Quando NÃO usar Agentic Code: 8 cenários onde o agente é prejuízo

Tem um movimento engraçado acontecendo. Dois anos atrás, dev sênior torcia o nariz pra IA. Hoje, mesmo dev abre Claude Code pra trocar um if que ia levar 30 segundos no editor.
O pêndulo passou do ponto.
Agentic code é uma ferramenta absurda, mas é ferramenta. Tem cenário onde ela acelera 10x. E tem cenário onde ela é prejuízo direto: custa mais caro, demora mais e ainda erra mais que você fazendo na mão. A diferença entre dev sênior e dev que ainda acha que IA é mágica está exatamente em saber identificar qual é qual antes de digitar o prompt.
Este post é a lista honesta. Oito cenários onde, no estado atual da tecnologia em 2026, ligar o agente é a escolha errada — e a explicação técnica do porquê, com benchmarks e dor de produção, não opinião.
TL;DR
- O que é: um contraponto técnico ao hype agêntico, listando 8 cenários onde rodar agente custa mais do que entrega.
- Para quem: dev que já usa Claude Code, Codex, Cursor ou qualquer agente em loop e quer parar de queimar token à toa.
- Régua geral: se a tarefa é curta, crítica em performance, mal documentada, irreversível ou exige modelo mental novo na sua cabeça — o agente provavelmente piora a vida.
- Fonte central: AI Agentic Programming: A Survey (arXiv, 2025) + relatos de produção compilados ao longo do post.
O contexto: por que esse post existe
A curva de adoção de agentic code virou religião. Time inteiro acha que precisa rodar Claude Code pra qualquer coisa, senão "não está fazendo engenharia moderna". Ao mesmo tempo, surgiu uma literatura sólida documentando onde esses sistemas falham.
A pesquisa acadêmica é clara: benchmarks atuais focam em "small, self-contained problems" e são pesadamente viesados pra Python, deixando "statically typed or domain-specific languages, such as C++ or Rust" no escuro (arXiv 2508.11126). Em legado, o problema é estrutural — o estudo da CodeScene sobre refatoração agêntica mostrou que a média de Code Health do mercado é 5,15 numa escala de 10, enquanto o threshold seguro pra IA modificar é 9,4. Ou seja: o código que você tem hoje não está pronto pra o agente mexer sem supervisão obsessiva.
E no custo, Jon Schubert documentou um agente gastando 47 iterações num ALTER TABLE, transformando um problema de 50 centavos numa conta de 30 dólares em tokens — e sprint preso em loop saindo a 10x o orçamento previsto. Nada disso aparece nos threads de "vibe coding" do Twitter, mas aparece no fechamento do mês.
Com esse pano de fundo, vamos aos 8 cenários.
Os 8 cenários onde agente é prejuízo
1. Tarefa de 5 minutos onde o setup do agente já custa mais
Trocar um literal. Renomear uma variável. Ajustar um where numa query. Acrescentar uma chave no array de config.
O agente tem custo fixo de overhead: você descreve o que quer, ele lê o contexto, ele propõe, você revisa o diff, valida, aceita. Mesmo no melhor caso, isso bate 2–3 minutos. Numa tarefa que ia levar 30 segundos no editor com find/replace, você acabou de pagar uma taxa de complexidade pra fazer mais lento.
Pior: o agente lê arquivos vizinhos, gasta token de contexto, e às vezes "decide" refatorar coisas adjacentes que ninguém pediu. O paper da arXiv chama isso de "unnecessary out of scope edits" — e é exatamente o tipo de mudança que ninguém vai revisar com atenção, porque o PR é "só renomeação".
Regra prática: se você consegue descrever a mudança em menos tempo do que faria ela mesma, faça ela mesma.
2. Algoritmo crítico de performance, onde o compilador faz melhor
LLM gera código que parece idiomático e roda. Não gera código vetorizado, cache-aware, com layout de memória otimizado pra branch predictor. Para hot loops, kernels, parsers de alta vazão, código numérico — o compilador moderno e a literatura de otimização batem o agente sem esforço.
Pior: o agente costuma "regredir" código performático pra forma mais legível, porque legibilidade é o que aparece no corpus de treino. Você pode terminar com uma for clássica no lugar de uma SIMD intrinsics, e descobrir só quando o p99 abrir.
A pesquisa documenta esse viés: "Generic agents often struggle in domain-specific environments such as embedded systems, high-performance computing, optimization, or formal software verification" (arXiv 2508.11126).
Regra prática: se a tarefa é "fazer essa função rodar 3x mais rápido", o caminho é profiler + literatura + experimento controlado. Não é prompt.
3. Legado sem testes, onde o agente sangra rápido
Esse é o mais brutal. Codebase com 12 anos, regras de negócio espalhadas, suíte de testes que cobre 4% do código (ou nenhum). Você manda o agente "refatorar" ou "adicionar feature X em ordem".
