Subagentes na prática: dividindo contexto entre Claudes para não estourar o token budget
O dia em que o Claude esqueceu o que estava fazendo
Você abre uma sessão do Claude Code para uma tarefa séria. Refatorar um módulo grande, debugar um bug que atravessa quatro arquivos. O agente começa bem. Faz grep, lê arquivo, roda teste, lê 30k linhas de log, faz mais buscas. Em algum momento, ele decide a próxima ação com base num contexto cheio de coisa irrelevante.
Aí ele erra. Esquece a constraint que você deu há 40 mensagens atrás. Reinventa um helper que já existe. Edita o arquivo errado. Você reinicia, contextualiza tudo de novo, paga de novo.
Isso não é o modelo sendo burro. É contexto demais. A própria Anthropic tem nome para o fenômeno: context rot. E a forma mais limpa de tratar isso em produção hoje chama subagente.
Neste post vamos destrinchar o padrão pesquisador, executor e validador. Quando ele paga, quando não paga, e como configurar isso na prática usando Claude Code e Claude Agent SDK. Com os números reais que a Anthropic publicou.
TL;DR
- O que é: arquitetura onde um agente principal coordena subagentes especializados, cada um com sua própria janela de contexto.
- Stack: Claude Code, Claude Agent SDK, padrão orchestrator-worker.
- Custo: cerca de 15x mais tokens que uma sessão única, mas até +90.2% de qualidade em tarefas de pesquisa segundo a Anthropic.
- Quando vale: task com budget alto e contexto que naturalmente se isola. Para CRUD simples, single agent ainda ganha.
Por que dividir o token budget muda o jogo
Transformer trata todo token do contexto como candidato a influenciar a próxima decisão. Quanto mais token, mais ruído. A Anthropic é direta sobre isso:
"as the number of tokens in the context window increases, the model's ability to accurately recall information from that context decreases"
Esse é o problema. Janela de 1M de tokens não é o mesmo que ter 1M de tokens úteis. O modelo pondera tudo que está ali. Logs verbose, tail de testes, conteúdo de arquivo que você não vai usar mais. Tudo compete com a constraint que importa.
A saída arquitetural é simples de entender e cara de ignorar. Em vez de um Claude gigante carregando o contexto inteiro, você roda múltiplas instâncias com janelas separadas. Cada uma vê só o que precisa. Cada uma devolve um resumo curto. O orquestrador junta os resumos.
O número que importa: o estudo público da Anthropic mostra que a escolha de tokens explica 80% da variância de performance em pesquisa. Não é o modelo. É a arquitetura de contexto. E o sistema multi-agente deles, com Opus 4 como lead e Sonnet 4 como subagentes, ganhou de um Opus 4 sozinho por 90.2% no benchmark interno.
Não é mágica. É que três Claudes com contexto limpo decidem melhor que um Claude afogado em log.
Pré-requisitos
- Claude Code instalado (
npm install -g @anthropic-ai/claude-code). - Conta Anthropic com acesso a Opus, Sonnet e Haiku.
- Diretório de projeto. Vamos criar
.claude/agents/aqui. - Familiaridade básica com YAML frontmatter e prompt design.
