#Agentic Code

OpenAI Codex bug: ele grava 640 TB/ano e pode matar seu SSD em menos de 1 ano
O Codex tem um sink de log em SQLite que roda em TRACE global e grava ~640 TB/ano, o suficiente pra queimar a vida útil de um SSD de 1 TB em menos de um ano. E ele ignora o RUST_LOG. Entenda a causa, diagnostique e pare o sangramento com uma linha.
GLM 5.2: o melhor modelo de código open source é chinês, MIT e 6x mais barato
A Z.ai (ex-Zhipu) lançou o GLM 5.2, modelo open-weight de 753B sob licença MIT que fica a 0,7 ponto do Claude Opus 4.8 em código e custa um sexto do preço por token. O que muda pra quem programa com IA no Brasil — incluindo rodar self-host.

Agent improvement loop: o ciclo que faz o agente melhorar o próprio código
Como montar um loop de auto-melhoria de agente — gera, testa, avalia, corrige — inspirado no agent improvement loop do Agents SDK da OpenAI. Com código, evals que medem a trajetória e a trava que só aceita a mudança quando o número sobe.
Codex CLI: como usar goals para guiar o agente sem microgerenciar
O recurso /goal do Codex CLI faz o agente da OpenAI perseguir um objetivo sozinho. Aprenda a escrever um goal como contrato — com escopo, verificação e condição de parada — em vez de um prompt com esperança embutida.
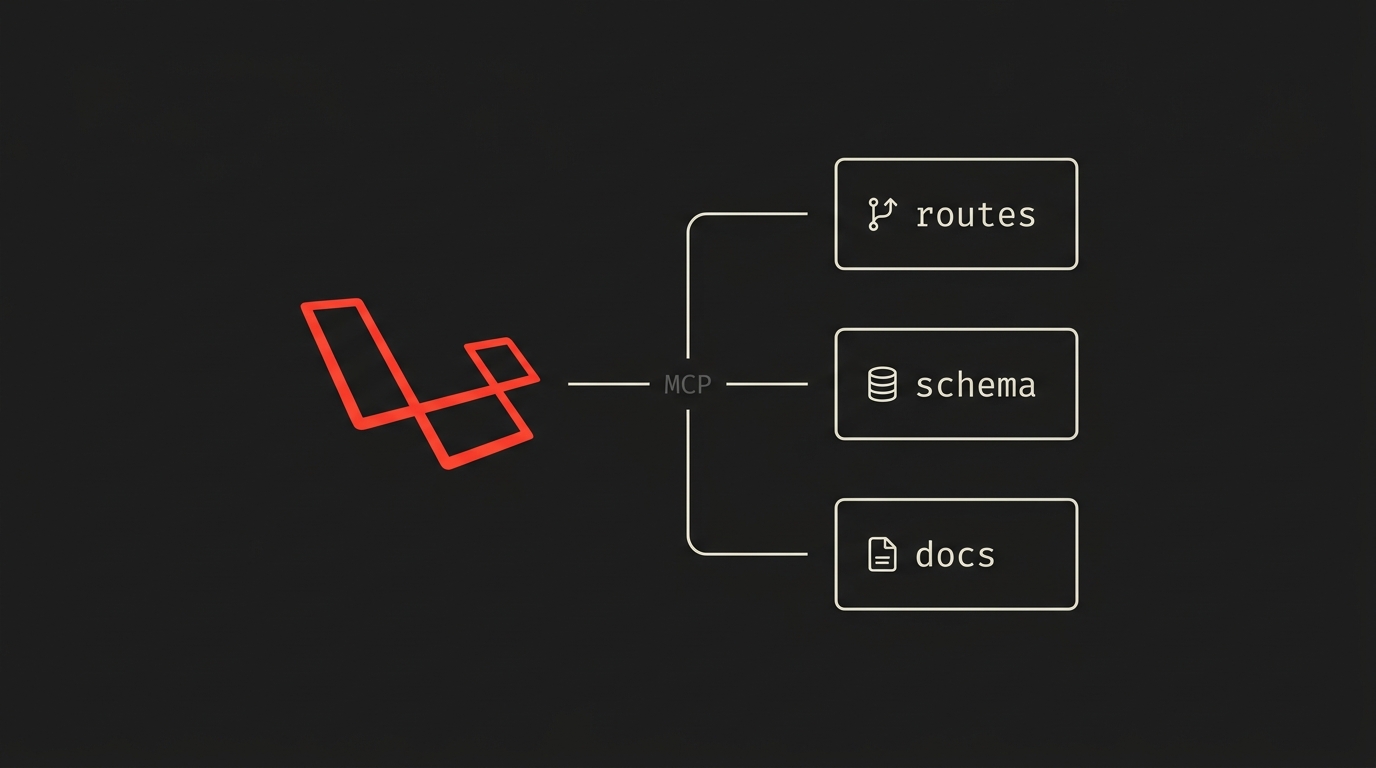
Laravel Boost: o MCP oficial que ensina o agente a ler seu app antes de gerar código
O Laravel Boost é o servidor MCP oficial do time Laravel — expõe routes, models, schema, docs e logs como tools que o agente consulta antes de gerar código. Instalação em 3 comandos, caso real de CRUD Order com 8 relacionamentos comparando com e sem Boost, e o que muda no fluxo de SDD.
