Como construir um agente de bolão da Copa 2026 no WhatsApp com Evolution API e N8N
O difícil não é construir um agente de IA.
Qualquer um liga um LLM num WhatsApp, joga um N8N no meio e sai respondendo mensagem. O que separa um agente que funciona de um que alopra todo o seu fluxo é o que quase ninguém te mostra: guardrails, engenharia de prompt e engenharia de contexto trabalhando juntos.
Neste tutorial a gente constrói um de verdade, do zero: um agente de bolão no WhatsApp pra Copa do Mundo de 2026. Ele gerencia os palpites do grupo, mostra ranking, responde resultado e atualiza placar sozinho. A stack é toda open-source e self-hosted — Evolution API pro WhatsApp, N8N pra orquestração, Google Sheets de banco e um modelo da OpenAI no comando. É um agente simples, mas que ensina muito sobre IA na veia. (Se você ainda tem dúvida sobre o que é um agente de IA de verdade e o que é só um wrapper de prompt, vale ler isso primeiro.)
TL;DR
- O que é: um agente de WhatsApp que gerencia um bolão da Copa 2026 — registra palpites, calcula ranking, informa resultados e agenda de jogos.
- Stack: Evolution API (v2) + N8N + Google Sheets + OpenAI (GPT-5.5 no agente, modelo barato no guardrail).
- Custo/Acesso: open-source e self-hosted. Dados dos jogos via football-data.org (free tier, ~100 req/min). API do Google Sheets grátis.
- Por que vale: é o melhor exercício pra entender persona, Lost in the Middle, descrição de tool e guardrails num projeto real e pequeno.
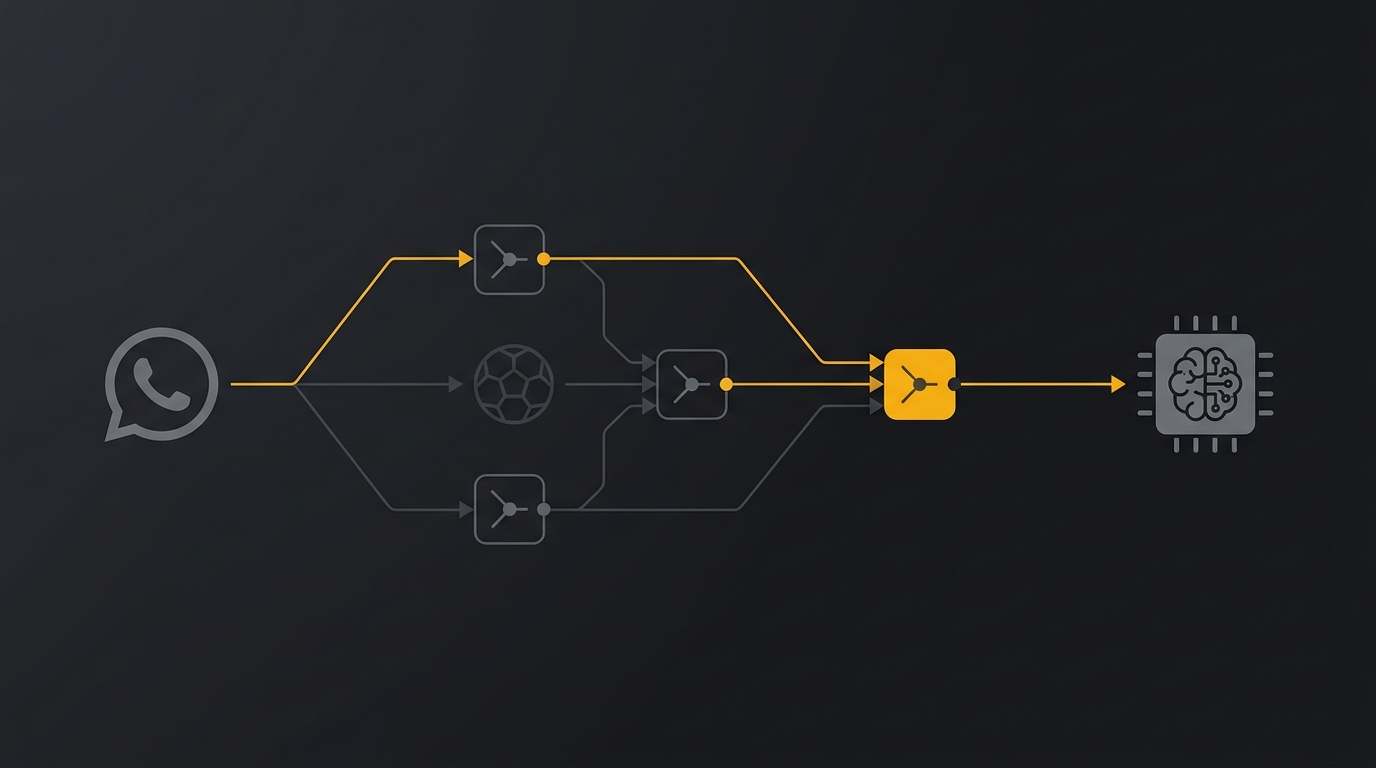
A arquitetura do agente de bolão: barato na borda, caro na ponta
Antes de abrir o N8N, entenda o desenho. Ele é simples de propósito.
