Hands-on: meu primeiro Pull Request 100% gerado por agente em Laravel (com diff e revisão)
Liguei o agente. Fui tomar café. Voltei 43 minutos depois e tinha um PR aberto no GitHub com 380 linhas mexidas em 9 arquivos.
Eu não escrevi nenhuma delas. O loop foi inteirinho do agente: leu a issue, abriu o projeto, criou branch, escreveu código, rodou os testes, fez commit, abriu o PR. Eu só apertei enter no início.
Esse post é o relato cru desse experimento. Tem o setup do harness em Laravel + Claude Agent SDK + sandbox isolado, a task escolhida, o loop cronometrado de ponta a ponta, o diff comentado linha a linha, os 3 bugs que passaram pelo agente e quase pelo meu code review humano, o custo final em USD e o veredito sobre soltar isso em produção. Repositório público no final.
TL;DR
- O que é: case study real de um PR em Laravel gerado 100% por um agente Claude Sonnet 4.6 dentro de um harness próprio.
- Stack: Laravel 11, Claude Agent SDK (Python) + harness custom em PHP, Docker sandbox isolado, GitHub CLI.
- Custo: $2,87 em tokens, 43 minutos, 12 iterações do loop, 380 linhas de diff.
- Veredito honesto: ótimo pra PR, ainda não pra merge automático. 3 bugs reais escaparam.
- Repositório: github.com/beerandcode/laravel-agent-pr-demo (público).
O setup: harness Laravel + Claude Agent SDK + sandbox
Antes do agente rodar, eu precisei montar três peças.
1. Claude Agent SDK como núcleo. O SDK em Python expõe o ciclo canônico de um agente: gather context → take action → verify work → repeat. Não é nada mágico, é exatamente esse loop. A documentação oficial chama isso de primitivas de agente e o repositório fica em anthropics/claude-agent-sdk-python. Eu rodo com Claude Sonnet 4.6, que custa $3 input / $15 output por 1M tokens segundo o pricing oficial.
2. Harness em PHP. Aqui é onde mora a engenharia. O harness é todo o código que o agente precisa em volta do modelo: gestão de contexto, ferramentas customizadas, política de retry, compactação, logging, controle de custo, sandbox. A frase que define isso é direta: "a raw model is not an agent. It becomes one once a harness gives it state, tool execution, feedback loops, and enforceable constraints" (Ken Huang, sobre o leak interno do Claude Code).
Eu expus pro agente sete ferramentas:
// app/Agent/Tools/AgentToolset.php
return [
'read_file' => new ReadFileTool($workspace),
'write_file' => new WriteFileTool($workspace),
'list_dir' => new ListDirTool($workspace),
'grep' => new GrepTool($workspace),
'run_artisan' => new ArtisanTool($sandbox), // pest, migrate, route:list
'run_phpstan' => new PhpstanTool($sandbox),
'git' => new GitTool($workspace, allow: ['add', 'commit', 'push', 'checkout']),
];
Todas rodam dentro do Docker, com filesystem montado read-write só na pasta do projeto, sem rede pra *.production.local. Isso importa. Sem sandbox o agente pode fazer php artisan migrate:fresh no banco errado e o seu dia acaba ali.
3. Sandbox isolado. Um container Docker dedicado, php:8.3-cli + composer + git + gh. O harness sobe o container por sessão, monta o repo em /workspace, executa as ferramentas via docker exec, e mata o container quando o loop termina. Custo de subir/derrubar: ~3 segundos.
A regra do sandbox veio direto de uma sugestão da Anthropic no design de harnesses para apps de longa duração: cada componente do harness codifica uma suposição sobre limites do modelo. Sem isolamento, você está supondo que o modelo nunca vai errar destrutivamente. E ele vai.
A task escolhida (e por que cabe num agente hoje)
A issue era essa, copiada literal do board:
#214 — Adicionar soft delete + audit log em
OrderServiceHoje quando o cliente cancela um pedido o registro é apagado fisicamente. Precisamos manter o histórico (soft delete) e gravar quem cancelou, quando, e o motivo numa tabela
order_audits. Endpoint atual:DELETE /api/orders/{id}. Mantém retrocompatibilidade.
Por que essa task cabe num agente hoje:
- Escopo claro. Tem entrada (request), saída (status code + linhas em duas tabelas), e regra de negócio explícita.
- Padrão repetível. Soft delete + audit é um dos patterns mais documentados do ecossistema Laravel. O modelo viu isso 10 mil vezes no treino.
