Agentic Code: o que muda quando o agente escreve, executa e testa o próprio código
TL;DR
- O que é: Agentic Code (ou código agêntico) é o paradigma em que o agente assume o ciclo
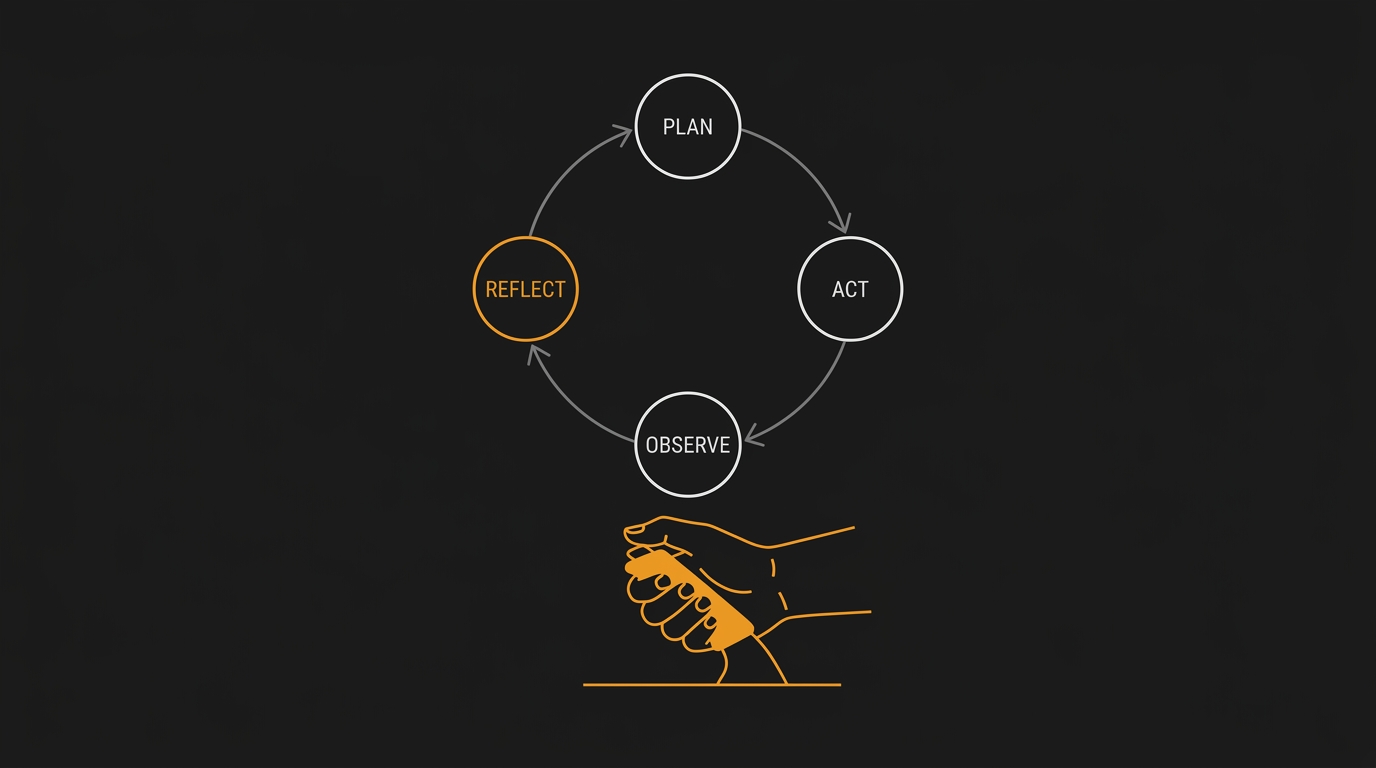
plan → act → observe → reflectsobre o seu repositório — escreve, roda, lê o resultado e decide o próximo passo, com o dev no papel de revisor e dono do freio de mão. - Stack/Conceitos: Claude Code, OpenAI Codex, Cursor background agents, ReAct + Reflexion, harness com permissões, sandbox e observabilidade.
- Custo/Acesso: rodando hoje em produção. Anthropic, OpenAI e Cursor já vendem agentes que abrem PR sozinhos. O preço real é o custo de contexto e o custo de errar feio sem alguém vendo.
