O que é Harness de IA? O ambiente que faz seu agente parar de travar
Todo mundo fala em prompt. Quase ninguém fala no que de fato faz o agente funcionar em produção.
Você abre a thread, vê o prompt mágico de 400 linhas, copia, cola, e o "agente" funciona por uns 3 minutos. Depois ele esquece o que estava fazendo, repete trabalho, inventa um arquivo que não existe e trava. A culpa cai no modelo. Quase nunca é o modelo.
O que separa um demo bonito de um agente que aguenta produção tem nome: harness. É o ambiente que roda o agente — o loop, as ferramentas, o estado e os limites de segurança. Neste post você vai entender, sem hype, o que é harness de IA, quais peças ele tem e por que ele é exatamente o que faz seu agente parar de travar.
TL;DR
- O que é: o harness é toda a engenharia ao redor do LLM que transforma um modelo de texto em um agente que executa tarefas — loop, ferramentas, estado, contexto e guardrails.
- A fórmula:
Agente = Modelo + Harness. O modelo dá a inteligência. O harness dá a utilidade. - Por que importa: o mesmo modelo, com harness ruim, vira um chatbot que trava; com harness bom, vira um agente que fecha a tarefa.
- Aprofundamento: este post é o mapa de entrada. Os links no final levam para a anatomia detalhada de cada peça.
O que é harness de IA, afinal?
Um LLM, sozinho, faz uma coisa só: recebe texto e devolve texto. Ponto. Ele não abre arquivo, não chama API, não lembra do que fez na mensagem anterior, não sabe se acertou. É um motor parado.
O harness é o chassi em volta desse motor. A definição mais limpa que vi vem da LangChain: o harness é "todo pedaço de código, configuração e lógica de execução que não é o modelo em si". Daí a fórmula que virou jargão no mercado:
Agente = Modelo + Harness
O modelo é a parte inteligente. Mas é também a menor parte do sistema. Quem dá ao modelo a capacidade de agir no mundo — ler um arquivo, rodar um comando, consultar um banco, verificar o próprio trabalho — é o harness. Tira o harness e você não tem agente. Tem um campo de texto.
E aqui mora o ponto que quase ninguém fala: quando dois times rodam o mesmo modelo e um entrega um agente confiável enquanto o outro entrega um brinquedo que quebra no terceiro turno, a diferença não está no modelo. Está no harness.
O loop: o coração do harness
Se o harness tem um coração, é o loop.
Um LLM responde uma vez e para. Um agente precisa continuar até terminar a tarefa. O loop é o que faz isso acontecer. Na prática, é um ciclo simples que se repete:
enquanto a tarefa não terminou:
1. o modelo olha o estado atual
2. decide a próxima ação
3. chama uma ferramenta (ler arquivo, rodar comando, buscar dado)
4. observa o resultado da ferramenta
5. volta pro passo 1 com o resultado em mãos
Perceber, decidir, agir, observar. De novo. E de novo. Até a tarefa fechar — ou até bater um limite que o harness impõe (número de iterações, orçamento de tokens, tempo).
Esse loop é a diferença entre "me explica como corrigir esse bug" e "corrige esse bug". O primeiro é uma resposta. O segundo é dezenas de voltas no loop: ler o código, rodar o teste, ver o erro, editar, rodar de novo, confirmar que passou. Cada volta alimenta a próxima com o resultado real do mundo, não com um chute.
Não só acompanhe as novidades — domine. Engenharia de IA na prática, ao vivo, toda semana, na maior comunidade do Brasil.
