Engenharia de IA não é Data Science: 7 diferenças que separam disciplina de hype
Engenharia de IA não é Data Science: 7 diferenças que separam disciplina de hype
Recrutador chama as duas de "vaga de IA". CTO que confunde uma com a outra paga seis meses de retrabalho.
Foundation model virou commodity. RAG, agentes e eval harness saíram do paper e entraram na produção. E mesmo assim o mercado ainda joga "data scientist" e "AI engineer" no mesmo balde, como se fosse a mesma cadeira com nome novo.
Não é. São disciplinas diferentes, com ferramentas diferentes, métricas diferentes, e quem migra também é diferente. Esse post põe lado a lado as sete diferenças que mais importam — pra dev que tá decidindo carreira, pra CTO que tá montando squad, e pra quem cansou de ver vaga de "engenheiro de IA" pedindo SAS, Tableau e fine-tuning na mesma JD.
TL;DR
- O que muda: AI engineering é construir sistema em volta de foundation model. Data science é extrair insight de dado e treinar modelo do zero.
- Métricas: DS olha AUC, F1, precision. AI engineer olha pass rate em eval, latência p95, custo por mil tokens.
- Stack: DS é notebook + sklearn + MLflow. AI engineer é API client + harness + vector DB + observabilidade.
- Quem migra mais rápido: backend dev, não data scientist.
- Referência principal: AI Engineering, Chip Huyen, O'Reilly 2025.
De onde vem a confusão
Em 2018, IA aplicada era praticamente 100% data science. Você coletava dado, limpava, fazia feature engineering, treinava modelo, avaliava com AUC, jogava no MLflow e rezava pra que o modelo aguentasse drift em produção.
Aí chegaram os foundation models prontos via API. Claude, GPT, Gemini. Funcionando bem em texto, código, imagem, áudio, fora da caixa, sem precisar de GPU própria. A pergunta deixou de ser "como eu treino um modelo pra esse problema?" e virou "como eu construo um sistema que usa um modelo pronto pra resolver esse problema, em produção, sem queimar dinheiro?".
Chip Huyen explica isso com clareza no livro AI Engineering: a engenharia de IA começa com uma ideia de produto e só depois desce pra dado e modelo, enquanto ML engineering tradicional fazia o caminho inverso, partindo do dado pra chegar no produto. É a inversão da seta.
O recrutador não acompanhou. A vaga "Engenheiro de IA" virou um Frankenstein que pede sklearn, transformers, fine-tuning, RAG, deploy em GCP, Power BI e estatística inferencial. Tudo na mesma JD. Tudo errado.
1. Foco do trabalho: modelo vs sistema
Pro data scientist, o modelo é o entregável. Você passa semanas ajustando feature, hiperparâmetro, função de loss. Quando o modelo bate o baseline, o trabalho terminou — alguém de MLE empacota e sobe.
Pro AI engineer, o modelo é commodity. Claude 4.7, GPT-5, Gemini 3 — você troca o nome no .env e segue a vida. O que sobra é todo o resto: retrieval, contexto, prompt, tool calling, fallback, cache, eval set, observabilidade, retry, rate limit, custo. O modelo é uma peça do sistema, não o sistema.
Não é menos técnico. É técnico em outro lugar.
2. A métrica de sucesso
Data scientist conversa em AUC, F1, precision, recall, calibration error. Métricas que funcionam bem em classificação binária com classes balanceadas, onde você quer comparar dois modelos sem se prender a um threshold único.
AI engineer conversa em pass rate de eval set, latência p95 e p99, custo por mil tokens, taxa de tool call certo, taxa de alucinação. AUC quebra em LLM por uma razão simples: o sistema cospe decisão dura, não probabilidade calibrada. Como aponta um post recente da Galileo, em sistemas agênticos o ROC colapsa em um ou dois pontos não triviais — a AUC fica degenerada, ou indefinida.
A Anthropic resume o ponto num parágrafo: quando você tem eval, ganha de graça baseline e regressão — latência, uso de token, custo por tarefa e taxa de erro viram dashboard rodando contra um banco estático de tarefas. Eval virou o painel. Não é AUC.
3. A stack
Data scientist abre o Jupyter, importa pandas, sklearn, statsmodels. Roda EDA, treina, salva no MLflow ou no W&B. Stack maduro, vinte anos de literatura, comunidade gigante.
AI engineer monta outra coisa:
from anthropic import Anthropic
import chromadb
client = Anthropic()
collection = chromadb.PersistentClient().get_collection("docs")
def answer(question: str) -> str:
chunks = collection.query(query_texts=[question], n_results=5)
context = "\n\n".join(chunks["documents"][0])
response = client.messages.create(
model="claude-opus-4-7",
system=f"Use apenas o contexto abaixo.\n\n{context}",
messages=[{"role": "user", "content": question}],
max_tokens=1024,
)
return response.content[0].text
Cliente de API, vector DB, sistema de templates de prompt, eval harness rodando em CI, observabilidade com Helicone ou Langsmith, MCP pra plugar ferramenta. A AI Shipping Labs analisou mais de mil descrições de vaga e mostrou que RAG aparece em 35,9% delas e Python em 82,5%. Notebook quase não aparece.