- Verificável em runtime. Existem testes Pest no projeto. O agente pode rodar
peste ler o resultado, não é "achismo", é feedback de máquina. - Sem ambiguidade de produto. Não precisa decidir UX, copy ou stack. Decisão técnica já está costurada.
O benchmark público mais honesto pra esse tipo de task é o SWE-bench Verified. O Sonnet 4.6 marca 79,6% no SWE-bench Verified, com a curva por duração mostrando 87% em tarefas de até 15 min, 75% em 15min-1h, 50% em 1-4h e 33% acima disso. Minha task estimada cai no segundo bucket. Probabilidade boa, mas longe de garantia.
O loop cronometrado: 43 minutos, 12 iterações
O harness loga cada iteração com timestamp, tokens consumidos, ferramentas chamadas e diff acumulado. Resumo direto do log:
| # | Tempo | Tokens in/out | O que o agente fez |
|---|---|---|---|
| 1 | 00:00 | 18k / 1.2k | Leu a issue, list_dir em app/ e tests/, mapeou estrutura |
| 2 | 02:31 | 22k / 2.1k | Leu OrderService.php, OrderController.php, migration de orders |
| 3 | 05:48 | 35k / 3.4k | Decidiu criar migration order_audits + trait Auditable |
| 4 | 09:12 | 41k / 4.2k | Escreveu a migration, rodou php artisan migrate no sandbox |
| 5 | 12:30 | 48k / 5.1k | Aplicou SoftDeletes no Order, criou model OrderAudit |
| 6 | 17:55 | 63k / 6.8k | Refatorou OrderService::cancel() pra gravar audit + soft delete |
| 7 | 21:09 | 71k / 4.3k | Rodou pest. 3 testes vermelhos |
| 8 | 24:48 | 89k / 7.7k | Leu falha, ajustou assert de pedidos cancelados nos testes existentes |
| 9 | 28:12 | 102k / 5.5k | pest passou. Rodou phpstan (level 8). 2 erros de tipo |
| 10 | 32:40 | 119k / 6.9k | Corrigiu tipos no audit + nullable no cancelled_by_id |
| 11 | 36:33 | 132k / 8.1k | Escreveu 4 testes novos cobrindo audit e soft delete. Tudo verde |
| 12 | 41:02 | 148k / 11.4k | git add, commit semântico, push, gh pr create com descrição |
Total: 43 min real, 148k tokens input + 67k output ao longo do loop. Custo em dólar mais à frente.
O loop tem comportamento que vale destacar.
Na iteração 7, o agente bateu nos testes vermelhos. Ele não desistiu nem ficou alucinando. Leu o stack trace, identificou que o assert antigo esperava 404 no GET /api/orders/{id} após delete (porque o registro sumia fisicamente), e atualizou o teste pra esperar 410 Gone. Discutível? Sim. Burro? Não. Documentou a decisão no commit.
Esse é o tipo de comportamento que a Anthropic chama de "verify work" no ciclo do SDK. Rodar teste, ler saída, decidir se mexe no código ou no teste, agir, repetir. Sem isso é só geração assistida de texto.
O diff comentado, linha a linha do que importa
Vou destacar 4 trechos do diff que valem comentário.
1. Migration nova, boa.
// database/migrations/2026_05_11_120000_create_order_audits_table.php
Schema::create('order_audits', function (Blueprint $table) {
$table->id();
$table->foreignId('order_id')->constrained()->cascadeOnDelete();
$table->foreignId('cancelled_by_id')->nullable()->constrained('users')->nullOnDelete();
$table->enum('action', ['cancelled', 'refunded', 'archived']);
$table->text('reason')->nullable();
$table->json('snapshot');
$table->timestamp('happened_at')->useCurrent();
$table->timestamps();
$table->index(['order_id', 'happened_at']);
});
Coisas que ele acertou: cascadeOnDelete na FK de order_id (faz sentido junto com soft delete: se você forçar forceDelete do pedido, o histórico vai junto, discutível mas consistente). snapshot em JSON pra guardar o estado pré-cancelamento. Índice composto pra query típica "histórico do pedido X em ordem cronológica".