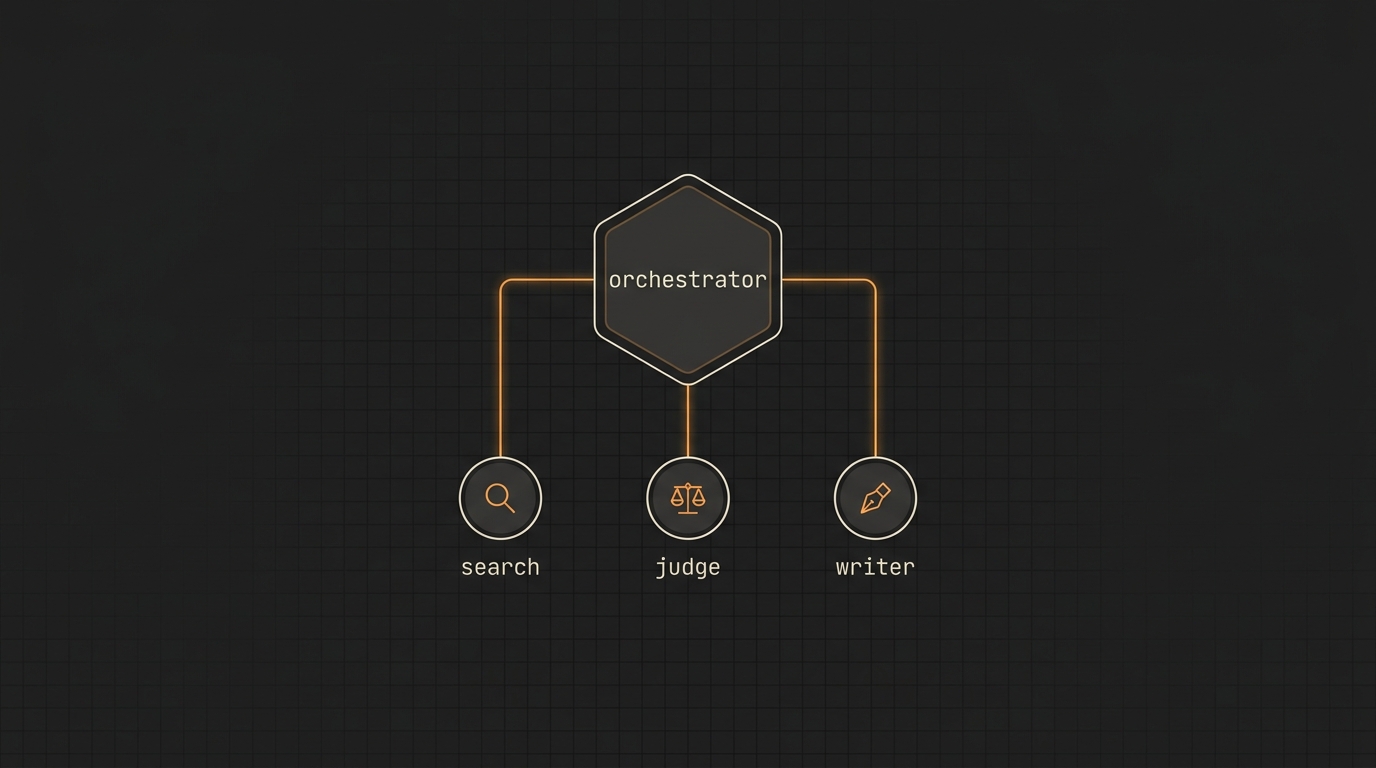
Os três papéis do padrão clássico
A divisão pesquisador, executor e validador é o equivalente a separation of concerns aplicado a contexto. Cada subagente carrega só o que faz sentido para o papel dele.
Pesquisador. Lê código, lê docs, faz busca web, faz grep. Pode encher 100k tokens explorando. Devolve um resumo de 1k a 2k tokens com referências (arquivo:linha) e a conclusão. Modelo: Haiku ou Sonnet. Tools: read-only.
Executor. Recebe o resumo do pesquisador mais o plano. Aplica mudanças. Não precisa do log de exploração porque não é trabalho dele entender o histórico. Modelo: Sonnet ou Opus. Tools: Read, Edit, Write, Bash.
Validador. Roda testes, lint, type-check. Lê output bruto (que pode ser enorme) e devolve "passou" ou "falhou + diff mínimo do que está errado". O orquestrador nunca vê os 30k linhas de output do CI. Modelo: Haiku basta na maioria dos casos. Tools: Bash + Read.
A regra arquitetural que a Anthropic enuncia é uma só:
"Work should only be split when context can be truly isolated."
Se planejamento, implementação e teste compartilham 90% do contexto, dividir é overhead. Se cada papel precisa de coisas diferentes para decidir, dividir é o que destrava.
Mão na massa: configurando os três no Claude Code
Subagentes em Claude Code são arquivos Markdown com YAML frontmatter, dentro de .claude/agents/ no projeto. O agente principal lê a description para decidir quando delegar. Documentação oficial em code.claude.com/docs/en/sub-agents.
