#Claude Code

Qual IA usar para programar em 2026: Claude Code vs Codex
Comparativo prático entre Claude Code e Codex para coding agêntico em 2026: onde cada um ganha em repo real, terminal e custo. A melhor IA para programar em 2026 não é um nome — é uma decisão de cenário.
Claude Code em monorepo: como não estourar contexto em base grande
Estratégias para usar Claude Code em monorepo e large codebase sem estourar o context window: escopo de sessão, CLAUDE.md em camadas, code intelligence e subagentes.

Claude Code hooks, slash commands e MCP: os três recursos que mudam seu fluxo
Guia prático dos três pontos de extensão do Claude Code — hooks, slash commands e MCP. Os arquivos de config exatos pra transformar o agente de autocomplete em parte do seu fluxo de engenharia.

Claude -p vai morrer: como migrar para o Claude Agent SDK
O modo headless claude -p está sendo substituído pelo Claude Agent SDK. Guia prático de migração: o que muda no uso com seu plano Claude e como rodar agentes headless do jeito novo.
Melhor IA para programação em 2026: testei as principais lado a lado
Comparação prática das principais IAs para programar em 2026 — mesma task real rodada em Claude Code, Cursor e GitHub Copilot, com critérios honestos: custo, contexto e qualidade do diff.
Claude Code: o que é, como funciona e por que os devs migraram pra ele
O Claude Code é a ferramenta de dev que mais cresceu no ano. Antes de instalar, entenda o que ele faz de diferente do Copilot e do Cursor e onde ele não é a resposta.
Claude Opus 4.8 chegou: o que muda de verdade pra quem entrega IA em produção
A Anthropic lançou o Claude Opus 4.8 hoje. Filtramos o que importa pra quem coda e roda agentes: liderança no SWE-Bench Pro, 84% em browser-agent, tool calling com menos passos, 4x menos bug sem comentar, multimodal 61% mais barato e Dynamic Workflows com centenas de subagentes no Claude Code, tudo no mesmo preço do 4.7.
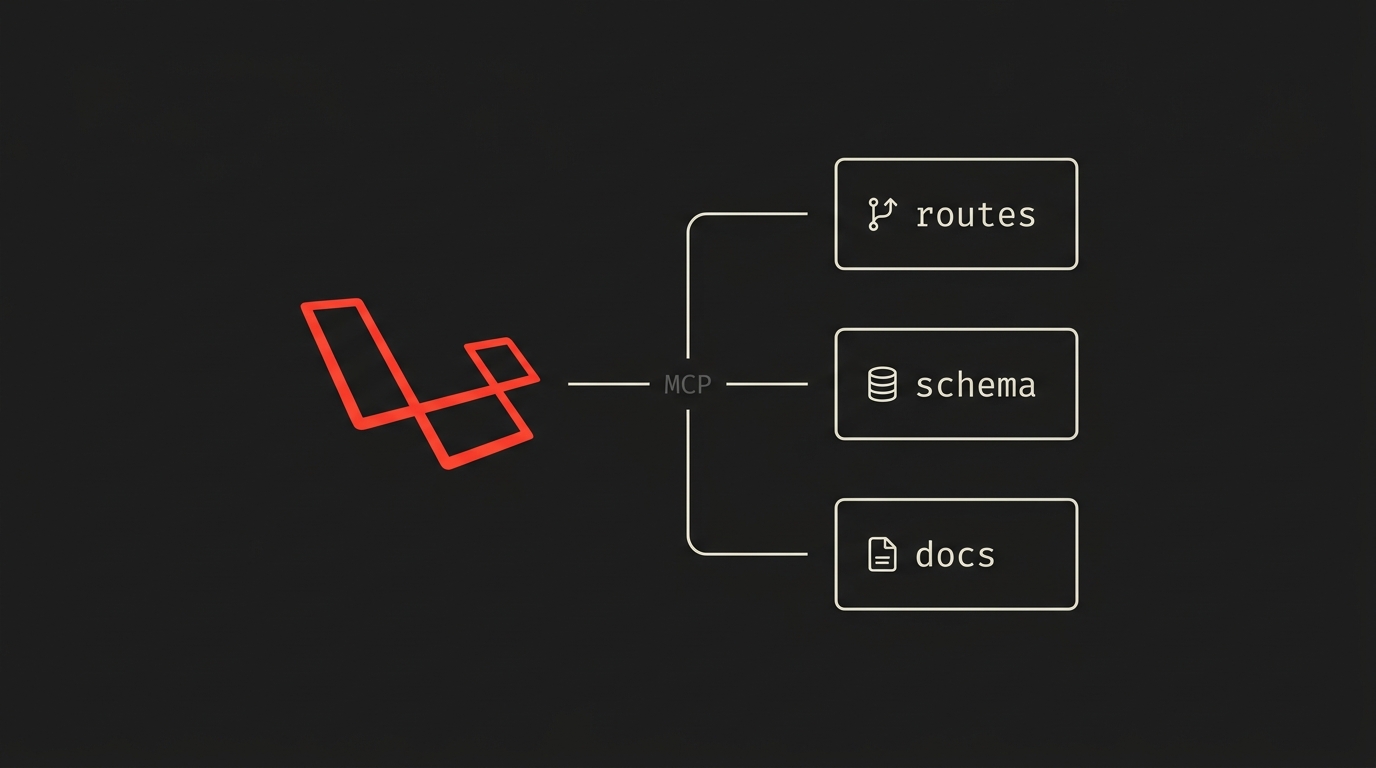
Laravel Boost: o MCP oficial que ensina o agente a ler seu app antes de gerar código
O Laravel Boost é o servidor MCP oficial do time Laravel — expõe routes, models, schema, docs e logs como tools que o agente consulta antes de gerar código. Instalação em 3 comandos, caso real de CRUD Order com 8 relacionamentos comparando com e sem Boost, e o que muda no fluxo de SDD.

Ferramentas de IA para dev backend: top 12 testadas em 90 dias de Laravel real
Review longa e opinada de 12 ferramentas de IA pra dev backend, depois de 90 dias rodando num Laravel real em produção. Nota 0-10, veredito em uma linha, e 5 que viralizaram mas não cumpriram.

Como documentar decisões técnicas com IA: ADRs que envelhecem bem (e o Claude que escreve com você)
Time pequeno raramente escreve ADR porque dói. Com Claude no fluxo a primeira versão sai em 4 minutos. Tem o template em 7 seções que envelhece bem, o prompt mestre em XML que extrai a decisão sem interrogatório e três anti-padrões clássicos que matam ADR em produção.
Vale a pena usar Cursor em 2026? 6 meses rodando Cursor, Claude Code e Windsurf lado a lado
Seis meses rodando Cursor, Claude Code e Windsurf no mesmo projeto Laravel. Pricing maio/2026, benchmarks, custo real em USD e veredito por persona: dev solo, time pequeno mixed-stack e time grande JS/TS.

5 padrões de prompt que sobem o sinal do code review com LLM de 12% pra 67%
Bot de code review que comenta "considere adicionar testes" em todo PR vira meme rápido. Cinco padrões — diff-anchored, severity gate, tool use antes do palpite, citation obrigatória e self-grading com threshold — sobem o signal ratio acima de 60% e mantêm o time confiando no review. Inclui workflow Laravel pronto.