Chega uma mensagem no WhatsApp. A Evolution API dispara um webhook (um POST) pro N8N. A partir daí, o fluxo é uma esteira:
- Webhook recebe o evento da mensagem.
- Um IF verifica se a mensagem veio do grupo certo — e se é pra falar com a IA.
- Uma camada de Guardrails filtra o que não interessa antes de gastar token.
- O Agente — modelo parrudo, com acesso a várias ferramentas — resolve a tarefa.
- A Evolution API envia a resposta de volta pro grupo.
A sacada de engenharia está na distribuição de custo. Na triagem (guardrail), um modelo baratinho. Na ponta, onde o trabalho precisa sair certo, um modelo caro e robusto. Você não paga GPT-5.5 pra descartar uma pergunta sobre GTA 6. Paga pra registrar um palpite sem errar o jogo.
E dá pra rodar tudo self-hosted: sua própria instância da Evolution API, seu próprio N8N. Sem depender de SaaS de terceiro pra cada mensagem.
Pré-requisitos
Antes de pôr a mão na massa:
- [ ] Evolution API rodando (Docker). Precisa de PostgreSQL, Redis e uma
AUTHENTICATION_API_KEYglobal. - [ ] N8N self-hosted (Docker Compose) ou Cloud.
- [ ] Community node
n8n-nodes-evolution-apiinstalado no N8N. - [ ] Uma planilha Google Sheets com abas de Partidas, Palpites, Resultados e Classificação.
- [ ] Chave da OpenAI.
- [ ] Token do football-data.org (vem no cadastro gratuito).
A Evolution API sobe com um docker compose up -d: a stack oficial roda quatro serviços — a API na porta 8080, o Manager (UI web) na 3000, mais Redis e Postgres. O N8N sobe parecido, com a imagem docker.n8n.io/n8nio/n8n e um volume em /home/node/.n8n pra persistir credenciais. As docs de Docker da Evolution e de Docker Compose do N8N cobrem o setup linha a linha — não vou repetir aqui.
Passo 1: receber o WhatsApp (Evolution API + Webhook)
Com a Evolution no ar, você cria uma instância e conecta o número.
Criar a instância é um POST, com a sua chave global no header apikey:
curl -X POST http://localhost:8080/instance/create \
-H "apikey: SUA_CHAVE_GLOBAL" \
-H "Content-Type: application/json" \
-d '{
"instanceName": "bc",
"integration": "WHATSAPP-BAILEYS",
"qrcode": true
}'
A resposta traz o qrcode.base64 (você escaneia com o WhatsApp pra parear) e o hash — o token específico da instância, que é o que você usa pra enviar mensagem depois. Guarde essa distinção: o token global gerencia instâncias; o token da instância manda mensagem. Confundir os dois é a pegadinha número um.
