Da Indexação Tradicional à Era dos Embeddings: A Evolução da Busca no Google
🧱 1. Como Tudo Começou: Indexação e Palavras-Chave
No início dos mecanismos de busca, a indexação era relativamente simples: o Google examinava páginas da web, extraía palavras-chave e armazenava esse conteúdo em um índice para recuperar posteriormente. Esse processo de indexação tradicional baseava-se principalmente em correspondências textuais e frequência de termos para fornecer resultados.
Nessa era, as páginas eram classificadas por páginas de links, relevância estatística e palavra-chave — um sistema eficaz, porém limitado na compreensão do significado semântico por trás das consultas.
🔍 2. Mudanças Algorítmicas Importantes
Com o tempo, o Google implementou várias atualizações que tornaram sua indexação e entendimento de conteúdo muito mais sofisticados:
- Hummingbird (2013): marcou um avanço significativo, pois passou a interpretar as consultas de forma mais contextual, em vez de focar apenas em palavras isoladas.
- RankBrain, BERT e MUM: algoritmos focados em entender linguagem natural e contexto, permitindo que consultas mais complexas fossem processadas de maneira mais intuitiva.
- Knowledge Graph: uma base de conhecimento que ajuda o Google a entender entidades, conceitos e relações entre elas, elevando a compreensão semântica.
Essas atualizações mudaram o foco da indexação de "ocorrências de palavras" para "intenção e significado".
🧠 3. Semântica e a Chegada dos Embeddings
Com o avanço do Processamento de Linguagem Natural (NLP) e modelos de IA, a forma de representar e indexar conteúdo evoluiu para algo muito mais profundo: embeddings.
🔹 O que são embeddings? São representações numéricas de textos (palavras, frases, documentos) em espaços vetoriais de alta dimensão — onde a distância entre vetores representa semelhança de significado.
🔹 Por que isso importa? Em vez de apenas encontrar páginas que contenham as mesmas palavras que você digitou, as buscas agora podem comparar o significado por trás dos termos e recuperar conceitos semanticamente relacionados, não apenas correspondências literais.
Essa evolução torna possível que o Google e outras ferramentas (como assistentes de IA ou motores de busca corporativos) façam uma interpretação mais humana das consultas — entendendo contexto, intenção e relações entre entidades.
📊 4. O Impacto no SEO e no Conteúdo Digital
Todo esse avanço significa que a indexação não é mais sobre "ter X palavras-chave" colocadas estrategicamente. Trata-se de:
- Compreender a intenção do usuário e responder com conteúdo verdadeiramente útil;
- Criar conteúdo rico em contexto, bem estruturado e informativo;
- Preparar seu site para uma nova era onde a busca semântica e embeddings determinam qualidade e relevância.
🔮 5. O Futuro da Busca
A tendência é que o Google continue integrando ainda mais técnicas de aprendizado de máquina e representação semântica em seus algoritmos, aproximando a experiência de busca do que hoje vemos com IA generativa e contextos personalizados.
A jornada da indexação do Google — desde simples correspondências de palavras-chave até representações semânticas com embeddings — é uma transformação profunda que influenciou o SEO, o comportamento do usuário e a forma como consumimos informação digital. Entender essa evolução ajuda criadores de conteúdo a se adaptarem e prosperarem na web de hoje.
📅 24 & 25 de Janeiro — Laravel Lab Vamos construir juntos um Planner de Carreira IA-First completo, usando agentes de IA para traçar caminhos profissionais reais — e mostrar como a stack de 2026 funciona de verdade no mundo real.
🎯 Este é o tipo de projeto que vai te tirar do básico e te colocar no centro da inovação.

{AI Engineer} — apaixonado por Laravel, arquitetura de software e construir produtos com impacto. Compartilho aqui tutoriais, descobertas e reflexões sobre o dia a dia de engenharia.
