#Prompt Engineering
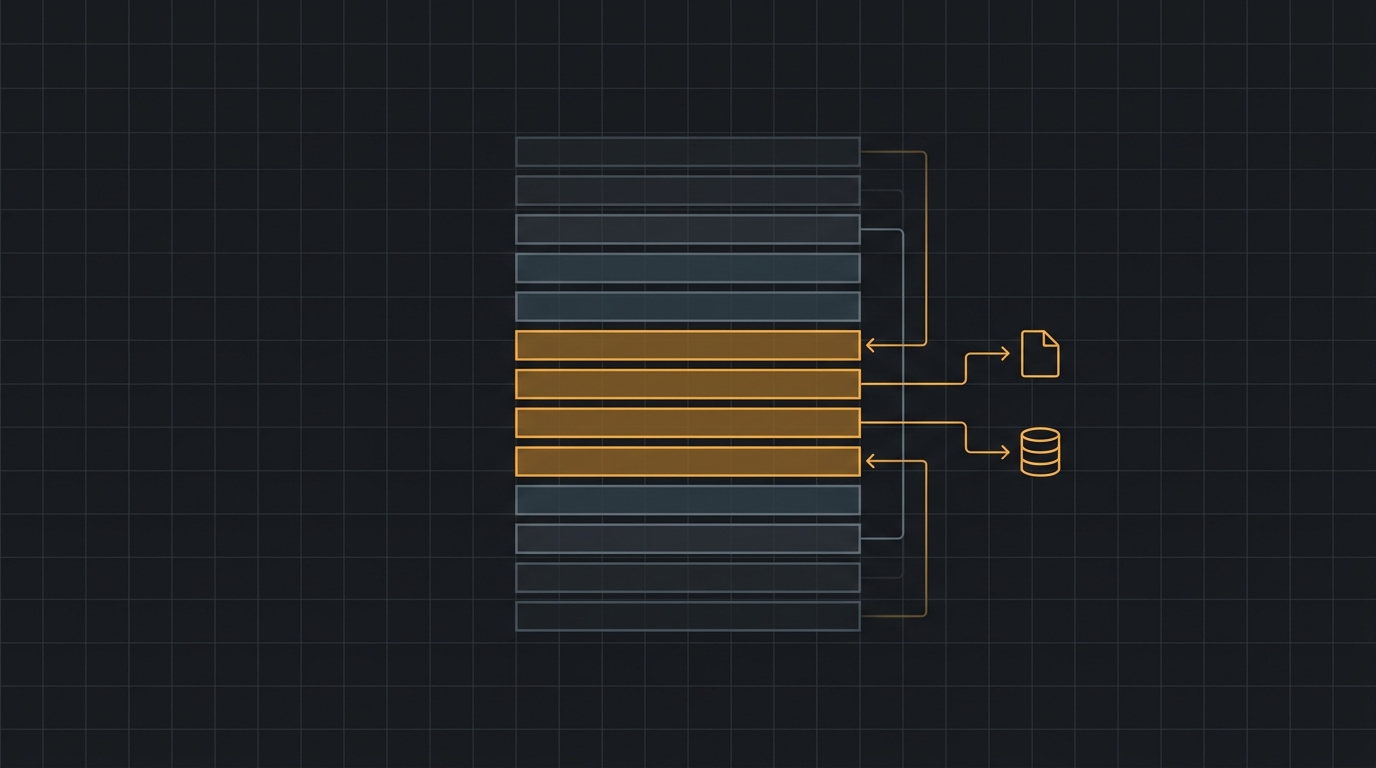
Ferramentas de engenharia de contexto que eu uso em produção
Lista prática e opinativa das ferramentas de engenharia de contexto que seguram um agente em produção: gestão de janela, compressão, recuperação e observabilidade. Com APIs nativas, números reais e o que dá errado.

Prompt para gerar código: 8 padrões que tiram o ar de tutorial genérico da IA
A IA gera código que funciona, mas parece copiado de um tutorial de 2021. Oito padrões de prompt para gerar código que segue o padrão do SEU projeto, não o exemplo genérico. Direto das docs da Anthropic e do Claude Code.