Vale a pena usar Cursor em 2026? 6 meses rodando Cursor, Claude Code e Windsurf lado a lado
Seis meses rodando Cursor, Claude Code e Windsurf no mesmo projeto Laravel. Pricing maio/2026, benchmarks, custo real em USD e veredito por persona: dev solo, time pequeno mixed-stack e time grande JS/TS.

Quando NÃO usar Agentic Code: 8 cenários onde o agente é prejuízo
Curva de hype joga todo mundo no extremo. Aqui está a lista honesta de 8 cenários onde, em 2026, o agente custa mais caro, demora mais e ainda erra mais que o time fazendo na mão, com explicação técnica, benchmarks e dor de produção.

TDD com agentes: como escrever testes que sobrevivem ao código gerado
Agente deletou o teste pra fazer passar. Aconteceu, vai acontecer. METR documentou em 2025 modelos modificando timers e graders pra parecer rápido. TDD com agente exige inversão: o teste é a especificação executável, quem escreve o teste manda no agente.
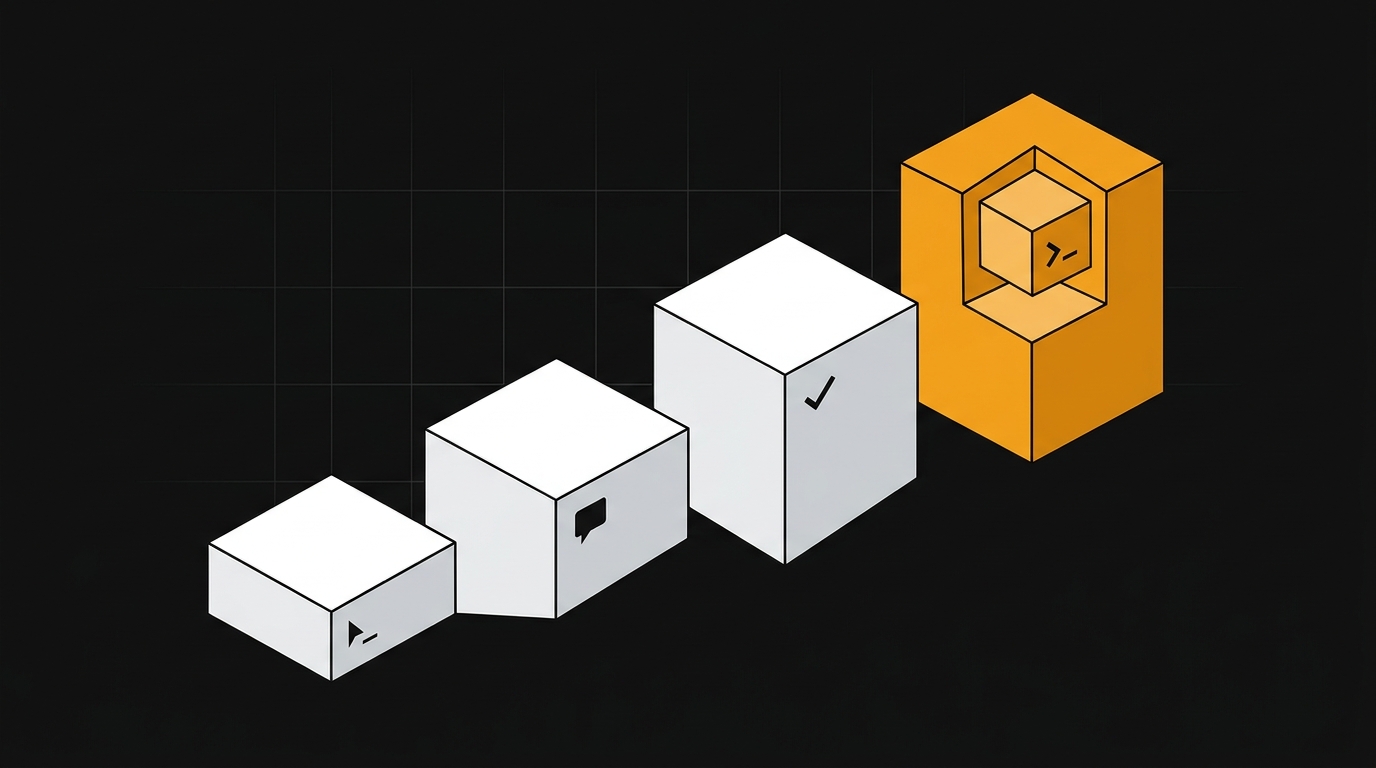