Como ele valida? Não tem como. O agente faz um diff de 800 linhas, alega que "funciona", e você passa duas semanas debugando o bug sutil que ele introduziu na regra fiscal do estado de Goiás que ninguém documentou.
A CodeScene mediu isso: agentes sem guardrails fazem 3x mais refatorações que humanos, mas a maioria é "shallow" — renomear variável em vez de quebrar método. Os ganhos estruturais somem, mas o risco de regressão fica. E como o paper acadêmico aponta: "lack of tests makes correctness very hard to assert" (CodeScene).
Regra prática: sem testes, primeiro escreva os testes — você, com o agente como assistente de leitura. Só depois autorize mudanças estruturais.
4. Domínio sem documentação pública
Modelos aprendem do que está na web. Toolchain interna, DSL proprietária, framework legado de banco brasileiro, API privada de parceiro, padrão arquitetural que só tem nos comentários daquele commit de 2014 — nada disso está no corpus.
O que o agente faz nesse caso? Alucina com confiança. Inventa funções que não existem, "lembra" de assinaturas que combinam com bibliotecas parecidas, propõe padrões que fariam sentido em Python mas não na sua DSL.
O paper documenta o problema central: "fixed context windows, limiting their ability to reason over long histories" (arXiv) — você não consegue carregar toda a documentação interna no contexto e esperar coerência ao longo de um loop de 30 passos.
Regra prática: antes de soltar agente em domínio novo, ou você indexa a documentação interna num RAG decente, ou você assume que vai revisar cada linha como se fosse código de estagiário no primeiro dia.
5. Compliance pesado, onde a auditoria é por linha
Sistema bancário sob BACEN. Saúde sob LGPD + RDC. Pagamento sob PCI-DSS. Setor regulado tem uma característica: alguém vai abrir o PR e justificar cada linha pra um auditor — interno, externo, ou de um órgão regulador.
Como você explica pro auditor "essa linha foi escrita por um agente que rodou 14 iterações até parar de quebrar o teste"? A rastreabilidade de intenção é parte do controle, não bônus. E LLM não produz rastreabilidade — produz output plausível.
Pior, o paper alerta pra "irreversible actions" e "subtle bugs, propagating unsafe patterns, or violating security constraints" como riscos inerentes a agentes com tool use ativo (arXiv). Num contexto onde a vulnerabilidade vira multa milionária, esse risco é inaceitável.
Regra prática: em compliance pesado, o agente pode sugerir, mas o dev é dono. Cada linha tem nome, intenção documentada e teste que valida. Sem exceção.
6. Migração de schema com dado vivo
Adicionar coluna nullable em tabela vazia: tranquilo. Quebrar users em users + profiles numa base com 80 milhões de registros e replicação ativa: outro jogo.
Migração de schema com dado em produção é uma das tarefas onde "quase certo" significa incidente público. Lock errado segura escrita do app inteiro. Default mal calculado corrompe milhões de linhas. Ordem errada de ALTER numa replicação síncrona derruba a réplica.
E adivinha o que o relato da Medium documentou? Justamente um agente travado em 47 iterações tentando variações de ALTER TABLE, sem entender por que falhava em cada uma (Schubert, 2025). É exatamente o cenário onde o agente persiste por design — ele não tem o modelo mental de "se eu errar, derrubo o sistema". Ele tenta.
Regra prática: migração com dado vivo passa por revisão humana específica, dry-run em snapshot, e janela controlada. Agente é assistente de redação do migration, não de execução.
7. Hot path com SLA agressivo, onde a latência do LLM mata
Esse é diferente dos anteriores: não é sobre escrever código, é sobre embutir um agente no caminho crítico de uma feature em produção.
Em 2026, o Claude Haiku 4.5 — o modelo mais rápido da família — tem TTFT em torno de 597–639ms em prompts médios, com p95 chegando a 612ms (Ganglani, 2026). Some 10–80ms de overhead de gateway por chamada. Em um agente com 5 passos sequenciais, você acabou de adicionar 3–4 segundos ao seu request.
Pra chatbot? Ok. Pra autocomplete em IDE? Já complicou. Pra checkout, autenticação, busca em e-commerce, ranking de feed? Esquece. SLA de 200ms p99 não convive com um loop agêntico de inferência.
Regra prática: se o caso de uso tem orçamento de latência sub-segundo, agente fica fora do hot path. Pré-computa, faz batch, usa fallback determinístico — não chama LLM síncrono.
8. Spike de pesquisa, onde você precisa formar o modelo mental
Última e talvez a mais subestimada. Quando você está atacando um problema novo — biblioteca que nunca usou, paradigma diferente, bug obscuro num sistema distribuído — o objetivo não é "ter código pronto". É construir o modelo mental na sua cabeça.