Passo 1: o pesquisador
---
name: pesquisador
description: Use proativamente quando precisar entender uma parte do código, mapear como módulos se conectam ou consolidar contexto antes de uma mudança maior. Devolve resumo curto com referências.
tools: Read, Grep, Glob, WebFetch
model: haiku
---
Você é um pesquisador de código. Sua entrega é um briefing de no máximo
1500 tokens contendo:
1. Resposta direta à pergunta feita.
2. Lista de arquivos relevantes no formato `path:linha — papel`.
3. Riscos ou dependências escondidas que viu.
Não proponha mudanças. Não escreva código. Quem implementa é outro agente.
Se a pergunta for ambígua, devolva 1-2 perguntas e pare.
Note três coisas. model: haiku porque pesquisa é trabalho de baixo custo intelectual e alto volume de leitura. tools restritas a leitura, então o subagente não consegue editar nem por engano. Prompt amarra o formato de saída. Sem isso o resumo cresce e você perde o ganho.
Passo 2: o executor
---
name: executor
description: Aplica mudanças de código a partir de um plano e um briefing já consolidados. Não explora — recebe contexto pronto e executa.
tools: Read, Edit, Write, Bash
model: sonnet
---
Você é um executor de mudanças de código. Você recebe:
- O briefing do pesquisador (arquivos, riscos).
- O plano da mudança.
Sua tarefa é aplicar o plano. Regras:
- Não saia caçando contexto além do que foi entregue. Se faltar algo
crítico, peça ao orquestrador antes de inventar.
- Edite arquivos pequenos diretamente. Para mudanças grandes, faça
patch incremental e rode o teste relevante após cada um.
- Devolva apenas: arquivos tocados, decisões não óbvias e o que ficou
pendente.
Aqui o ganho é diferente. O executor não recarrega o código inteiro do zero. Ele tem o briefing e abre só o que precisa editar. Janela bem mais leve, foco maior na mudança.
Passo 3: o validador
---
name: validador
description: Roda suíte de testes, lint e type-check. Lê output bruto e devolve resumo do que falhou.
tools: Bash, Read
model: haiku
---
Você é um validador. Roda os comandos pedidos e devolve um resumo
estruturado:
- PASSOU / FALHOU
- Se falhou: nome do teste, arquivo:linha do erro, 3-5 linhas de
trace mais informativas, hipótese curta da causa.
- Nunca cole output bruto inteiro.
Se o output for maior que 500 linhas, leia em chunks e sintetize.
A diferença prática: você consegue rodar vitest --run em um repo grande sem entupir o contexto principal com 12k linhas de log. O validador come isso, devolve "FALHOU em auth.test.ts:47, mock de getUser retornando undefined". O orquestrador decide o próximo passo com 50 tokens, não com 12 mil.
Passo 4: como o orquestrador delega
O agente principal lê as description dos subagentes e despacha quando bate. Você também pode pedir explicitamente: "use o pesquisador para mapear como o middleware de auth chega até o controller de checkout". O Claude Code abre a janela isolada, roda, devolve só o briefing. A sua sessão principal nunca viu o grep cru.
Erro comum aqui: criar subagente para tudo. Se a tarefa não tem contexto isolável, você só adicionou latência de coordenação.
Custo, latência e quando paga a conta
Os números que a Anthropic publicou para o sistema de research deles:
| Métrica | Single agent (Opus) | Multi-agente (Opus + Sonnet) |
|---|---|---|
| Performance em pesquisa complexa | baseline | +90.2% |
| Tokens consumidos vs chat | ~4x | ~15x |
| Tempo para queries complexas | baseline | até 90% mais rápido (paralelização) |
| Variância explicada por uso de tokens | — | 80% |
Tradução para custo real, com pricing público de 2026: Opus 4.7 a USD 5/USD 25 por MTok (input/output), Sonnet 4.6 a USD 3/USD 15, Haiku 4.5 a USD 1/USD 5. Um pesquisador rodando em Haiku pra ler 200k tokens de código custa USD 0,20. O mesmo trabalho em Opus custa USD 1. A escolha de modelo por papel não é detalhe, é o que separa um setup que paga conta de um que queima budget.
A regra prática: subagente caro só onde a decisão é cara. Pesquisa e validação puxe pra Haiku ou Sonnet. Execução, principalmente em código de produção, justifica Sonnet ou Opus.
Quando NÃO dividir
Lista curta de armadilhas que vejo em time que acabou de descobrir o padrão:
- Tarefa pequena. Renomear variável, ajustar copy, fix de bug em uma função. Single agent e ferramenta certa resolvem mais rápido.