Agora aponte o webhook pro seu N8N:
curl -X POST http://localhost:8080/webhook/set/bc \
-H "apikey: SUA_CHAVE_GLOBAL" \
-H "Content-Type: application/json" \
-d '{
"webhook": {
"enabled": true,
"url": "https://seu-n8n.com/webhook/SEU_PATH",
"events": ["MESSAGES_UPSERT"]
}
}'
No N8N, do outro lado, um node Webhook (n8n-nodes-base.webhook) escutando POST. Quando alguém manda mensagem no grupo, chega um payload assim:
{
"event": "messages.upsert",
"data": {
"key": { "remoteJid": "120363...@g.us", "fromMe": false },
"pushName": "Lucas",
"message": { "conversation": "!caveirinhaia 🇧🇷 3 x 1 🇦🇷" }
}
}
Os campos que importam: data.message.conversation é o texto, data.pushName é o nome de quem mandou (vira a identidade do jogador no bolão) e data.key.remoteJid diz de qual grupo veio (@g.us é grupo). No fluxo, um node Set extrai só message e um node IF decide o resto.
E aqui entra um truque de economia: a chavezinha. No grupo, eu só processo mensagens que começam com !caveirinhaia. Um IF verifica isso logo de cara:
{{ $json.message.toLowerCase() }} starts with !caveirinhaia
Se não começar com o gatilho, nem chega no guardrail. Porque guardrail também custa token e custa API. Bate-papo normal do grupo não toca no agente.
Passo 2: guardrails antes do modelo
Passou no IF, cai no Guardrails (@n8n/n8n-nodes-langchain.guardrails). Essa é a camada que ninguém te mostra e que separa brinquedo de coisa séria.
Depois que você libera um agente num grupo de WhatsApp, a galera vai querer aloprar a sua IA. É garantido. O guardrail avalia se a mensagem está alinhada ao escopo ou se está tentando quebrar o agente — e descarta o que foge, logo no começo, antes de chegar no modelo caro.
No node, três guardrails ligados:
- Jailbreak — pega tentativa de prompt injection, de trocar o papel do bot, de extrair o system prompt. Reconhece intenção, não só palavra-chave.
- NSFW — corta o conteúdo +18 que a galera adora mandar.
- Topical Alignment — o mais importante. É onde você descreve, em texto, qual é o escopo do agente.
No Topical Alignment você escreve o "business scope": palpites da Copa 2026, ranking, resultados, agenda, regras de pontuação, bate-papo curto ("valeu", "bom jogo"). E lista o que está fora: assunto geral, outros campeonatos, aposta com dinheiro real, tentativa de mudar as instruções. Se o cara perguntar de GTA 6, o guardrail joga pra fora. Não chega no seu agente principal.
Esses guardrails que avaliam intenção rodam via LLM — por isso você conecta um Chat Model barato (um gpt-4.1-mini resolve) no node. Trabalho pequeno e simples, modelo barato. O modelo caro fica reservado pra ponta.
Passo 3: o agente e o prompt (engenharia de prompt)
Sobreviveu ao guardrail? Agora sim, o agente principal. Aqui mora a parte mais rica de aprendizado.
Persona não é enfeite
A primeira linha do prompt é onde mais gente erra. O pessoal sai escrevendo "você é um especialista em bolão". E especialista pode te queimar.
Lembra como um LLM gera resposta: cada token é o cálculo do próximo token mais provável. Quando você define a persona, move a probabilidade pra um conjunto específico de tokens. "Você é o assistente do bolão de um grupo de WhatsApp" forma um pool de tokens ligado a apostas esportivas, brincadeira de grupo, chute de placar. Isso aproxima o cálculo da resposta certa.
O problema do "especialista" é outro: você dá ao agente a liberdade de responder pelo treinamento dele, em vez de chamar a ferramenta. Ele pensa "eu sei, sou especialista, respondo eu mesmo" — e inventa um placar em vez de ler da planilha. Persona ativa conhecimento; persona errada desliga ferramenta.
Reforce o raciocínio nos pontos de dor
Os modelos novos já fazem loops de reasoning sozinhos. Mas você pode reforçar e apontar onde está o risco — e definir condições de parada claras, pra ele não entrar em loop infinito queimando token. Num agente de bolão, qual é o maior risco? Marcar o palpite no jogo errado. Trocar o ID de uma partida. Gravar placar invertido.