4. O output
Data scientist entrega relatório, dashboard, feature engineering pronta pra outro time consumir, modelo serializado pra um time de MLE colocar no ar. O cliente final do trabalho costuma ser interno — analista de negócio, gerente de produto, executivo.
AI engineer entrega feature em produção. Chat box no app, endpoint que outro serviço chama, agente que abre pull request sozinho, copilot que rascunha e-mail. Tem usuário final batendo no sistema agora. Se cair, abre incidente. Se a latência subir 800ms, alguém reclama.
A diferença muda tudo: estilo de log, plano de rollback, plano de gradual rollout, plano de degradação. É software, não relatório.
5. O tempo de feedback
ML clássico tem ciclo de horas, dias ou semanas. Treinar modelo, esperar epoch, comparar com baseline, refazer feature, treinar de novo. Como um artigo recente sobre harness pra ML coloca: a verificação real toma horas, dias, ou até semanas.
AI engineering é o oposto. Você muda o prompt, roda o eval set de cinquenta casos, em três minutos vê o pass rate, ajusta de novo. Ciclo de minutos. É por isso que harness engineering virou disciplina por conta própria — o harness é a infra que cobre verificação, observabilidade, eval, controle de custo e recuperação de erro do sistema agêntico.
Quando você muda o tempo de feedback, muda o método de trabalho. Quem nunca viveu ciclo de cinco minutos vai aplicar método de ciclo de cinco semanas, e fica pra trás. Esse loop curto é exatamente o que a gente destrincha no Harness Engineering com Claude Code, do loop autônomo até agente em produção, com código rodando.
6. Quem migra mais rápido
Aqui o mercado mente. A intuição diz "data scientist vira AI engineer naturalmente, é só adicionar LLM no toolkit". Errado.
Backend dev migra mais rápido. Quem é backend já trata API, latência, retry, rate limit, observabilidade, deploy, rollback, custo — exatamente o conjunto que o AI engineer usa todo dia. O que falta é o vocabulário de LLM: prompt, eval, embedding, RAG. Isso se aprende em três a seis meses de trabalho focado.
A Pragmatic Engineer entrevistou Chip Huyen em cima dessa mesma tese: AI engineering parece muito mais com software engineering do que com ML engineering. Não é coincidência que as melhores transições estão vindo de quem já constrói sistema, não de quem só treina modelo.
Data scientist precisa aprender o outro lado: testar em CI, escrever serviço, monitorar p99, fazer rollback bem feito, pensar em SLA. Não é impossível, mas é uma curva maior. Quem ignora isso treina data scientist como se fosse AI engineer e o time entrega protótipo bonito que cai no primeiro pico de tráfego.
7. Por que essa confusão atrasa carreira
Dev que se posiciona como "data scientist generalista que também usa LLM" perde vaga de AI engineer pra um backend dev que aprendeu prompt e RAG. Isso já está acontecendo nas vagas que pagam mais.
CTO que contrata "AI engineer" e descreve o cargo com requisitos de data scientist (Tableau, fine-tuning, estatística inferencial, R) atrai o perfil errado, paga seis meses de retrabalho, e descobre que não tinha problema de modelo — tinha problema de sistema.
A confusão custa carreira pra um lado e dinheiro pro outro. E a saída não é estudar tudo: é escolher um caminho com profundidade. Em 2026, o caminho com mais demanda concreta é o de sistema — Python, API, eval, harness, observabilidade — não o de notebook.
Onde os dois ainda se encontram
Não é todo problema que pede LLM. Fraude, churn, forecast com dado tabular grande e estruturado seguem sendo território de data science clássica — foundation model nesses casos é caro e overkill. O bom AI engineer também usa estatística, especialmente em A/B de prompt e em análise de eval (um chi-quadrado aqui, um teste de proporção ali).
Coexistir tudo bem. Misturar não.
FAQ rápido
- AI engineer precisa saber treinar modelo? Não pra começar. A maior parte das vagas de produto não pede fine-tuning, pede usar foundation model bem. Saber treinar ajuda em casos especiais, mas não é gargalo de carreira.
- Data scientist está obsoleto? Não. Análise estatística, experimentação e modelagem em dado tabular seguem importantes. O que mudou é que "IA aplicada" deixou de ser sinônimo de data science.
- Qual livro abre a porta? AI Engineering, do Chip Huyen, é o material mais direto. O repositório de apoio também é gratuito.
- Onde aprender harness e eval na prática? No cookbook da Anthropic e no da OpenAI. Material gratuito, com código que roda.
Conclusão
Sete diferenças, uma conclusão: pare de tratar engenharia de IA e data science como sinônimos. Foco diferente, métrica diferente, stack diferente, output diferente, tempo de feedback diferente, perfil diferente, mercado diferente.
Quem entendeu isso já parou de estudar tudo ao mesmo tempo e tá afiando uma das duas com profundidade. O resto ainda manda CV explicando que sabe Tableau e Hugging Face na mesma frase, e fica esperando recrutador descobrir qual é qual.