Você também pode gostar

Como Implementar Busca Semântica no Laravel com Embeddings e PostgreSQL (PGVector)
Neste post vamos explicar passo a passo como você pode transformar a busca da sua aplicação Laravel em algo que entenda o significado por trás das consultas, utilizando embeddings e a extensão pgvector do PostgreSQL para realizar buscas por similaridade semântica diretamente no banco de dados

O que é embedding — e por que sua busca semântica devolve resultado errado
Busca semântica devolvendo resultado sem nexo? O problema quase nunca é o banco vetorial — é o embedding. Entenda o que é embedding e conserte os 3 pontos onde a busca por similaridade quebra: modelo, normalização e chunking.
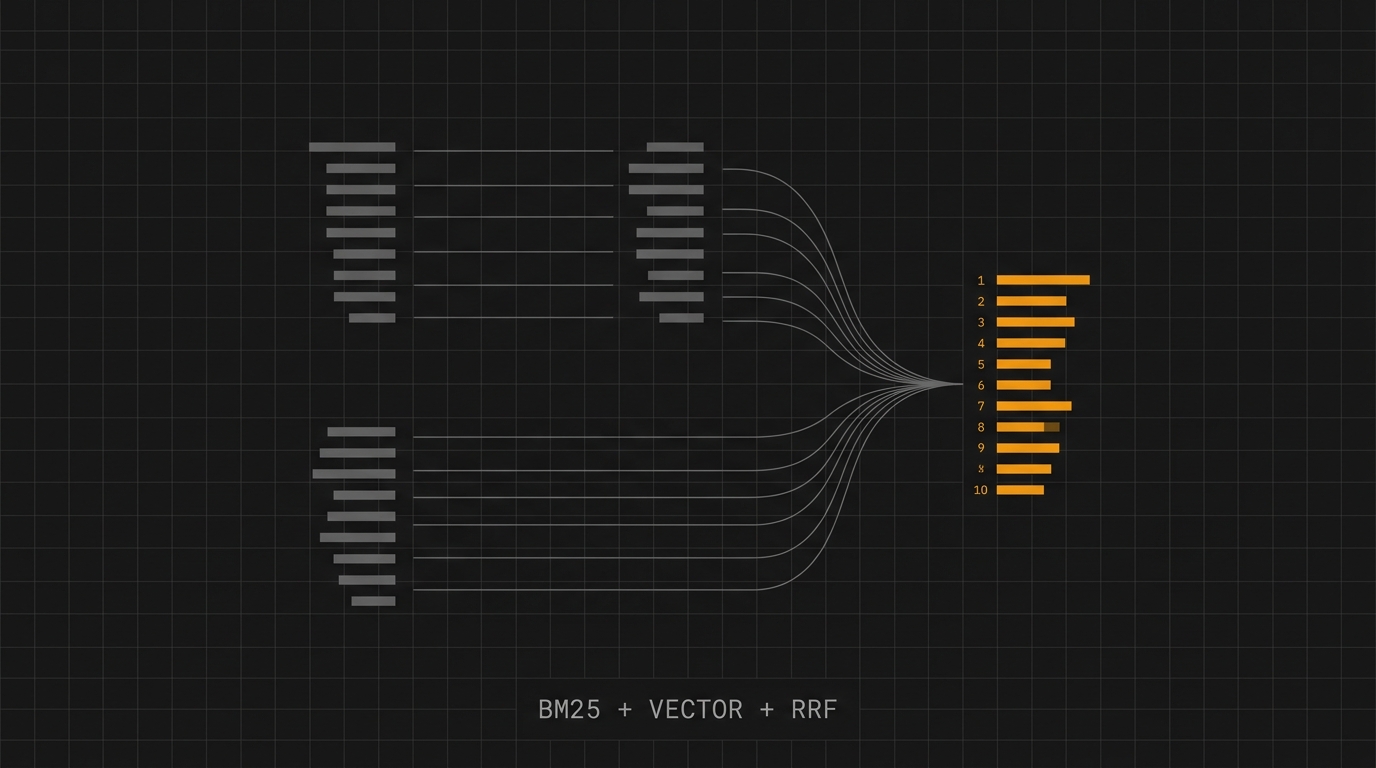
Busca híbrida: a receita BM25 + vetor + RRF que resolve SKU, part-number e semântica
Embedding puro confunde "RX-7000" com "RX-5000". BM25 puro perde sinônimos. A receita certa é rodar os dois em paralelo e fundir os rankings com Reciprocal Rank Fusion. Neste post, a fórmula que sustenta tudo isso, o pipeline completo em Elasticsearch e como aplicar em catálogo de produto que mistura SKU, part-number e busca semântica.