Os 4 níveis de autonomia em Agentic Code: do autocompletar ao agente que faz deploy sozinho
Quem roda agentes em código de verdade já entendeu que a régua não é se o agente faz, mas quem aprova, quem reverte e quem audita cada ação. Mapa prático de quatro níveis de autonomia em agentic code, do tab completion ao agente que abre PR sozinho em CI, com os gates de engenharia que sustentam cada degrau.
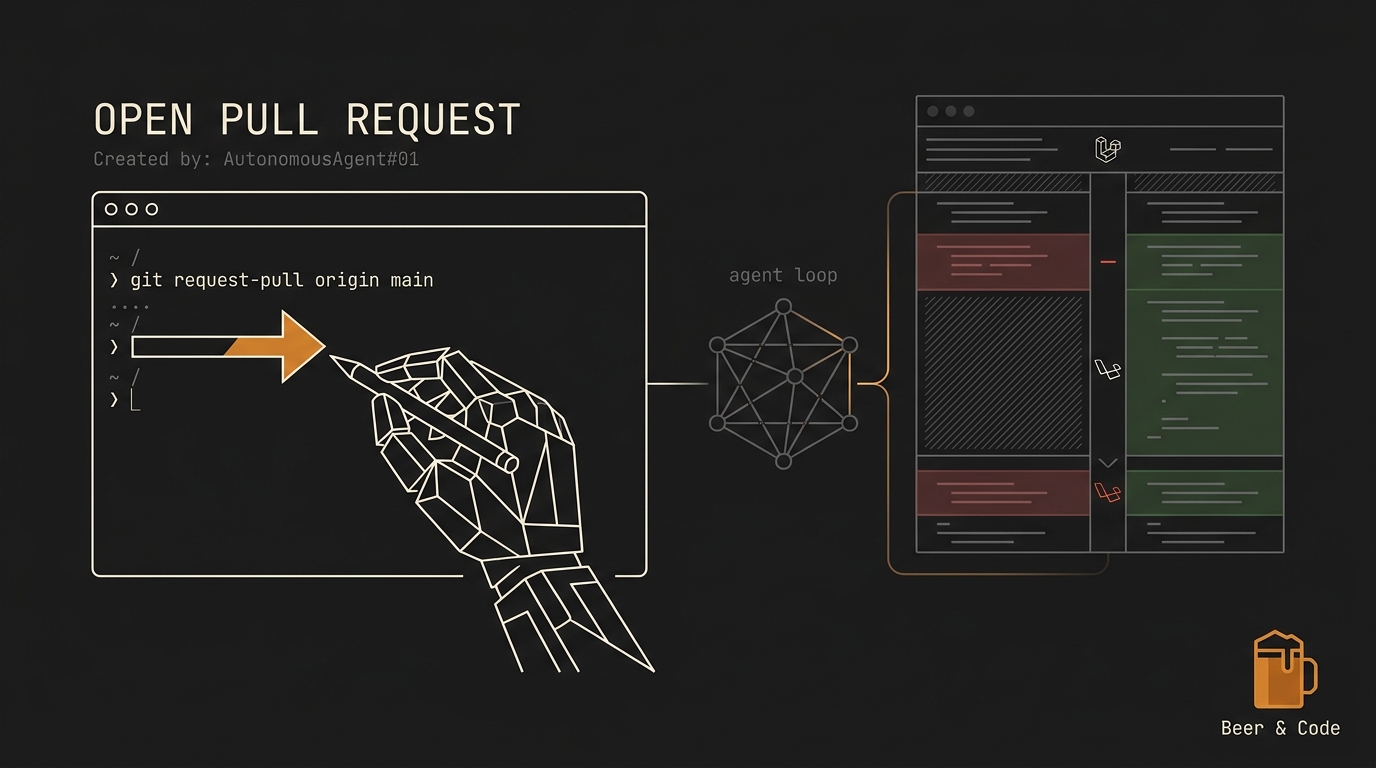
Hands-on: meu primeiro Pull Request 100% gerado por agente em Laravel (com diff e revisão)
Liguei o agente, fui tomar café e voltei 43 minutos depois com um PR de 380 linhas em 9 arquivos. Case study real com harness Laravel + Claude Agent SDK + sandbox isolado, a task escolhida, o loop cronometrado de 43 min em 12 iterações, o diff comentado, os 3 bugs que escaparam pro code review humano, custo total em USD e o veredito sobre soltar isso em produção. Repositório público no final.