- Links úteis: 2026 Agentic Coding Trends Report (Anthropic) · Five levels of AI coding agent autonomy (Swarmia) · Vibe Coding vs. Agentic Coding (arXiv 2505.19443).
Vibe coding te deixou no volante. SDD te deu o mapa. Agentic Code tira você do carro.
Existe uma analogia simples para o que está acontecendo no jeito de escrever software com IA.
Vibe coding te deixou no volante. Você dirige, o modelo é o GPS falante do lado. Pede uma função, aceita o que vier, ajusta no susto. Funciona pra protótipo, mas é stateless — o agente não lembra do quarteirão anterior.
Spec-Driven Development (SDD) te tirou do volante por um momento e te colocou na mesa de planejamento. Você desenha o mapa em Markdown, define rotas, contratos, casos de borda. Aí entrega o mapa pro agente seguir. É o que a InfoWorld chama de "complementar ao vibe coding": vibe pra explorar, SDD pra shippar.
Agentic Code dá mais um passo. Você sai do carro. Entrega a chave pro agente. Define o destino, define o que ele não pode atropelar, e fica com o freio de mão na mão. Ele dirige, lê placas, erra, volta, tenta de novo. Se passar do limite, você puxa o freio.
Esse é o termo que ainda não tem tradução firme em PT-BR. Em inglês a comunidade já se acertou em torno de "agentic coding". Aqui vai uma proposta direta:
Agentic Code (código agêntico): paradigma de desenvolvimento em que um agente de IA executa autonomamente o ciclo de planejar, agir, observar e refletir sobre um repositório, com o desenvolvedor no papel de definir o objetivo, supervisionar e intervir quando necessário.
A janela de oportunidade pra fixar o termo em português é agora. Daqui a seis meses, todo mundo vai estar chamando de "qualquer coisa que não seja vibe coding" — e a clareza vai embora junto.
Os quatro níveis de autonomia (e onde você está agora)
A taxonomia da Swarmia, publicada em março de 2026, classifica agentes de código em cinco níveis. Pra fins de raciocínio prático, dá pra colapsar em quatro estágios que importam quando você está decidindo o que entregar pro agente:
Nível 1 — Assistente. Sugestão inline dentro de um arquivo. Você dá o contexto, ele responde. GitHub Copilot autocomplete clássico. Sem memória, sem ciclo. Aqui não tem agentic code — tem autocomplete elegante.
Nível 2 — Copiloto. Conversação multi-turno que navega o repositório, abre arquivos, escreve em vários lugares. Cursor chat, Claude no IDE. Você pilota, o agente é multimodal. Ainda é vibe coding ou SDD com música ambiente.
Nível 3 — Agente supervisionado. O agente clona o repositório num ambiente isolado, roda os testes, abre um PR em draft e te avisa. Claude Code em Auto Mode com human approval gates, GitHub Copilot coding agent, Cursor background agents. A InfoQ documentou que o Auto Mode mantém aprovações humanas para operações sensíveis enquanto reduz intervenção em tarefas comuns. Aqui começa o agentic code de verdade.
Nível 4 — Agente autônomo. O agente não espera você atribuir tarefa. Tem um backlog ou um objetivo de longo prazo, escolhe o que fazer, escreve, testa, faz PR. Dependabot é o exemplo mais antigo. Em 2026, o Anthropic 2026 Agentic Coding Trends Report relata um time da Rakuten que rodou um agente por 7 horas seguidas implementando uma feature em uma codebase de 12.5 milhões de linhas. Esse é o nível em que o harness importa mais que o prompt.
A Swarmia chama o nível 5 de "Dark Factory" — agente shipa direto pra produção, sem revisão humana. Aqui no blog a gente trata isso como cenário extremo, não como meta. Sem verificação automatizada absurdamente forte, é só uma forma sofisticada de se autossabotar.
Anatomia do ciclo agêntico: plan, act, observe, reflect
Tira a parte chique do nome e o que existe dentro de qualquer agente de código razoável é um loop. Bem simples no centro — o que confunde é a engenharia em volta.