O agente entrega código que funciona. Você não entende por quê. Na próxima vez que precisar mexer ali, vai pedir o agente de novo, porque o conhecimento não foi seu. Você terceirizou o raciocínio.
E aqui vale o brand do blog: dev bom não é quem copia código que roda. É quem entende o problema, modela a solução e entrega software que funciona no mundo real. Pesquisa exploratória é um dos poucos momentos onde a "lentidão" de fazer manualmente é o produto principal — você está pagando pelo aprendizado, não pelo output.
Regra prática: spikes técnicos são pra você. Use o agente como professor (explicador de conceito, buscador de referência), não como executor.
Como decidir caso a caso
A régua simples, que você pode imprimir e colar na mesa, é:
| Pergunta | Se "sim", não use agente |
|---|---|
| A tarefa leva menos de 5 min no editor? | sim |
| O ganho é dominado por performance microscópica? | sim |
| O código alvo não tem testes que cubram a mudança? | sim |
| A documentação relevante está fora do corpus público? | sim |
| Alguém vai auditar linha a linha? | sim |
| A ação é irreversível em dado de produção? | sim |
| O caminho crítico tem SLA sub-segundo? | sim |
| Você ainda está formando entendimento do problema? | sim |
Marcou uma dessas? Pensa duas vezes. Marcou duas ou mais? Faz na mão, com o agente no máximo como copiloto de leitura.
Isso não é antiagêntico. É engenharia. A mesma engenharia que escolhe quando usar fila assíncrona, quando rodar batch, quando escalar vertical. Ferramenta no contexto certo é alavanca; no contexto errado, é peso morto.
Limitações deste post
- Tudo aqui é estado da arte de maio de 2026. Modelo mais rápido amanhã, custo cai 90% ano que vem (Belitsoft já documentou), e cenários 1 e 7 podem voltar a ser viáveis. A régua técnica permanece; os limiares mudam.
- A lista é generalista. Sua stack pode ter idiossincrasias que tornam um cenário pior (ou melhor). O critério final é benchmark do seu próprio time, não anedota.
- Nada aqui invalida usar agente bem. Existe um vasto espaço entre "ignorar IA" e "rodar Claude Code no
ifde 30 segundos". É exatamente esse espaço que o time inteligente está mapeando.
FAQ rápido
"Mas o agente acerta a maior parte do tempo!" Acerta. Acerta também muito do que humano sênior acerta. O problema não é a taxa de acerto, é o custo do erro quando ele acontece — e como você sabe que aconteceu. Em compliance, legado e migração, "quase sempre certo" é uma frase que paga indenização.
"Não é só usar modelo melhor pra resolver isso?" Modelo melhor reduz alucinação, não elimina. E não muda física: domínio sem documentação continua sem documentação, hot path com SLA continua com SLA, código legado continua sem testes. A ferramenta melhor não troca os fundamentos.
"Como medir se vale a pena no meu caso?" Métricas mínimas: custo de token por feature, tempo até PR mergeado, taxa de regressão pós-merge, número de iterações médias do agente por tarefa. Se você não mede, você está sentindo — e sentimento é o pior insumo pra decisão técnica.
"E onde o agente brilha?" Tarefa média (15–60 min de humano), bem especificada, em código com testes, num domínio bem documentado, sem restrição dura de latência. Boilerplate de CRUD, conversão entre formatos, migração de testes legados pra framework novo, geração de stubs, refatoração mecânica com cobertura forte. Esse é o sweet spot — e é um sweet spot enorme. Só não é universal.
Conclusão
Adotar agentic code com critério é o que separa time que ganha produtividade real de time que paga conta de token sem mover o produto. A pergunta não é "uso agente ou não". É "essa tarefa, hoje, com esse risco, com esse SLA, com essa documentação, ganha algo com o agente — ou ganha mais com 20 minutos do dev sênior?".
Esse tipo de decisão fica muito mais clara quando você opera seu próprio harness em cima do agente — com hooks, guardrails, evals e métricas pra medir custo e qualidade em vez de adivinhar. É exatamente o terreno que destrinchamos no Harness Engineering com Claude Code, workshop ao vivo do Beer & Code sobre como construir e operar um harness próprio, do loop autônomo ao agente em produção.
O próximo dev sênior não é o que usa mais IA. É o que sabe, em cada momento, quando ela é alavanca e quando ela é prejuízo.

{AI Engineer} — apaixonado por Laravel, arquitetura de software e construir produtos com impacto. Compartilho aqui tutoriais, descobertas e reflexões sobre o dia a dia de engenharia.