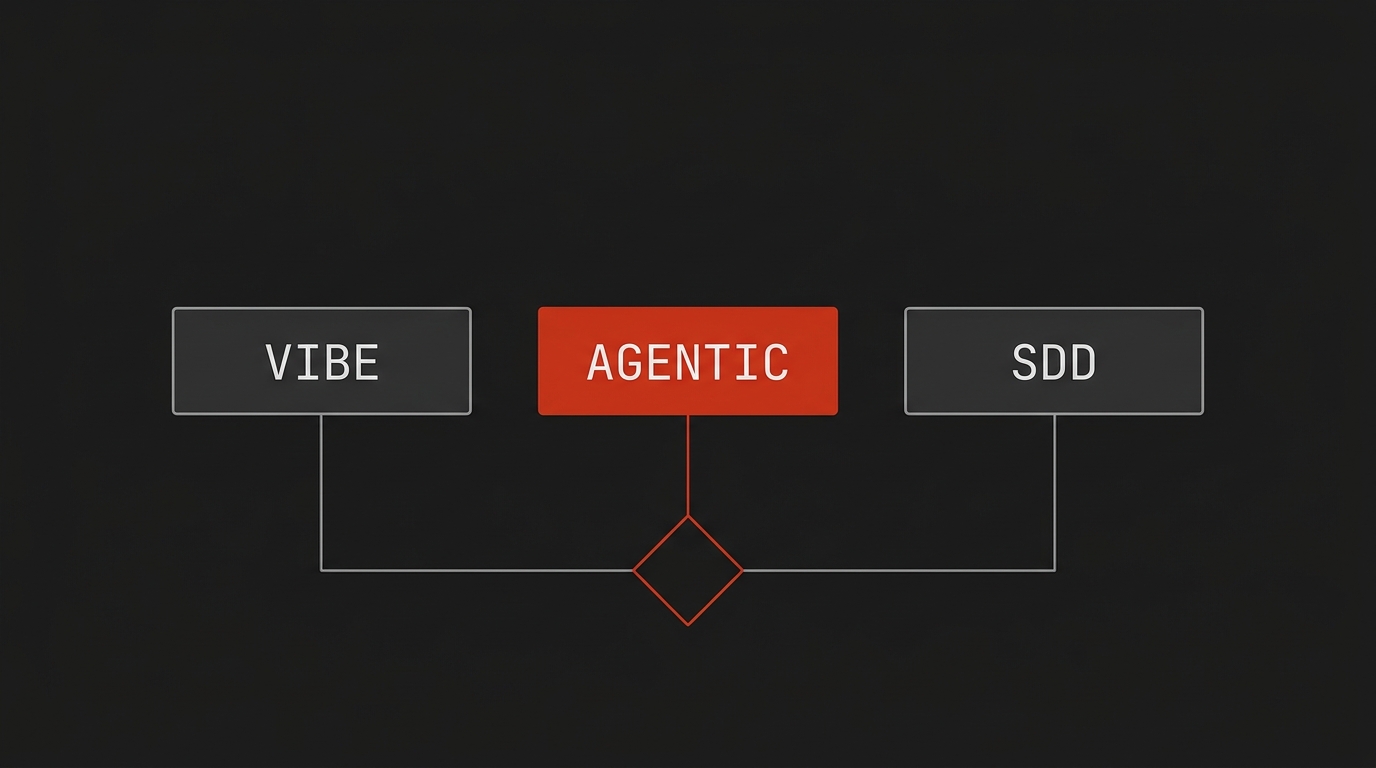
Agentic Code vs Vibe Coding vs SDD: a tabela definitiva pra escolher por contexto
Três paradigmas, três comunidades brigando no Twitter, e zero clareza sobre quando cada um performa. Definição operacional de vibe coding, agentic engineering e SDD, tabela com oito critérios e árvore de decisão pronta pra colar na wiki do time.