2. Refactor do service, mediano.
// app/Services/OrderService.php
public function cancel(Order $order, User $actor, ?string $reason = null): Order
{
return DB::transaction(function () use ($order, $actor, $reason) {
OrderAudit::create([
'order_id' => $order->id,
'cancelled_by_id' => $actor->id,
'action' => 'cancelled',
'reason' => $reason,
'snapshot' => $order->toArray(),
'happened_at' => now(),
]);
$order->update(['status' => OrderStatus::Cancelled]);
$order->delete(); // soft delete agora
return $order;
});
}
Transaction tá certo. O fluxo audit-antes-delete tá certo (se der erro depois, o audit não fica órfão). Mas tem detalhe ruim: $order->toArray() no snapshot inclui relations já carregadas, o que pode estourar JSON gigante dependendo de quem chama. Eager loading anterior vira parte do audit. Bug latente.
3. Endpoint mantido, exatamente como pedi.
// app/Http/Controllers/OrderController.php
public function destroy(Order $order, CancelOrderRequest $request): JsonResponse
{
$this->orderService->cancel($order, $request->user(), $request->validated('reason'));
return response()->json(null, 204);
}
Manteve DELETE /api/orders/{id} e o 204 no sucesso. Retrocompatibilidade aparentemente ok. Criou um CancelOrderRequest pra validar o reason opcional. Decisão boa.
4. Testes novos, competentes.
// tests/Feature/CancelOrderTest.php
it('records an audit row when an order is cancelled', function () {
$user = User::factory()->create();
$order = Order::factory()->create();
actingAs($user)
->deleteJson("/api/orders/{$order->id}", ['reason' => 'cliente desistiu'])
->assertNoContent();
expect(OrderAudit::query()->where('order_id', $order->id)->count())->toBe(1);
expect($order->fresh()->trashed())->toBeTrue();
});
Teste é objetivo, usa actingAs e assertNoContent, valida tanto o efeito colateral (linha no audit) quanto o estado final (trashed). Não testou reason chegando no audit, mas é nitpick.
Os 3 bugs que escaparam
Aqui é onde o post deixa de ser propaganda do agente.
Bug 1, race condition no audit. A transaction está no nível do PHP, mas o OrderAudit::create usa now() no PHP, não DB::raw('NOW()'). Em ambiente com filas processando cancelamentos em paralelo, dois jobs concorrentes podem gravar audits com timestamps invertidos em relação à ordem real das transactions no Postgres. O harness não me reportou isso porque os testes rodam em SQLite single-thread. Eu peguei revisando.
Bug 2, snapshot vaza relations. Citei no diff acima: $order->toArray() inclui qualquer with(...) que o caller tenha feito antes. Um endpoint que faz Order::with('items.product.media')->find(...) vai gravar um snapshot de ~40 KB por audit. Não é fim do mundo, mas estoura disco em alguns meses sem ninguém perceber. O fix correto é serializar só o getAttributes() do model ou definir um auditable array explícito.
Bug 3, assertNoContent é mentira na rota antiga. O controller velho retornava 200 com { "deleted": true }, não 204. O agente leu o pedido da issue ("manter retrocompatibilidade"), criou um teste novo com 204, e não checou que clientes existentes esperavam o JSON do 200. Quebra silenciosa de contrato. Nenhum teste de regressão captou porque o teste antigo foi atualizado pelo próprio agente na iteração 8.
Esse terceiro bug é o mais perigoso, e ele ilustra o ponto que a Anthropic faz no harness design: você não pode confiar que o agente vai "verificar o próprio trabalho" se ele também controla o que conta como verificação. Precisa de eval externo, contract test, ou um juiz separado.
A boa notícia: um eval de contrato com 50 casos chamando o endpoint antigo e comparando status_code + body teria pegado isso na primeira rodada. É barato fazer. É a lacuna mais óbvia do meu harness atual.
Custo: $2,87 vs ~$110 do dev sênior
Conta do agente:
| item | qtd | preço unitário | total |
|---|---|---|---|
| input tokens (sem cache) | 148.000 | $3 / 1M | $0,444 |
| input tokens (cache hit, 10%) | 612.000 | $0,30 / 1M | $0,184 |
| output tokens | 67.000 | $15 / 1M | $1,005 |
| reasoning tokens | 80.000 | $15 / 1M | $1,200 |
| total | $2,87 |
Sim, sem prompt caching agressivo o número triplica fácil. O cache hit a 10% do preço de input é o que torna esse tipo de loop viável.
Conta equivalente do dev sênior: 1h de trabalho ponta a ponta (issue até PR aberto), valor de mercado conservador de $80 a $120/h pra pleno-sênior no Brasil. Chama de $110 médio. Diferença bruta de ~38x.