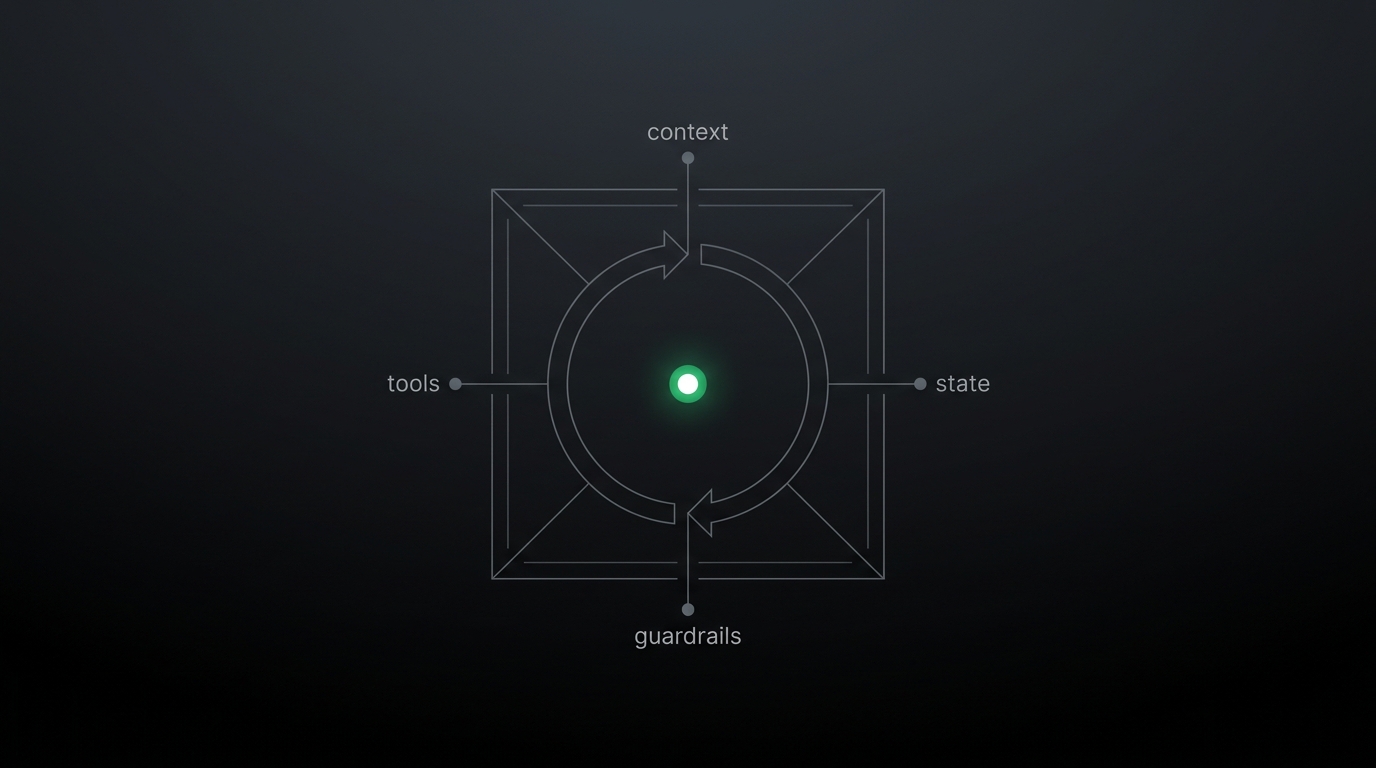
Entrar no ClãAs quatro peças que todo harness tem
Loop é o coração. Mas ele não bate sozinho. Todo harness sério tem quatro peças trabalhando juntas.
1. Ferramentas (tools). São as mãos do agente. Tool calling expõe capacidades — rodar bash, ler e escrever arquivo, consultar uma API, acessar um servidor MCP — e roteia o pedido do modelo para a execução de verdade. Sem ferramentas, o agente sabe o que fazer mas não consegue tocar em nada.
2. Estado (state). É a memória de trabalho. Lista de tarefas, o que já foi feito, o que falta, resultados intermediários. Nos harnesses mais robustos, o próprio sistema de arquivos vira estado: a Anthropic descreve agentes que escrevem o progresso em arquivos como claude-progress.txt e usam o histórico do Git como pontos de retorno recuperáveis. Sem estado, cada volta do loop começa do zero.
3. Contexto. É o que o modelo enxerga em cada chamada. E é finito. Conforme a tarefa cresce, a janela de contexto enche — e aí o agente começa a "esquecer", perder coerência ou finalizar a tarefa cedo demais. A LangChain resume bem: "harnesses hoje são, em boa parte, mecanismos de entrega de boa engenharia de contexto". Gerenciar isso — compactar, descarregar o que não importa, injetar só o relevante — é metade do trabalho de um harness.
4. Guardrails. São os limites. Validação de entrada e de saída, isolamento de rede, permissões por ferramenta, checkpoint com humano no meio antes de uma ação destrutiva. O SDK da OpenAI, por exemplo, trabalha com guardrails em três níveis: na entrada, na saída e em cada chamada de ferramenta. Guardrail não é burocracia — é o que impede o agente de apagar a tabela de produção porque interpretou mal uma instrução.