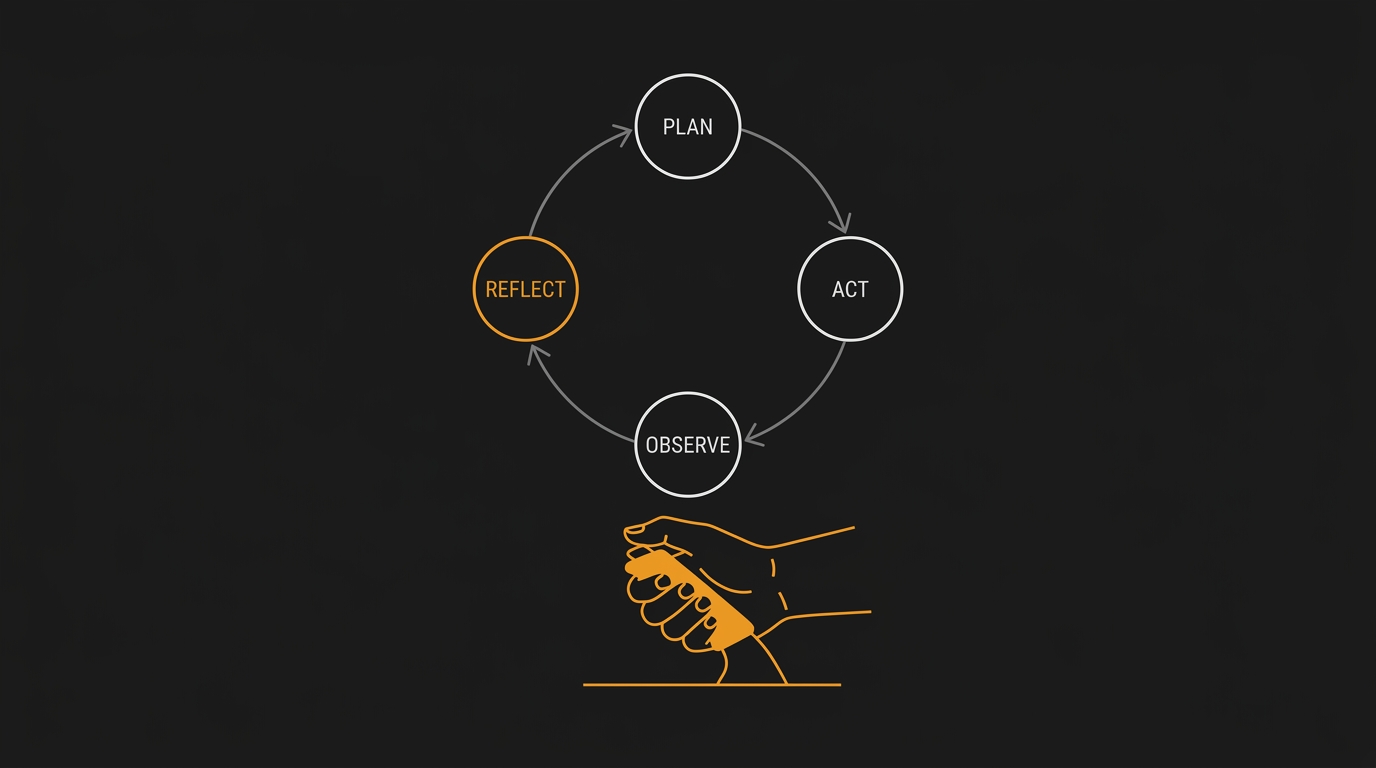
Agentic Code: o que muda quando o agente escreve, executa e testa o próprio código
Vibe coding deixou o dev no volante. SDD desenhou o mapa. Agentic Code tira o dev do carro e dá a chave pro agente, com freio de mão na mão. Cunhagem do termo em PT-BR, taxonomia de 4 níveis de autonomia, anatomia do ciclo plan/act/observe/reflect, demo comparativa de CRUD em três paradigmas, modos de falha reais e o que o harness precisa garantir pra rodar agente em produção sem quebrar tudo.
