Multi-agent com Claude: separando search, judge e writer (e quando isso é overengineering)
Você empilha 18 tools num único agente. Web search, scraping, ranking, sumarização, geração de markdown, salvar no banco. Tudo no mesmo system prompt. Tudo no mesmo contexto.
Funciona. Até parar de funcionar.
O agente começa a misturar critério de busca com tom de escrita. Alucina ranking. Esquece o que pesquisou três tools atrás. E o token bill começa a doer.
Quando isso acontece, a primeira reação é "preciso melhorar o prompt". Às vezes resolve. Às vezes o problema não é prompt — é arquitetura. É hora de quebrar o agente em sub-agentes especializados.
Neste post a gente vai analisar o padrão search → judge → writer, baseado na arquitetura que a Anthropic descreveu no próprio sistema de Research. Quando vale separar, quando não vale, e quanto isso custa de verdade em tokens.
TL;DR
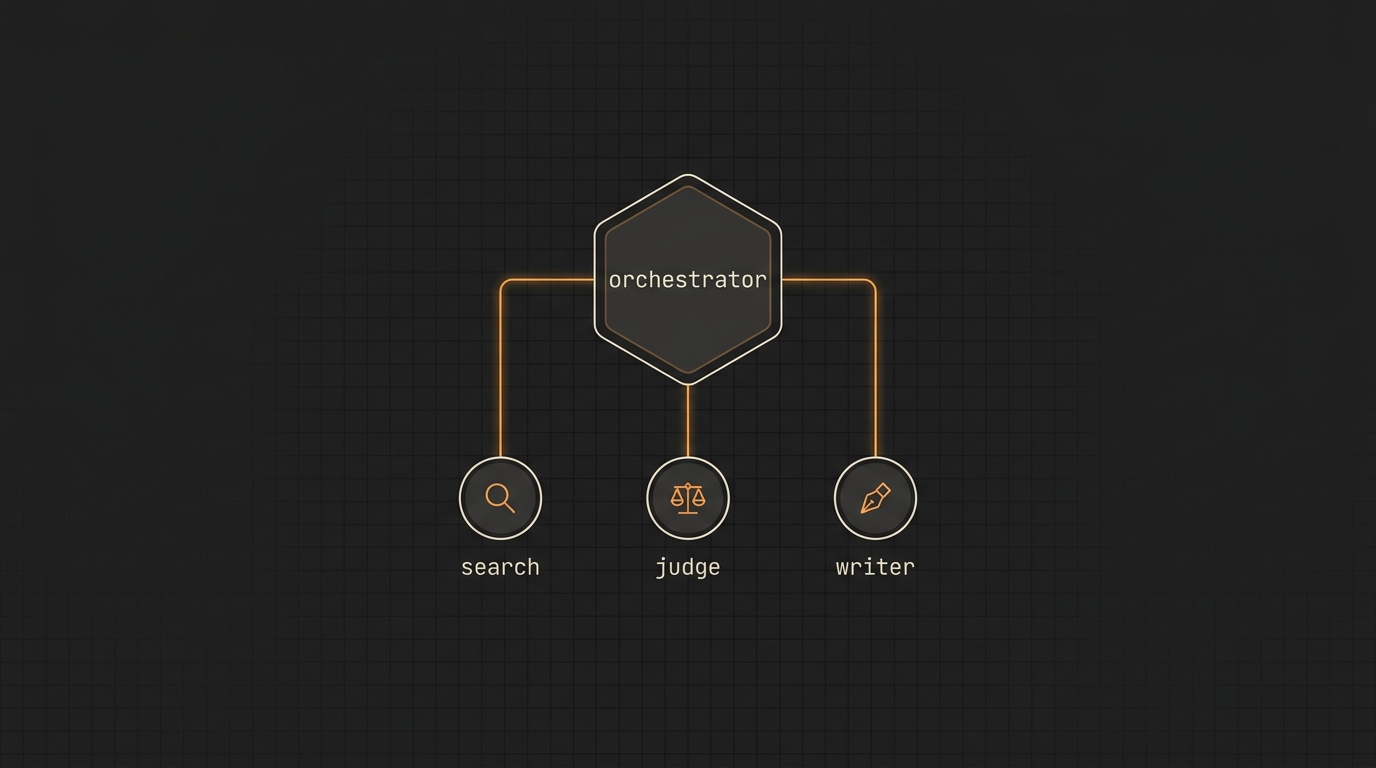
- O que é: padrão multi-agent com três sub-agentes especializados — search, judge e writer — coordenados por um orquestrador.