- Contexto compartilhado. Se pesquisador, executor e validador iam ler os mesmos arquivos, você duplicou contexto, não dividiu.
- Pipeline de subagentes em série rígida. Cada chamada adiciona round-trip. Se não há paralelismo real, comprime de novo.
- Subagente que só repassa. Se o subagente devolve quase tudo que recebeu, ele está só onerando o budget.
A pergunta que você faz antes de criar mais um arquivo em .claude/agents/: o que esse subagente vê que o orquestrador não precisa ver? Se a resposta é "nada relevante", não crie.
FAQ
Subagente pode chamar outro subagente? Não. A documentação oficial é explícita: subagents não fazem nesting. Quem coordena é o agente principal. Isso evita explosão combinatorial e mantém o custo previsível.
Como passo contexto pro subagente? Pelo prompt da invocação. Subagent não herda o histórico do orquestrador. Ele recebe só o system prompt do arquivo dele mais o que você (ou o orquestrador) escreve na chamada. É feature, não bug. É exatamente isso que mantém a janela limpa.
Vale pagar 15x mais tokens? Para tarefa com valor alto (pesquisa, refatoração de módulo crítico, migração), sim. Para tarefa rotineira, não. A própria Anthropic recomenda começar com agente único e só escalar quando há evidência de que o problema é contexto, não capacidade.
Posso usar Haiku para os subagentes? Sim, e na maioria dos casos você deve. Pesquisa, leitura de log, validação de teste. Haiku resolve com qualidade e custa um quinto do Opus. Reserve Opus pro orquestrador e pro executor em código de produção.
Conclusão
Subagente não é um truque para economizar token. É reconhecer que arquitetura de IA em produção é, antes de tudo, arquitetura de contexto. Você decide o que cada Claude vê, e o que ele vê define o que ele decide. Pesquisador, executor e validador é só a versão mais limpa do princípio: trabalho dividido por aquilo que o agente precisa enxergar, não por etapa do processo.
Esse tipo de decisão de harness, quando dividir, qual modelo por papel, como amarrar formato de saída, é o que diferencia um agente de demo de um que aguenta produção. É exatamente o foco do Harness Engineering com Claude Code, workshop ao vivo nos dias 16 e 17 de maio em que a galera constrói do zero, com Claude Code, Laravel e NativePHP, um app que recebe link de produto, pesquisa alternativas em e-commerces e devolve recomendação estruturada. Produto real, dois dias, o tipo de orquestração de subagentes que esse post descreve aplicada na prática.
A próxima fronteira é exatamente essa. Não vai ser quem usa IA. Vai ser quem sabe arquitetar contexto.

{AI Engineer} — apaixonado por Laravel, arquitetura de software e construir produtos com impacto. Compartilho aqui tutoriais, descobertas e reflexões sobre o dia a dia de engenharia.
Você também pode gostar
Sistemas multiagentes: arquitetura e orquestração assíncrona na prática
O que são sistemas multiagentes, quando vale dividir o trabalho em vários agentes e como orquestrar de forma assíncrona com asyncio. Arquitetura orquestrador-worker, o padrão de produção da Anthropic e quando NÃO dividir.
Multi-agent com Claude: separando search, judge e writer (e quando isso é overengineering)
Quando vale a pena quebrar o agente único em sub-agentes especializados (search, judge, writer) e quando isso vira complexidade desnecessária. Padrão de orquestração com Claude, custo real em tokens e quando voltar para single-agent.

Engenharia de contexto: o que vai no prompt (e o que NÃO vai)
O recurso mais escasso de um agente é a janela de contexto. Veja como decidir o que entra no prompt — system prompt, exemplos, histórico, dados recuperados — e por que encher de contexto degrada a resposta.
Plan-and-Execute: o pattern que cortou 90% do custo do nosso agente
Agente nosso queimava US$ 2.300/mês rodando Claude Opus em loop. Trocamos por Plan-and-Execute: uma chamada cara que planeja, N chamadas baratas que executam. Conta nova: US$ 220/mês com a mesma qualidade. Planilha de tokens, código Laravel (PlanJob + ExecuteStep) e o tipo de fluxo onde esse pattern quebra.