Você também pode gostar
Agentic Code: o que muda quando o agente escreve, executa e testa o próprio código
Vibe coding deixou o dev no volante. SDD desenhou o mapa. Agentic Code tira o dev do carro e dá a chave pro agente, com freio de mão na mão. Cunhagem do termo em PT-BR, taxonomia de 4 níveis de autonomia, anatomia do ciclo plan/act/observe/reflect, demo comparativa de CRUD em três paradigmas, modos de falha reais e o que o harness precisa garantir pra rodar agente em produção sem quebrar tudo.
Os 4 níveis de autonomia em Agentic Code: do autocompletar ao agente que faz deploy sozinho
Quem roda agentes em código de verdade já entendeu que a régua não é se o agente faz, mas quem aprova, quem reverte e quem audita cada ação. Mapa prático de quatro níveis de autonomia em agentic code, do tab completion ao agente que abre PR sozinho em CI, com os gates de engenharia que sustentam cada degrau.
Agentic RAG: quando o agente decide o que buscar
No RAG clássico a busca acontece sempre. No agentic RAG o agente decide se busca, o que busca e quantas vezes, tratando a recuperação como uma tool. Veja o padrão de código e, principalmente, quando esse poder vale o custo.
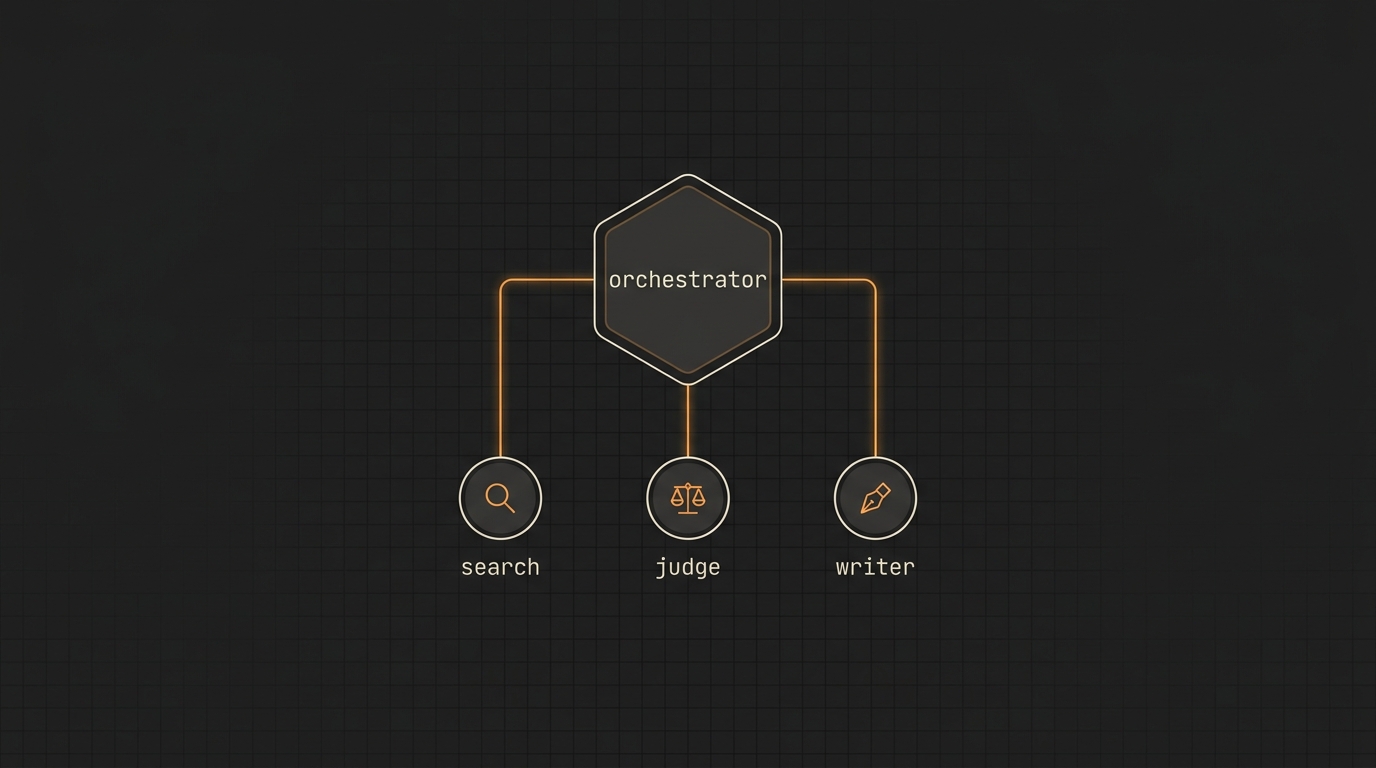
Multi-agent com Claude: separando search, judge e writer (e quando isso é overengineering)
Quando vale a pena quebrar o agente único em sub-agentes especializados (search, judge, writer) e quando isso vira complexidade desnecessária. Padrão de orquestração com Claude, custo real em tokens e quando voltar para single-agent.