- Stack/Modelos: Claude Agent SDK, Opus como líder, Sonnet como subagentes.
- Custo/Acesso: API paga; espere ~15x mais tokens que chat e ~3–10x mais que single-agent.
- Link útil: How we built our multi-agent research system.
Por que separar search, judge e writer?
A primeira coisa que precisa ficar clara: multi-agent não é melhor que single-agent. É diferente. E custa mais.
A própria Anthropic é direta sobre isso. No guia de quando usar multi-agent, eles avisam que equipes investiram "months building elaborate multi-agent architectures only to discover that improved prompting on a single agent achieved equivalent results".
Então a pergunta certa não é "deveria ser multi-agent?". É "o que esse sistema sofre que multi-agent resolve?".
Três sintomas reais:
- Poluição de contexto. O agente carrega resultado de busca cheio de ruído pelo resto da conversa. Toma decisão de redação olhando para HTML scrapado.
- Tarefas paralelizáveis. Você precisa pesquisar cinco tópicos independentes. Um agente faz em série. Cinco agentes fazem ao mesmo tempo.
- Especialização de ferramentas. O critério para escolher uma fonte boa é diferente do critério para escrever um parágrafo claro. Um único system prompt tentando otimizar os dois acaba mediano nos dois.
O padrão search → judge → writer ataca os três:
- O search agent mergulha em busca e scraping. Volta com fontes brutas.
- O judge (ou ranker) avalia, filtra, deduplica e ordena. Volta com um shortlist.
- O writer recebe o shortlist e escreve. Não vê HTML. Não decide o que é boa fonte.
Cada um com seu system prompt, seu set de tools e seu contexto. O orquestrador costura tudo.
E sim, isso entrega ganho mensurável. No eval interno de research da Anthropic, "a multi-agent system with Claude Opus 4 as the lead agent and Claude Sonnet 4 subagents outperformed single-agent Claude Opus 4 by 90.2%". Não é overhead à toa.
Mas espera o resto do post antes de sair refatorando.
Pré-requisitos
Antes de cair no código:
- [ ] Conta na Anthropic com chave de API.
- [ ] Python 3.11+ ou Node 20+.
- [ ]
anthropicSDK ou Claude Agent SDK. - [ ] Familiaridade com tool use / function calling.
Não precisa de framework de agente. LangGraph, CrewAI, AutoGen são opcionais. Para o padrão dos três, um orquestrador feito à mão em Python rende e fica mais fácil de debugar.
Mão na massa: a arquitetura mínima
A ideia geral é a do paper que a Anthropic publicou: um lead agent decompõe o pedido em subtasks e dispara subagentes. Cada subagente recebe "an objective, an output format, guidance on the tools and sources to use, and clear task boundaries". E retorna um artefato — não a história inteira do que fez.
┌─────────────────────┐
user query ─►│ lead orchestrator │
└──────────┬──────────┘
│ delega
┌──────────────┼──────────────┐
▼ ▼ ▼
┌─────────┐ ┌─────────┐ ┌─────────┐
│ search │───►│ judge │───►│ writer │
└─────────┘ └─────────┘ └─────────┘
(scrap) (ranqueia) (redige)
Passo 1: o orquestrador
O orquestrador é só um loop que sabe a ordem dos subagentes e o que cada um precisa receber. Não é mágica.
from anthropic import Anthropic
client = Anthropic()
def orchestrate(user_query: str) -> str:
sources = run_search_agent(user_query)
shortlist = run_judge_agent(user_query, sources)
article = run_writer_agent(user_query, shortlist)
return article
Note o que ele NÃO faz: não passa o resultado bruto da search para o writer. Cada handoff é um artefato pequeno e tipado. Esse é o ponto que a maioria das implementações ingênuas erra.
Passo 2: o search agent
System prompt curto, foco em uma única coisa.
SEARCH_SYSTEM = """Você é um agente de busca. Recebe uma query e retorna
uma lista de fontes relevantes em JSON. Cada item: {url, title, snippet}.
Não escreva análise. Não classifique. Só colete.