Conceito técnico, aplicação prática, impacto no produto: ferramentas, estado, contexto e guardrails são o que transformam "um LLM que responde bonito" em "um agente que você deixa rodando sozinho e confia no resultado".
Por que o harness é o que faz seu agente parar de travar
Volta ao começo. O agente que travou no terceiro turno.
Quase sempre, o que quebrou foi uma das quatro peças — não o modelo. O contexto encheu e ele perdeu o fio. O estado não foi persistido e ele repetiu trabalho. Faltou uma ferramenta de verificação e ele entregou código que nunca rodou. Não teve guardrail e ele fez besteira.
Isso não é teoria. Em benchmarks de agentes de código como o SWE-bench Verified — onde o agente precisa corrigir um bug real de um repositório do GitHub e a correção só conta se os testes passarem — os melhores sistemas chegam a faixas de 65% a 77% de resolução. E a qualidade do harness tem peso central nesse número. O mesmo modelo, em harnesses diferentes, entrega resultados diferentes.
A parte boa: harness é engenharia, e engenharia você controla. Você não treina o GPT ou o Claude. Mas você decide como o loop para, como o contexto é compactado, quais ferramentas existem, onde entra a verificação. Os harnesses mais avançados já separam um agente "gerador" de um agente "avaliador" cético, que testa o trabalho contra um contrato antes de aceitar — um loop de feedback que aumenta muito a taxa de acerto. Tudo isso é decisão sua, não do modelo.
É por isso que "harness" deixou de ser detalhe de implementação e virou disciplina. Tem gente sendo contratada para fazer exatamente isso. Se você quer o porquê de o seu Claude Code travar em tarefas longas, esse post sobre harness engineering abre o capô.
FAQ rápido
Harness é a mesma coisa que framework de agente (LangChain, CrewAI)? Não exatamente. Um framework é uma forma de montar um harness — ele te dá peças prontas para o loop, as tools e o estado. Mas você pode (e às vezes deve) construir um harness do zero, sem framework nenhum, com um service que orquestra o loop na mão. O harness é o conceito; o framework é uma das formas de implementá-lo.
Prompt não resolve, então? Prompt é parte do harness — o system prompt mora dentro dele. Mas prompt é só uma das peças. Você pode ter o prompt perfeito e mesmo assim o agente trava se o contexto estoura, se não há estado e se não há verificação. Prompt bom em harness ruim ainda quebra.
Dá pra construir um harness em PHP/Laravel? Dá, e não precisa de framework de IA para isso. Um service que recebe a tarefa, escolhe a tool, executa em loop e reporta já é um harness. Mostramos isso na prática em construindo seu primeiro harness em Laravel.
Como sei se o problema é o modelo ou o harness? Teste isolado. Se o modelo responde certo quando você dá a informação na mão, mas o agente erra quando precisa buscar essa informação sozinho, o problema é harness — faltou ferramenta, estado ou contexto. O teste dos 3 turnos é um jeito rápido de descobrir.
O que fazer com isso
Recapitulando, sem rodeio: harness de IA é o ambiente que roda o agente. Loop, ferramentas, estado, contexto e guardrails. É a engenharia ao redor do modelo — e é ela, não o modelo, que decide se seu agente aguenta produção ou trava na primeira tarefa de verdade.
O próximo passo é olhar cada peça por dentro. Comece pela anatomia de um agent harness, que destrincha as cinco peças obrigatórias, e depois veja as 6 camadas que separam um POC de um sistema confiável em produção. E se você quer fazer esse caminho do começo ao fim com código rodando, é exatamente o que a gente percorre no workshop Do Prompt ao Harness: construindo um agente de vendas — sai do prompt isolado e chega num agente de vendas vivo em produção.
Porque o próximo salto do desenvolvedor não é usar IA. É saber construir o harness que faz a IA funcionar de verdade.

{AI Engineer} — apaixonado por Laravel, arquitetura de software e construir produtos com impacto. Compartilho aqui tutoriais, descobertas e reflexões sobre o dia a dia de engenharia.
Conteúdo é o que não falta. Falta quem desembaralhe: o que importa agora é como implementar do jeito certo. No Clã você tem isso ao vivo, toda semana, com quem já filtrou o ruído.
Entrar no Clã