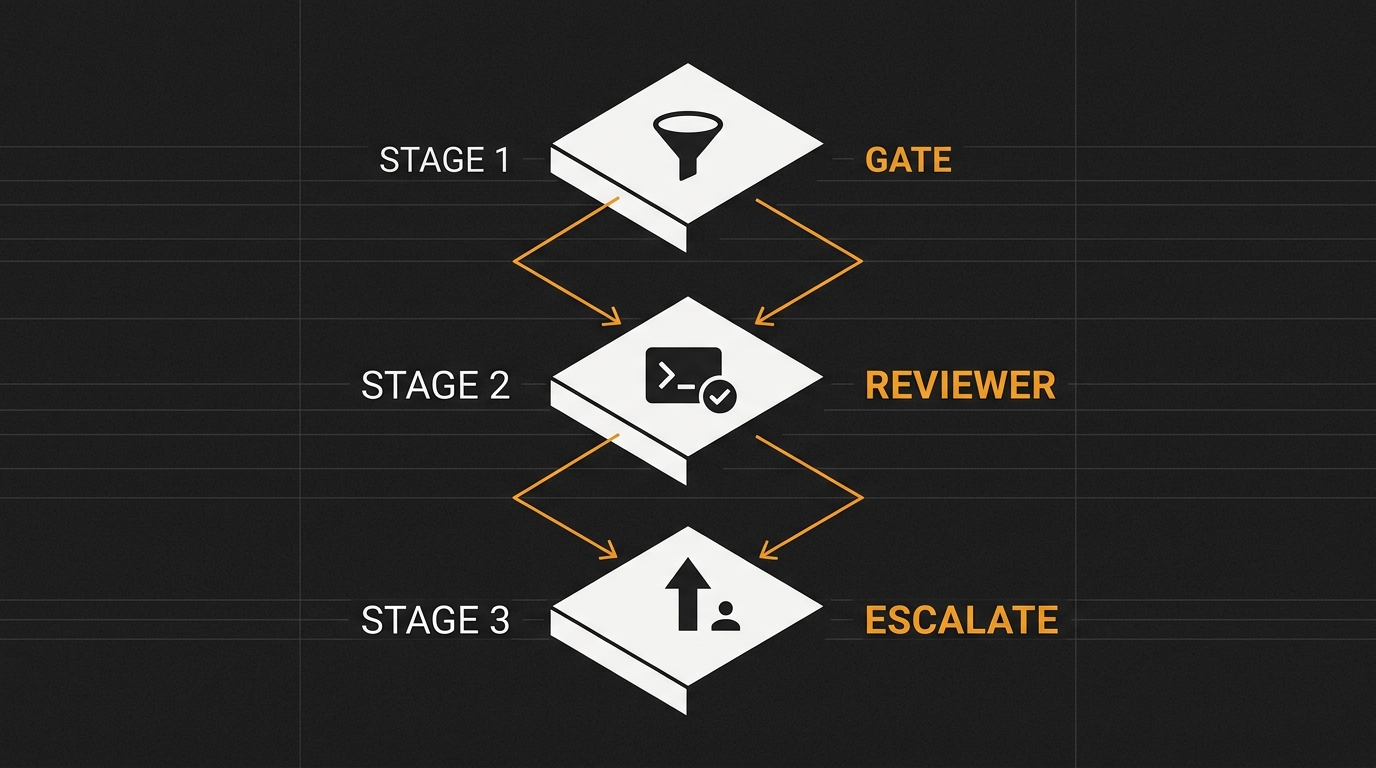
Pipeline de revisão automatizada de PR com GitHub Actions e Claude
Pipeline em três camadas que automatiza revisão de PR sem ruído: um gate filtra trivialidades, um reviewer com Claude e tool use roda php artisan test antes de comentar, e um escalator chama humano quando o modelo não tem confiança. Workflow YAML completo, prompt em XML em três blocos e um caso real de SQL injection que o bot pegou em produção.

A IA gerou código errado: por que acontece e como revisar antes de quebrar produção
O código que a IA gerou roda, compila e passa no happy path e quebra em produção. Entenda por que o modelo gera código plausível-mas-errado e qual processo de revisão pega o problema antes do merge.
IA para programar: como usar sem virar refém da ferramenta
Tem dev que dobrou de produtividade com IA e tem dev que não escreve mais uma função sem ela. A diferença é o workflow. Como usar IA para programar mantendo o entendimento do próprio código.