System prompt de produção: a espinha dorsal do comportamento do agente
O system prompt não é onde você manda o modelo ser legal. É a constituição do agente: papel, políticas, ferramentas e formato. Como estruturar um de produção e por que ele joga num campeonato diferente de um prompt de chat.
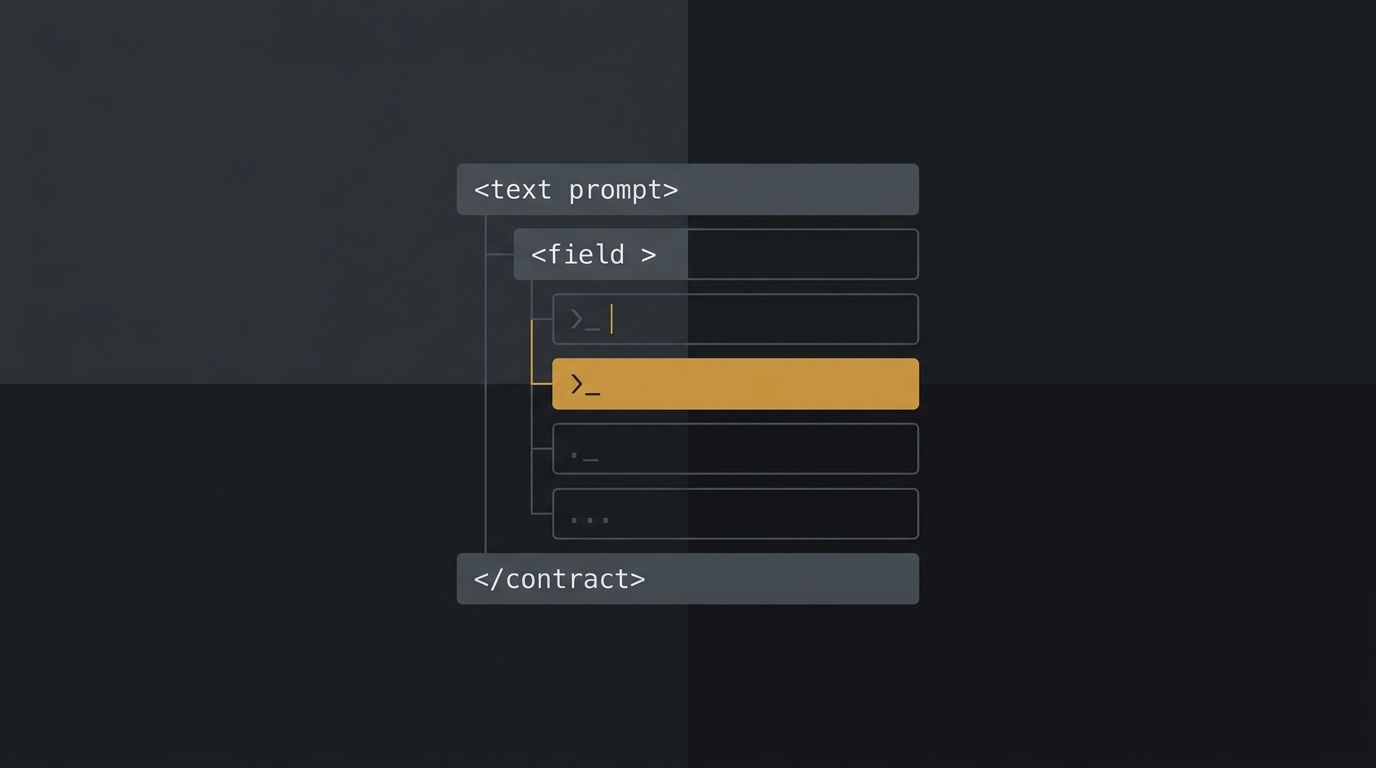
Engenharia de prompt: o guia honesto (sem fórmula mágica)
Engenharia de prompt não é decorar fórmula nem lista de "100 prompts mágicos". É escrever instrução como contrato: estrutura, instrução clara, exemplos few-shot e formato de saída. O guia honesto para quem constrói software com IA.