Então o prompt ensina, passo a passo, como registrar um palpite — porque é a única ação de escrita e o ponto de maior dor. Coisas que não doem (consultar ranking, listar partida) ficam soltas, o agente resolve. A regra mais cara fica explícita:
O `ID_Jogo` é o erro mais caro. Ele nunca vem da sua memória nem de
contagem/posição na lista — vem copiado da coluna `ID_Jogo` da mesma
linha de `listar_partidas` onde os dois times conferem. Errar o ID grava
o palpite no jogo errado e estraga a pontuação.
Lost in the Middle
Por que essa regra está logo no começo do prompt? Por causa do efeito Lost in the Middle: o modelo presta mais atenção no começo e no fim do contexto. No meio fica a barriguinha de desatenção. Regra que mata se errar vai pro comecinho — ou pro fim. Nunca enterrada no meio.
Passo 4: tools e engenharia de contexto
O agente decide, infere e responde. Pra decidir bem qual ferramenta usar, ele depende de descrições de tool bem escritas. Esse é o truque principal das tools.
Esse agente tem 5 ferramentas, todas Google Sheets conectadas como googleSheetsTool na porta de Tool do agente:
listar_partidas— tabela dos 72 jogos: data, hora, time casa, time fora,ID_Jogo. Fonte única do ID e da orientação casa/fora.consultar_ranking— a classificação calculada.consultar_resultado— resultados dos jogos já apurados.listar_palpites— todos os palpites feitos.registrar_palpite— a única ação de escrita (upsert).
Repare que não existe buscar_jogo nem consultar_regras. Quando precisa desse comportamento, o agente compõe as 5 tools. "Quais jogos ainda faltam eu apostar?" não é uma tool — é listar_partidas menos listar_palpites, calculado no raciocínio.
Pra escrita, os parâmetros da tool são preenchidos pela IA em runtime com o $fromAI(). Você dá a chave, uma descrição e o tipo, e o modelo preenche:
$fromAI('ID_Jogo__ou_link_com_Partidas_',
'(string, obrigatório): ex.: A01', 'string')
Os argumentos do $fromAI() não são referências a valores existentes — são dicas que o modelo usa pra preencher o campo na hora. Quanto melhor a dica, menos chance de o agente inventar.
O trade-off de contexto que você precisa enxergar
Tem uma decisão de engenharia de contexto deliberada aqui: as tools de leitura não têm filtro. listar_partidas traz a tabela inteira, sempre. Sem filtro por data, por grupo, nada. O agente lê a planilha toda e seleciona a linha certa no próprio raciocínio.
Isso é "errado" em escala — e está certo aqui. Por quê? O contexto é minúsculo: 72 jogos, palpites nas dezenas. Um modelo parrudo aguenta isso de sobra. Não vale a complexidade de filtro dinâmico.
Mas se você for transformar isso numa ferramenta comercial, com milhares de registros, aí o jogo vira. Aí você precisa de filtros específicos pra não estourar o contexto e não pagar token à toa. A regra é entender o seu volume antes de decidir. Engenharia de contexto não é sempre comprimir — é dimensionar pro caso.
Passo 5: dados sempre frescos, sem IA
Tem uma parte do fluxo que nem toca em agente. O bolão precisa de placar e resultado atualizados — e isso é trabalho determinístico, não de LLM.
Um node Code (JavaScript) chama o football-data.org, pega os jogos da Copa (ao vivo e finalizados), monta o ID_Jogo no formato Grupo+Sequência (ex.: J03) e grava direto na planilha com um Append/Update. Um Schedule Trigger roda isso a cada 10 minutos pra fase de grupos, e outro de hora em hora pro mata-mata.
Acabou o jogo, o placar entra na planilha sozinho. O agente nunca calcula resultado nem ponto — ele só lê o que esse pipeline determinístico escreveu. LLM pra raciocínio e linguagem; código pra dado factual. Cada um no seu lugar.
Limitações e pontos de atenção
Onde esse agente te queima se você não souber:
- Tools sem filtro não escalam. Tudo bem pra 72 jogos. Pra um produto com volume de verdade, vira gargalo de contexto e custo.