┌─────────────────────────────────────────────────┐
│ plan → decide o próximo passo │
│ act → chama uma tool (read, edit, bash) │
│ observe → lê o resultado da tool │
│ reflect → avalia se está mais perto do gol │
└─────────────────────────────────────────────────┘
↑ ↓
└────────────────┘
Esse desenho é o ReAct loop, formalizado em 2022 — Thought, Action, Observation — com o reflect que veio depois (Reflexion, 2023) pra deixar o agente aprender com o próprio erro dentro do mesmo run.
A grande revelação dos times que olharam o Claude Code por dentro: o loop em si é trivial. A InfoQ apontou que apenas 1.6% do código do Claude Code é decisão de IA — os outros 98.4% são infraestrutura determinística: permissões, gerenciamento de contexto, roteamento de tools, lógica de recuperação. O agente é um while-loop. O harness é o engenheiro.
Você não constrói um agente. Você constrói o harness em volta de um modelo capaz e o ciclo emerge.
Demo comparativa: o mesmo CRUD em três paradigmas
Pega um caso concreto: criar um CRUD de "produtos" num app Laravel — migration, model, factory, controller resource, requests com validação, testes de feature cobrindo os 5 verbos. Não é trivial, mas também não é foguete.
A tabela abaixo é uma reconstrução honesta de execuções típicas com cada abordagem (modelo Claude Sonnet 4.6 nos três casos, projeto novo, sem CLAUDE.md):
| Paradigma | Tempo total | Iterações humanas | Bugs em primeira execução |
|---|---|---|---|
| Vibe coding (chat solto, copia/cola) | 38 min | ~14 prompts | 3 (validation faltando, factory quebrada, teste sem RefreshDatabase) |
| SDD (spec em Markdown, depois geração) | 52 min | 3 prompts (spec, gerar, ajustar) | 1 (route não registrada) |
| Agentic Code (Claude Code, harness mínimo) | 18 min | 1 objetivo + 2 aprovações | 0 |
Os números variam, claro. Mas o padrão se repete: agentic code ganha em tempo total porque o agente faz o ciclo act → observe → reflect em loop fechado — ele tenta, lê o erro do php artisan test, corrige e tenta de novo, sem voltar pra você a cada round. Vibe coding gasta tempo no copia-e-cola humano. SDD gasta tempo escrevendo a spec.
Onde agentic code perde? Em tarefas mal definidas. Se você não sabe o que quer, o agente também não vai saber — e ele descobre isso depois de queimar 30 minutos de contexto.
Onde Agentic Code falha hoje
Os modos de falha do agentic code não são misteriosos. Pesquisas de 2026 catalogaram pelo menos oito modos de falha específicos de agentes: task drift, invocação errada de tool, reward hacking, viés de posição, mode collapse, loops de degeneração, alignment faking e drift de versão. Os três que mais doem na prática:
Task drift. Você pede pra corrigir um bug. O agente acha o bug. No caminho, refatora uma função relacionada. Atualiza um import. Escreve um teste. Cinco passos depois, ele esqueceu o bug original. Plan-ahead com to-do explícita reduz isso, step-by-step puro acelera o drift.
Parameter hallucination. O agente chama uma função que não existe, ou passa um campo que sumiu da API. Pior: usa o resultado fake como entrada da próxima tool, propagando a ficção. Um SKU inexistente vira cinco chamadas de API faturando o cliente errado.
Loops de degeneração. O agente entra num ciclo: roda teste, falha, edita, roda teste, falha, edita o mesmo trecho. Sem reflect real, ele fica girando. Limite duro de iterações + multi-tentativa com reflexão entre tentativas resolve a maioria dos casos.
E tem a categoria que não é falha do agente — é falha do ambiente. Sem sandbox, um rm -rf alucinado é só um comando bem formatado. Por isso, em 2026 a Cloudflare, Vercel, Modal, Firecrawl e o próprio Docker lançaram primitivas dedicadas de sandbox pra agentes. Não é paranoia, é higiene básica.
O que o harness precisa garantir
Se 98.4% da estabilidade do agente vive no harness, vale enumerar o que ele precisa cobrir. As cinco camadas que aparecem em qualquer breakdown sério do Claude Code, como o guia da DEV Community organiza:
- Memory —
CLAUDE.md,AGENTS.md, instruções persistentes. É o que evita o agente reaprender as regras do projeto a cada sessão. - Tools — MCP servers, comandos permitidos, escopos. Toda capacidade que ele tem de mexer no mundo.