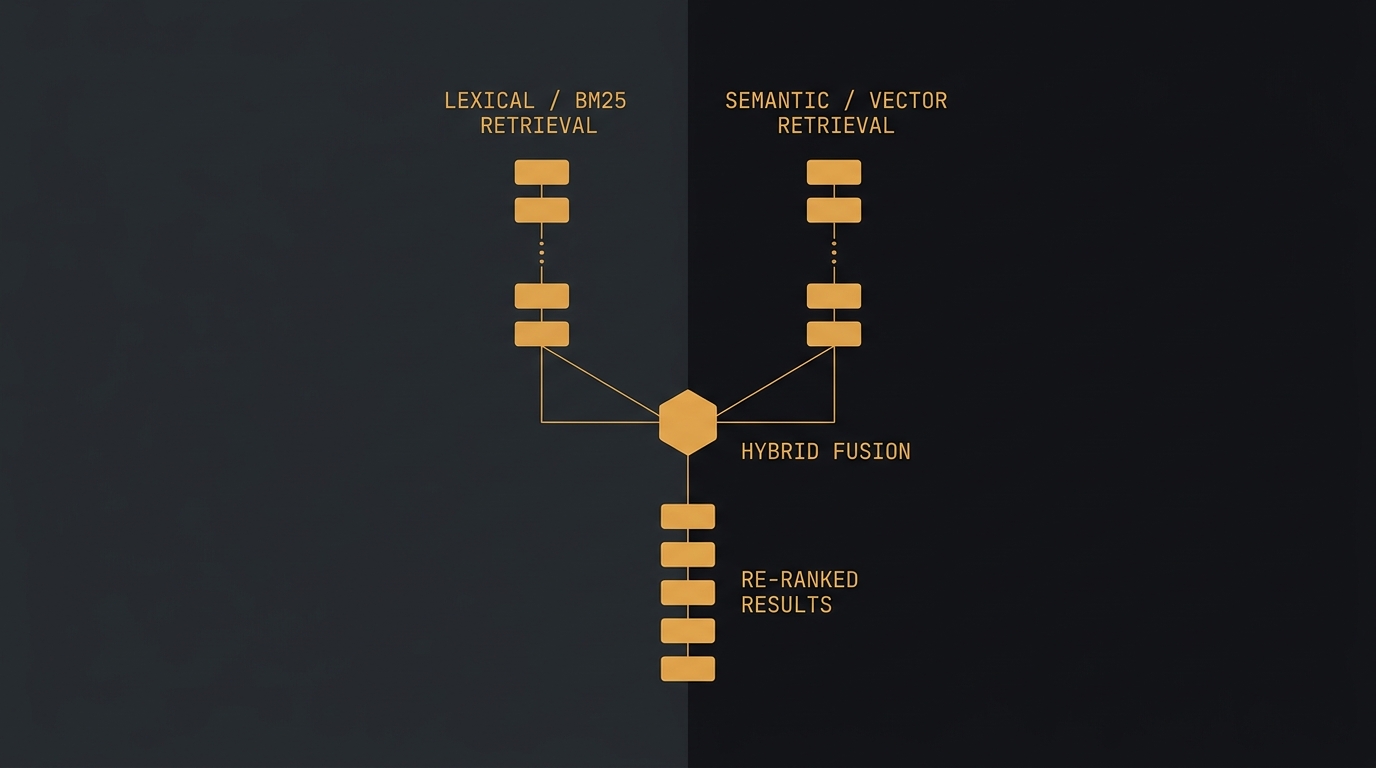
RAG híbrido na prática: BM25, embeddings e reranker
Embedding sozinho erra mais do que você imagina. Veja como combinar busca lexical (BM25), busca semântica e um reranker cross-encoder para subir a qualidade do RAG em produção, com código em Python e LangChain.