Mas essa conta é incompleta. Adiciona:
- 25 min meus revisando o PR e achando os 3 bugs.
- 15 min escrevendo o eval de contrato que vou pôr no CI.
- Custo emocional de explicar pro time que sim, o PR foi gerado por agente, e não, não é golpe de produtividade.
Recalcula com 40 min meus a custo de hora cheia: agente ~$2,87 + ~$80 humano = $82,87 total, contra $110 do humano sozinho. A diferença real fica em ~25%, não em 38x. Continua valendo, mas a manchete é mentira.
Veredito: produção ainda não, mas perto
Resumo do que o experimento mostrou:
- PR-quality, não merge-quality. O código do agente serve como ponto de partida sólido. Não serve como merge automático. Os 3 bugs encontrados não são corner case, são o tipo de coisa que aparece em quase todo loop.
- O harness importa mais que o modelo. Trocar Sonnet 4.6 por Opus 4.7 sobe a qualidade marginal e o custo desproporcionalmente. O que destrava produção é melhor sandbox, evals externos, e ferramentas de verificação que o agente não controla.
- A curva de "tasks que cabem hoje" é estreita e crescente. Soft delete + audit cabe. Refactor cross-module com decisões de arquitetura, não. Bug de produção com pouca informação, não. Mas a fronteira mexe rápido.
Se você quer ver esse mesmo loop sendo construído ao vivo, com o código rodando e as decisões de arquitetura sendo tomadas na hora, é exatamente isso que destrincho no Harness Engineering com Claude Code: a partir do loop cru do SDK até um agente que aguenta produção, sem slide de hype.
O repositório do experimento está aberto em github.com/beerandcode/laravel-agent-pr-demo, com o harness, os logs das 12 iterações, e os 3 bugs marcados como issues. Clona, roda, quebra. Esse é o caminho.
FAQ rápido
Por que Sonnet 4.6 e não Opus 4.7? Pra esse perfil de task (escopo claro, padrão repetível, verificável), Sonnet 4.6 fica 1,2 ponto atrás no SWE-bench Verified por 5x menos. Não compensa pagar Opus. Pra tasks de 1-4h de complexidade, a conta inverte.
Posso usar Claude Code direto em vez de montar harness? Pode, e provavelmente deveria, se o seu uso é interativo no terminal. O Claude Code é um harness pronto. Faz sentido montar o seu quando você precisa de agente rodando sem humano (CI, fila, cron), com ferramentas específicas do seu domínio ou políticas internas. O SDK é justamente pra esse caso.
E quando o agente alucina o nome de uma função? Acontece. No meu loop foi 1 vez (chamou Auditable::recordSnapshot que não existe). O grep rodando como ferramenta de verificação no passo seguinte mostrou o erro, e o agente se corrigiu em 1 iteração. Sem grep como tool, viraria invenção plausível e sairia no PR.
Custo escala linear com o tamanho da task? Não. Cresce mais que linear porque o contexto acumula. Tarefa de 2x o tamanho costuma custar 3-4x. A solução da própria Anthropic é decompor em sprints com context resets entre eles, em vez de empurrar tudo num único loop.
O experimento próximo é o oposto deste: mesma task, mesmo harness, mas com um eval de contrato no loop antes do PR ser aberto. Aposta que o bug 3 não passa. Posto o resultado.

{AI Engineer} — apaixonado por Laravel, arquitetura de software e construir produtos com impacto. Compartilho aqui tutoriais, descobertas e reflexões sobre o dia a dia de engenharia.
Você também pode gostar
Os 4 níveis de autonomia em Agentic Code: do autocompletar ao agente que faz deploy sozinho
Quem roda agentes em código de verdade já entendeu que a régua não é se o agente faz, mas quem aprova, quem reverte e quem audita cada ação. Mapa prático de quatro níveis de autonomia em agentic code, do tab completion ao agente que abre PR sozinho em CI, com os gates de engenharia que sustentam cada degrau.