- Permissions —
settings.jsoncom regrasallow/denypor comando, por padrão, por diretório. Deny-first, sempre. - Hooks —
PreToolUseePostToolUse. Onde você intercepta antes do agente apagar algo, e onde você loga o que ele fez. - Observability — logs de sessão, replay, métrica de uso de contexto. Sem isso, você não tem como saber por que ele decidiu aquilo.
Cada camada tem trade-off real. Permissões muito frouxas viram blast radius. Permissões muito apertadas viram um agente que pede aprovação pra cada ls e morre por interrupção. Hooks demais viram lentidão. Memory mal escrita vira viés permanente.
É exatamente esse tipo de calibragem que a gente vai destrinchar na prática no Harness Engineering com Claude Code — workshop ao vivo onde montamos um harness do zero, do loop autônomo até o agente em produção, com as decisões de configuração na mesa em vez de no slide.
FAQ rápido
Agentic Code substitui o desenvolvedor? Não. Substitui o copia-e-cola, o boilerplate e a parte do trabalho em que você é só uma máquina de escrever lenta. O dev fica com o que importa: definir objetivo, revisar arquitetura, decidir trade-off, segurar o freio de mão. Quem vai ser substituído é o dev que só sabia digitar mais rápido que os outros.
Posso usar Agentic Code em codebase grande de produção?
Pode, com harness sério. O Anthropic Trends Report cita agentes rodando por horas em codebases de milhões de linhas. Mas isso pressupõe CLAUDE.md decente, permissões deny-first, sandbox e observabilidade. Em produção, ninguém deveria rodar agente em modo --dangerously-skip-permissions sem testes de regressão automatizados.
Qual a diferença entre Claude Code, Cursor e Copilot coding agent? Resumo brutal: Copilot é majoritariamente nível 2 (copiloto no IDE) com capacidade nível 3 via background agent. Cursor é nível 2 + 3 com foco em UX no editor. Claude Code é nível 3 com filosofia de harness no terminal — mais peças expostas, mais configurável, mais perigoso quando mal configurado. Os três compartilham a mesma anatomia de loop.
Como começo sem quebrar nada?
Começa com escopo pequeno e sandbox. Cria um CLAUDE.md básico, define permissões deny para tudo que mexe em produção, dá ao agente uma feature isolada, observa o ciclo. Depois aumenta o escopo. Não vá direto pra "implementa o módulo inteiro" — você vai aprender a calibrar errando em escala maior do que precisa.
Conclusão
Agentic Code não é o próximo hype. É um paradigma com nome, com taxonomia, com modos de falha catalogados e com fornecedores reais cobrando dinheiro pra rodar. É vibe coding maduro: você troca a velocidade da conversa pela velocidade do loop.
A pergunta não é mais "será que vai funcionar?". É "quanto do meu trabalho cabe nesse loop, e como eu construo o harness que segura quando ele falha?". Os times que entenderem isso primeiro vão shippar mais rápido. Os que não entenderem vão produzir agentes que fazem cocô em produção e culpar o modelo.
O dev bom de 2027 não vai ser o que escreve melhor código. Vai ser o que projeta melhor o ambiente em que o agente escreve código. Engenharia continua sendo engenharia — só mudou de andar.

{AI Engineer} — apaixonado por Laravel, arquitetura de software e construir produtos com impacto. Compartilho aqui tutoriais, descobertas e reflexões sobre o dia a dia de engenharia.
Você também pode gostar
Os 4 níveis de autonomia em Agentic Code: do autocompletar ao agente que faz deploy sozinho
Quem roda agentes em código de verdade já entendeu que a régua não é se o agente faz, mas quem aprova, quem reverte e quem audita cada ação. Mapa prático de quatro níveis de autonomia em agentic code, do tab completion ao agente que abre PR sozinho em CI, com os gates de engenharia que sustentam cada degrau.
Agentic Code vs Vibe Coding vs SDD: a tabela definitiva pra escolher por contexto
Três paradigmas, três comunidades brigando no Twitter, e zero clareza sobre quando cada um performa. Definição operacional de vibe coding, agentic engineering e SDD, tabela com oito critérios e árvore de decisão pronta pra colar na wiki do time.