{AI Engineer} — apaixonado por Laravel, arquitetura de software e construir produtos com impacto. Compartilho aqui tutoriais, descobertas e reflexões sobre o dia a dia de engenharia.
Você também pode gostar
Desenvolvedor de IA vs Engenheiro de IA: 7 diferenças que importam
Desenvolvedor de IA e engenheiro de IA não são dois nomes pra mesma vaga. Comparativo direto de escopo, skills, salário e carreira, e onde o dev de produto cruza a linha.
Engenheiro de IA em 2026: o que faz, e por que não é só usar ChatGPT no trabalho
Em 2024 era cargo inventado pelo LinkedIn. Em 2026 é o sênior mais disputado dos EUA. O que faz um Engenheiro de IA na prática: as 5 entregas em qualquer JD sênior, o stack típico (LLM API, harness, vector store, evals, observability) e por que a maioria veio de backend, não de Data Science.
Engenheiro de IA: o que faz no dia a dia em 2026
O que um engenheiro de IA realmente faz no dia a dia em 2026: a rotina real, o stack que ele toca, o que NÃO faz e como entrar na área vindo de dev backend. Spoiler: não é treinar modelo o dia inteiro.
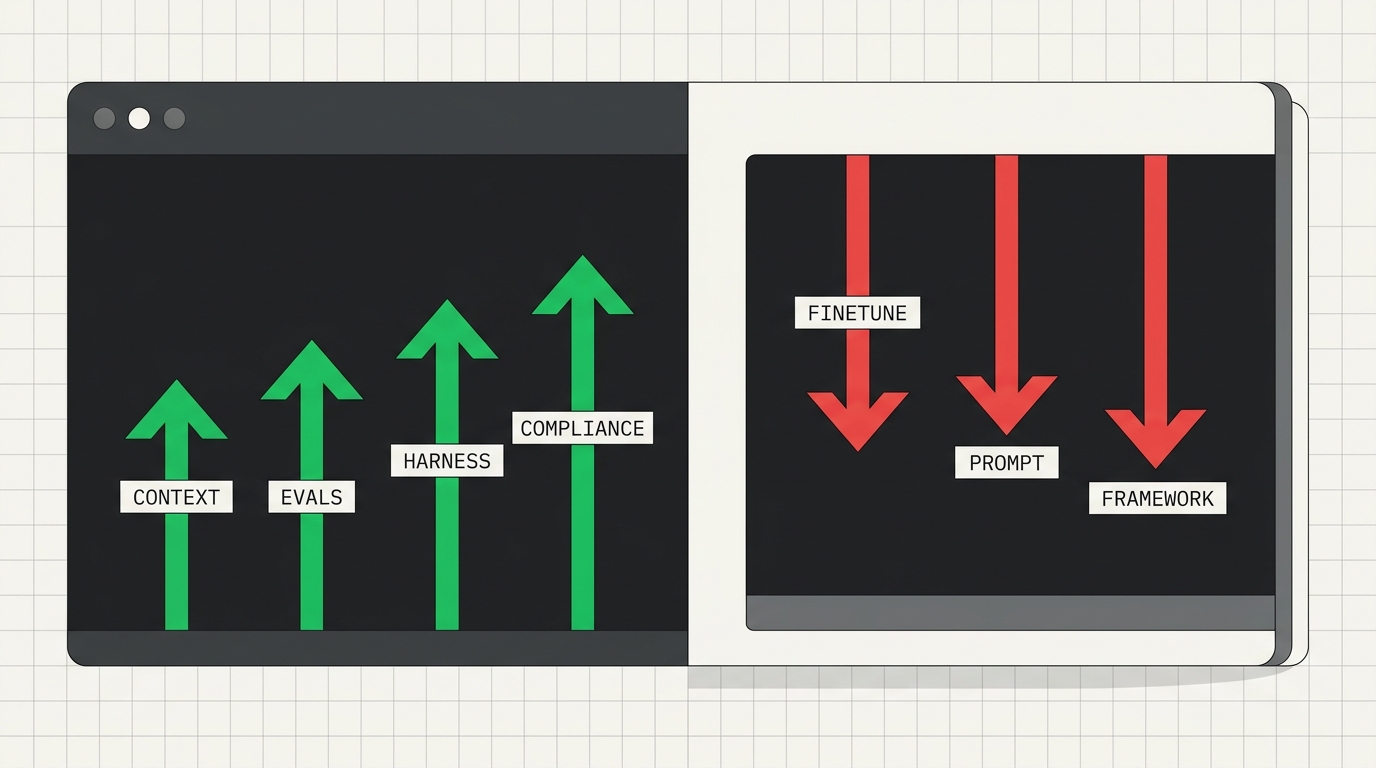
AI engineer no 2º semestre de 2026: o que o recrutador vai pedir
Li 200 vagas de AI engineer postadas em maio de 2026 e separei sinal de ruído: quatro skills que sobem (context engineering, evals, harness e compliance), três que perdem peso e um roteiro de 90 dias pra entrar na shortlist do segundo semestre.