Engenharia de contexto: o que vai no prompt (e o que NÃO vai)
O recurso mais escasso de um agente é a janela de contexto. Veja como decidir o que entra no prompt — system prompt, exemplos, histórico, dados recuperados — e por que encher de contexto degrada a resposta.
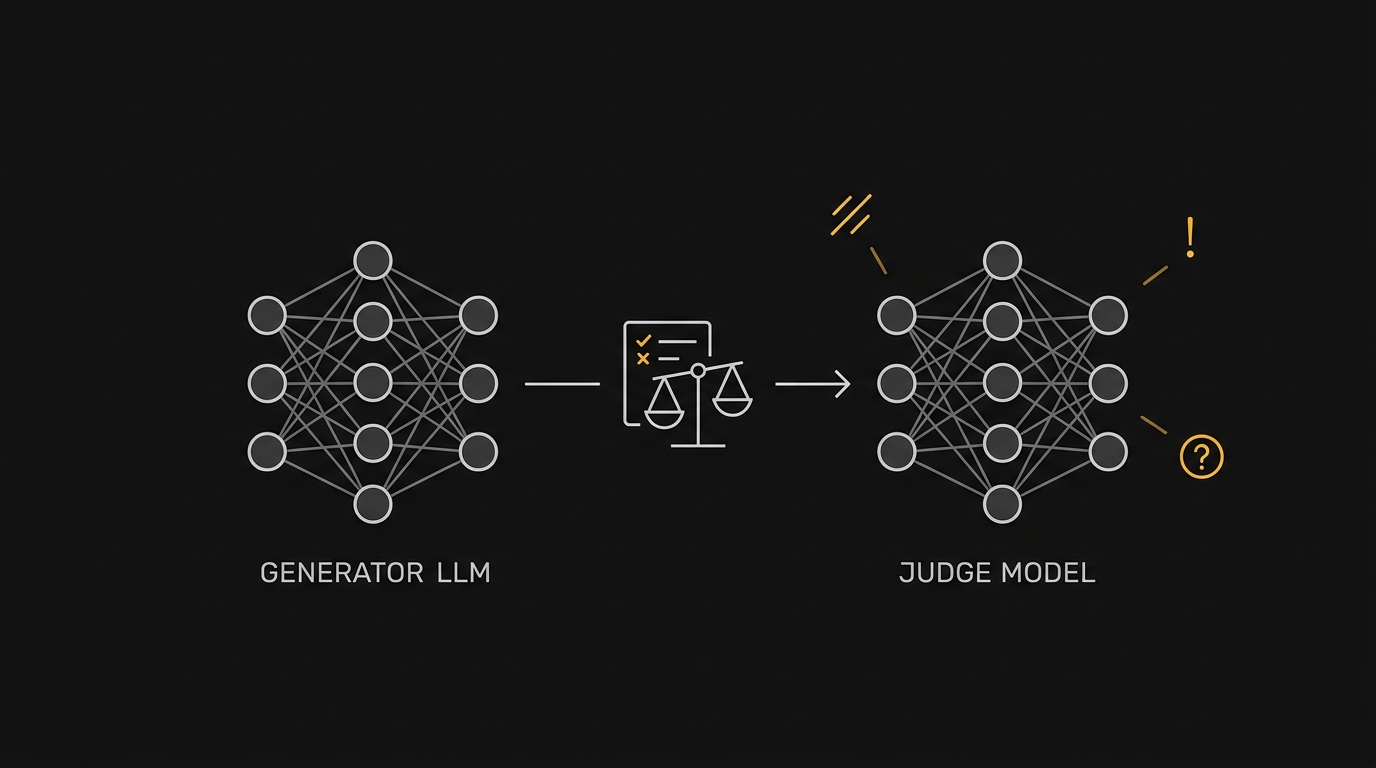
Model Graders: usando LLMs para avaliar LLMs (e os 3 erros que invalidam o seu eval)
LLM-as-judge é o atalho que todo time de IA usa pra escalar evals. Mas tem três armadilhas que silenciosamente invalidam o pipeline: self-preference, position e verbosity bias, e calibração ausente. Cobrimos os três padrões de prompt para grader (rubric, reference, pairwise) e como blindar contra cada erro com mitigação concreta.