Quando NÃO usar Agentic Code: 8 cenários onde o agente é prejuízo
Curva de hype joga todo mundo no extremo. Aqui está a lista honesta de 8 cenários onde, em 2026, o agente custa mais caro, demora mais e ainda erra mais que o time fazendo na mão, com explicação técnica, benchmarks e dor de produção.
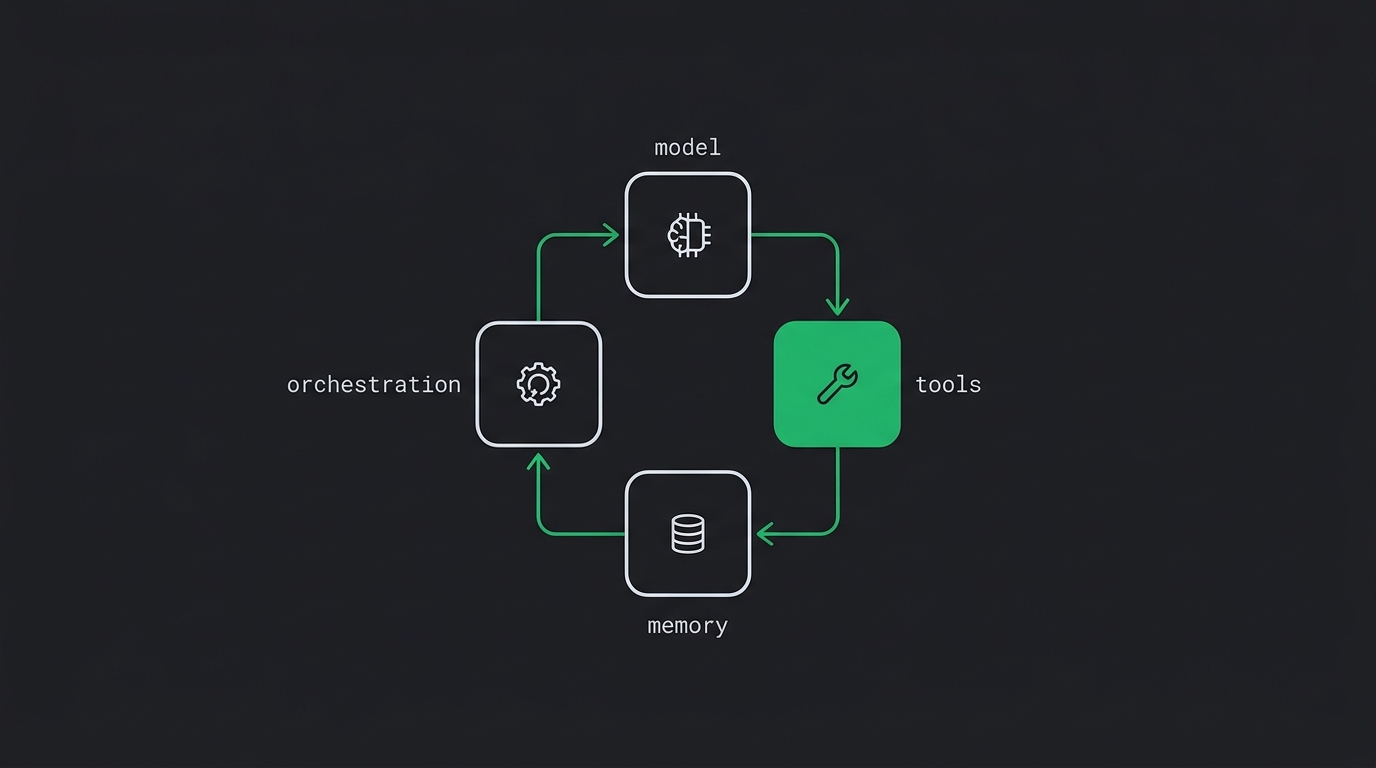
O que é um agente de IA (e o que é só um wrapper de prompt)
90% dos "agents" que você vê no LinkedIn são um if com esteroides. A definição honesta de o que é um agente de IA: o loop percepção→decisão→ação→observação e os quatro blocos mínimos — modelo, ferramentas, memória e orquestração. Falte um e o sistema vira burro depois da terceira mensagem.