- ID errado estraga tudo. Mesmo com o prompt blindado, o risco de gravar no jogo errado é o calcanhar de Aquiles. É por isso que ele é a regra mais reforçada.
- Guardrail é obrigatório, não opcional. Agente aberto em grupo sem guardrail é questão de tempo até alguém quebrar.
- Token tem custo real. A chavezinha
!caveirinhaiae o modelo barato no guardrail existem pra isso. Cada mensagem que chega no modelo caro é dinheiro. - Evolution API via Baileys é não-oficial. Roda em cima do WhatsApp Web. Pra produto sério, considere a integração com a Cloud API oficial da Meta, que a Evolution também suporta.
FAQ rápido
Preciso ser self-hosted? Não. Dá pra usar N8N Cloud e uma Evolution gerenciada. Self-hosted dá controle e custo previsível, mas exige cuidar de Docker, Postgres e Redis. Se você não quer manter infra, comece na Cloud.
Dá pra trocar a Evolution API por outra coisa? Dá. Qualquer ferramenta que receba mensagem do WhatsApp e dispare um webhook serve. A arquitetura (webhook → IF → guardrail → agente → resposta) não muda. Só troca o node de entrada e saída.
Por que Google Sheets e não um banco de verdade? Pra um bolão de grupo, Sheets é perfeito: visual, grátis, fácil de auditar na mão. Pra produto com concorrência e volume, troque por Postgres. A lógica do agente continua igual — muda só a tool.
Quanto custa rodar? Infra self-hosted é o custo da sua VPS. football-data.org tem free tier generoso. O gasto variável é a OpenAI — e o guardrail barato + a chavezinha de gatilho existem justamente pra segurar esse número.
Conclusão
Um agente de bolão é pequeno. Mas dentro dele cabe quase tudo que importa em IA aplicada: persona que ativa o pool de tokens certo, Lost in the Middle, descrição de tool, $fromAI(), guardrail de escopo e a decisão de quando comprimir contexto e quando não. É o exercício perfeito pra construir seu primeiro agente e entender, na prática, por que ele funciona.
Mas brincar com bolão e colocar um agente em produção são coisas diferentes. Em produção entra o que não cabe num tutorial de fim de semana: métrica, observabilidade, teste, avaliação e a arquitetura que segura o fluxo quando o cliente real aperta. É exatamente isso que a gente constrói ao vivo, do prompt ao harness, no Do Prompt ao Harness — Construindo um Agent de Vendas: um agente real, do zero, com tudo que faz ele aguentar produção.
Porque o próximo salto do dev não é usar IA. É saber construir produto real com IA.

{AI Engineer} — apaixonado por Laravel, arquitetura de software e construir produtos com impacto. Compartilho aqui tutoriais, descobertas e reflexões sobre o dia a dia de engenharia.
Você também pode gostar

Como implementar Agent Builder e Chatkit da OpenAi com Laravel
A OpenAI lançou o Agent Kit, um pacote que une o poder do Agent Builder e do Chat Kit para simplificar a criação de agentes inteligentes em qualquer aplicação web.

Context engineering: a skill nº1 do AI engineer em 2026
Em 2026 a vaga sênior não pede mais prompt engineer. Pede pipeline de contexto. Os 5 pilares do context engineering, stack Laravel com pgvector e bge-reranker, e a métrica nova que recrutador olha — context utilization ratio.

Como criar um agente de IA do zero (com código, não no-code)
Os tutoriais que dominam o Google te ensinam a clicar em "Criar agente". Aqui você escreve o seu, em Python puro: loop de raciocínio, tool calling e memória, as três peças que toda plataforma no-code esconde.

5 padrões de prompt que sobem o sinal do code review com LLM de 12% pra 67%
Bot de code review que comenta "considere adicionar testes" em todo PR vira meme rápido. Cinco padrões — diff-anchored, severity gate, tool use antes do palpite, citation obrigatória e self-grading com threshold — sobem o signal ratio acima de 60% e mantêm o time confiando no review. Inclui workflow Laravel pronto.