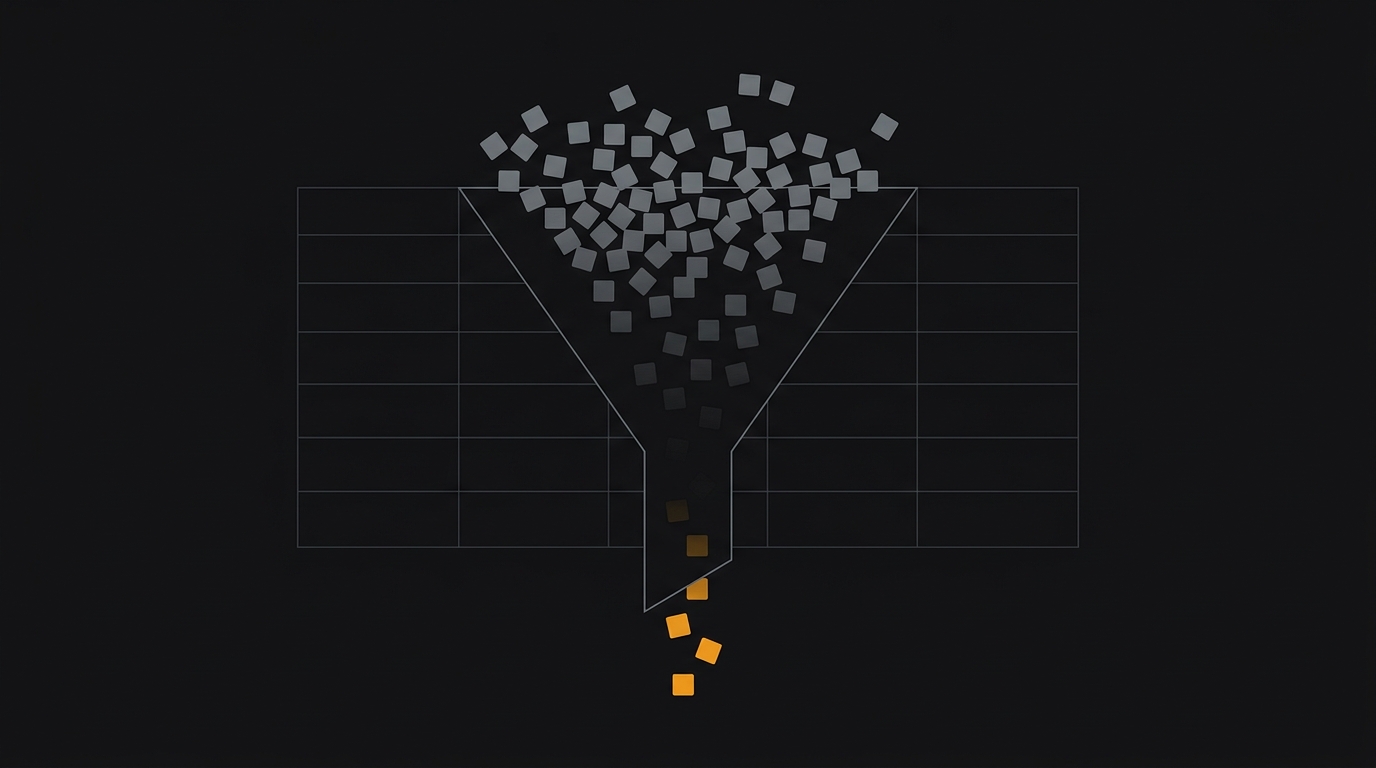
Engenharia de contexto vence prompt engineering: por que o que você NÃO coloca no prompt importa mais
Karpathy e Lütke dispararam em 2025: o nome certo não é prompt engineering, é engenharia de contexto. Três experimentos lado a lado da mesma tarefa mostram, com tokens, dólar e testes passando, por que o que você NÃO coloca no prompt importa mais que o que coloca.