Use a tool web_search com queries amplas primeiro, depois afunile."""
def run_search_agent(query: str) -> list[dict]:
response = client.messages.create(
model="claude-sonnet-4-6",
max_tokens=4096,
system=SEARCH_SYSTEM,
tools=[{"type": "web_search_20250305", "name": "web_search"}],
messages=[{"role": "user", "content": f"Pesquise: {query}"}],
)
return extract_sources(response)
A Anthropic recomenda o padrão wide-to-narrow: "start with short, broad queries, evaluate what's available, then progressively narrow". Você instrui isso no system prompt e o subagente segue. É muito mais barato fazer assim do que rodar 12 queries hiper-específicas que retornam pouco.
Passo 3: o judge
O judge não precisa de tools. Recebe a lista, devolve a lista filtrada e ordenada.
JUDGE_SYSTEM = """Você avalia fontes para um post técnico.
Critérios:
1. Oficialidade (docs do lab > blog terceiros > medium random).
2. Atualidade (priorize 2025–2026).
3. Profundidade (paper/changelog > thread de Twitter).
Retorne um JSON com até 5 fontes ordenadas, cada uma com:
{url, title, why_it_matters, score (0-10)}.
Descarte stock-photo, conteúdo SEO genérico e fontes sem autor."""
def run_judge_agent(query: str, sources: list[dict]) -> list[dict]:
response = client.messages.create(
model="claude-sonnet-4-6",
max_tokens=2048,
system=JUDGE_SYSTEM,
messages=[{
"role": "user",
"content": f"Query: {query}\n\nFontes:\n{json.dumps(sources)}",
}],
)
return parse_shortlist(response)
Esse subagente parece tonto, mas faz três coisas grandes: descarta lixo antes de chegar no writer, salva token (porque o writer não vai ver as fontes ruins) e te dá um log auditável de POR QUE algo entrou no post.
Passo 4: o writer
O writer é o mais "criativo", e por isso é o que MENOS pode ver contexto bruto. Ele recebe só a shortlist + um briefing.
WRITER_SYSTEM = """Você escreve posts técnicos. Tom direto, frases curtas,
sem hype. Cite fontes inline em markdown: [texto](url).
NÃO invente fontes. Se algo não está no shortlist, não pode ir no post."""
def run_writer_agent(query: str, shortlist: list[dict]) -> str:
briefing = "\n".join(
f"- {s['title']} ({s['url']}): {s['why_it_matters']}"
for s in shortlist
)
response = client.messages.create(
model="claude-opus-4-7",
max_tokens=8192,
system=WRITER_SYSTEM,
messages=[{
"role": "user",
"content": f"Tema: {query}\n\nFontes aprovadas:\n{briefing}",
}],
)
return response.content[0].text
Repare que o writer é o único que usa Opus aqui. Search e judge usam Sonnet. Esse é o padrão que a Anthropic descreve: lead/escritor em modelo top, especialistas em modelo mais barato.
Padrão de handoff: passe artefato, não conversa
Esse é o insight que separa multi-agent que funciona de multi-agent que vira spaghetti. A própria Anthropic escreveu sobre o problema do "telefone": cada handoff perde contexto. A solução é não tentar transferir contexto completo. Transfira artefato.
Concretamente:
- Search retorna
list[Source]. ~500 tokens. - Judge retorna
list[ScoredSource]. ~800 tokens. - Writer recebe shortlist + tema. ~1k tokens de input.
Compare com a alternativa ingênua: jogar a conversa inteira do search dentro do writer. Aí você anda de 1k para 15k tokens em input só de uma chamada. Multiplica por execução. Quebra orçamento.
Tutorial te mostra o caminho — no Clã você constrói junto. Aula ao vivo toda semana, projetos reais de Engenharia de IA, ao lado de quem já está em produção.
Entrar no ClãO custo real: tokens, latência, debugging
Hora da conversa adulta. Multi-agent é caro.
Os números da Anthropic, em What we've learned:
- "agents typically use about 4× more tokens than chat interactions".
- "multi-agent systems use about 15× more tokens than chats".
- No eval BrowseComp, "token usage by itself explains 80% of the variance" no resultado.
E outros relatos da própria Anthropic batem com 3–10x mais tokens do que single-agent equivalente.
Traduzindo: se seu agente single hoje gasta R$ 2 por execução, espera entre R$ 6 e R$ 20 no multi-agent equivalente. E mais R$ 30+ se você comparar com chat puro.
Latência também não é grátis. Paralelização ajuda quando você dispara 3–5 search subagentes ao mesmo tempo. Mas o overhead de coordenação (orquestrador esperando, validando, encadeando) pode comer o ganho. Em média você ganha em qualidade, não em tempo.