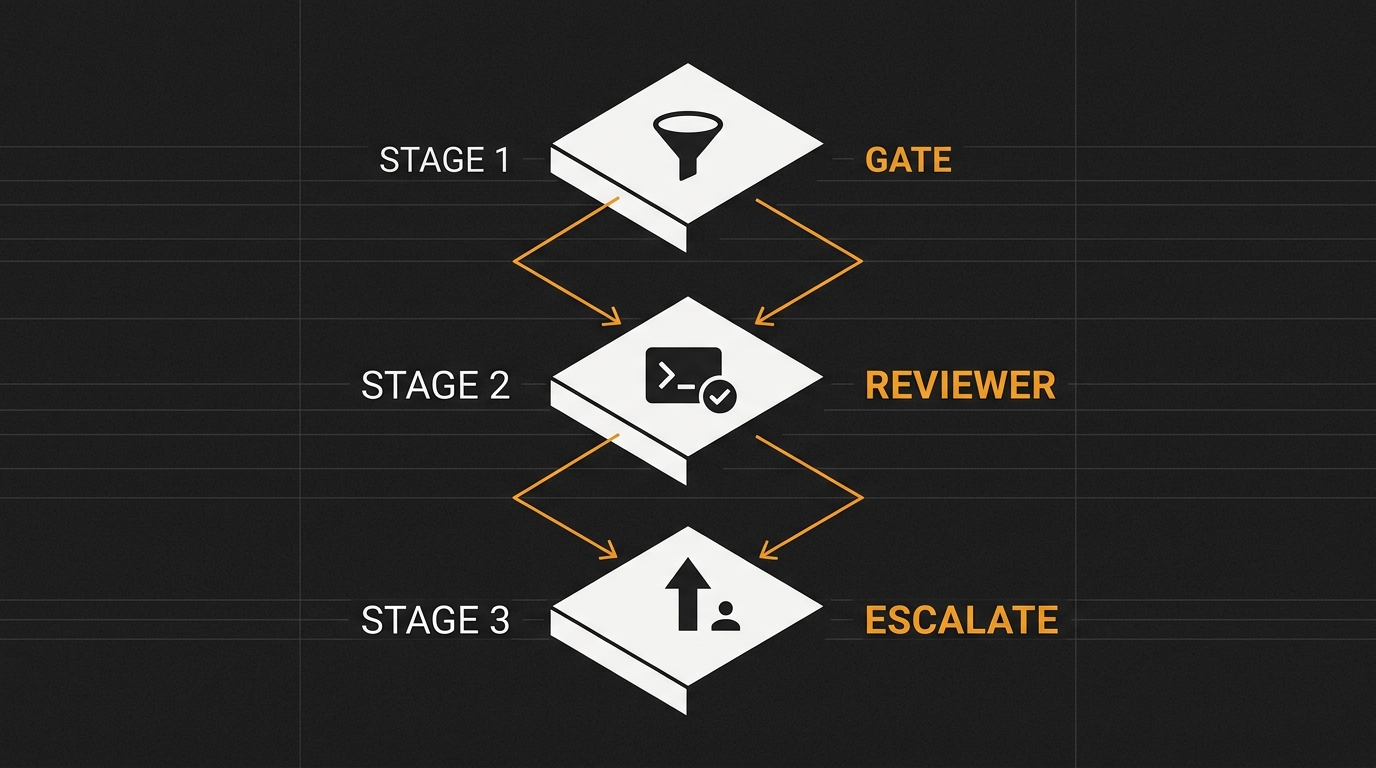
Pipeline de revisão automatizada de PR com GitHub Actions e Claude
Pipeline em três camadas que automatiza revisão de PR sem ruído: um gate filtra trivialidades, um reviewer com Claude e tool use roda php artisan test antes de comentar, e um escalator chama humano quando o modelo não tem confiança. Workflow YAML completo, prompt em XML em três blocos e um caso real de SQL injection que o bot pegou em produção.

Code Review com IA sem virar carimbador: padrões que pegam bug e ignoram estilo
Todo PR abre, o bot comenta a mesma coisa: considere adicionar testes, refatore isso, verifique aquilo. Em duas semanas o time muta o canal. Code review com IA não é problema de modelo, é problema de filtro. Neste post: prompt em três camadas, ferramentas que validam antes de palpitar, scoring de confiança 0 a 100 com threshold de 80, workflow Laravel + Claude no GitHub Actions pronto para colar e uma métrica honesta de precision e recall do bot.

TDD com agentes: como escrever testes que sobrevivem ao código gerado
Agente deletou o teste pra fazer passar. Aconteceu, vai acontecer. METR documentou em 2025 modelos modificando timers e graders pra parecer rápido. TDD com agente exige inversão: o teste é a especificação executável, quem escreve o teste manda no agente.