Debugging é o terceiro custo. Mais agentes = mais pontos de falha. Cada subagente tem prompt próprio, instrumentação própria, eval próprio. Sem observabilidade decente (LangSmith, Weights & Biases, tracing customizado), boa sorte achando por que o writer alucinou um link.
Quando NÃO separar
A Anthropic é cirúrgica nessa parte. Multi-agent é mau ajuste para:
- Tarefas com contexto compartilhado denso. "Most coding tasks involve fewer truly parallelizable tasks than research". Planning + implementação + testes da mesma feature compartilham contexto demais. Quebrar em subagentes só perde informação no handoff.
- Pipelines onde um prompt melhor já resolve. Antes de fazer multi-agent, tenta system prompt mais cirúrgico, few-shot examples e tool descriptions melhores. Custa zero e resolve mais do que parece.
- Tarefas de baixo valor unitário. Se a saída do agente vale R$ 0,50, gastar R$ 5 em multi-agent não fecha conta. A Anthropic é direta: "multi-agent systems require tasks where the value of the task is high enough to pay for the increased performance".
- Real-time / latência crítica. Coordenação entre agentes adiciona segundos. Se o usuário está esperando resposta numa UI síncrona, multi-agent geralmente não é o caminho.
A regra prática que eu sigo: comece com single-agent bem prompted. Só quebre em sub-agentes quando tiver evidência (eval, log, reclamação) de que ESSE single-agent específico está sofrendo de poluição de contexto, falta de paralelismo ou conflito de especialização. "Start with the simplest approach that works, and add complexity only when evidence supports it."
Multi-agent é arquitetura. Não é decoração.
CTA
Se você está construindo IA aplicada de verdade — não autocomplete bonitinho, mas feature que vai pra produção — multi-agent é uma das ferramentas que separa quem entrega de quem só prototipa. E é exatamente esse o nível de engenharia que a gente desenvolve no Clã Beer & Code: arquitetura de agentes, RAG sério, avaliação, custo, deploy. Se quer estar nessa conversa, entra na nossa newsletter ou vem pro Clã.
FAQ rápido
Dá pra fazer isso em PHP/Laravel?
Dá. O padrão é agnóstico de linguagem — orquestrador é um service, cada subagente é uma chamada à API da Anthropic. Prism e o ecossistema de pacotes Laravel para LLM já dão suporte a tool use. A diferença é maturidade do tooling: o ecossistema Python tem mais frameworks prontos para tracing e eval.
Qual o ponto de equilíbrio para valer a pena?
Regra de bolso: se a tarefa é paralelizável, tem mais de 2 fases bem distintas, e a saída vale mais do que ~10x o custo de uma chamada single-agent, multi-agent começa a fazer sentido. Abaixo disso, foca em prompt e tools.
Como debugo um multi-agent que alucina?
Logue input e output de cada subagente como artefato separado. Se o writer alucinou um link, a primeira pergunta é "esse link estava no shortlist?". Se sim, problema do judge. Se não, problema do writer ignorando instrução. Com handoffs tipados (JSON com schema), esse debug fica trivial.
E se um subagente falha no meio?
Trate como qualquer chamada externa instável: retry com backoff, timeout duro, fallback para resposta degradada. O orquestrador é quem decide. Não delegue resiliência para os subagentes.
Conclusão
Multi-agent não é silver bullet. É arquitetura, e como toda arquitetura, tem custo. O padrão search → judge → writer funciona quando você tem busca pesada, ranking não-trivial e redação que precisa ficar limpa de contexto sujo. Não funciona quando o que você tem é um pipeline curto que um prompt melhor já resolveria.
O próximo passo dessa tecnologia é orquestração que aprende sozinha quando dividir e quando manter junto. Já tem pesquisa apontando para isso na Anthropic. Por enquanto, a decisão é sua. Mede primeiro, refatora depois.
Se curtiu, dá uma olhada no nosso post sobre agentes em produção e como a gente trata avaliação e custo nesse tipo de sistema.

{AI Engineer} — apaixonado por Laravel, arquitetura de software e construir produtos com impacto. Compartilho aqui tutoriais, descobertas e reflexões sobre o dia a dia de engenharia.
Conteúdo é o que não falta. Falta quem desembaralhe: o que importa agora é como implementar do jeito certo. No Clã você tem isso ao vivo, toda semana, com quem já filtrou o ruído.
Entrar no Clã