Ferramentas de engenharia de contexto que eu uso em produção
Tem um momento, quando você bota um agente pra rodar de verdade, que o prompt deixa de ser o problema. O modelo é bom. A instrução está clara. E mesmo assim o agente começa a errar depois de 40 turnos, esquece o que decidiu no começo, repete chamada de ferramenta. O problema não é o prompt. É o contexto.
Engenharia de contexto é a disciplina de curar o que entra na janela do modelo a cada chamada — system prompt, histórico, resultado de ferramenta, memória, documento recuperado. A própria Anthropic define como "o conjunto de estratégias para curar e manter o conjunto ótimo de tokens durante a inferência" (Anthropic). E isso deixou de ser arte de prompt pra virar stack: tem API, tem lib, tem ferramenta de observabilidade.
Neste post eu vou listar as ferramentas de engenharia de contexto que eu uso em produção, divididas por função: gestão de janela, compressão, recuperação e observabilidade. Sem ranking de hype. É o que segura o agente em produção de verdade.
TL;DR
- O que é: o conjunto de ferramentas que controla o que entra (e o que sai) da janela de contexto de um agente em produção.
- Stack/Modelos: API de context management da Anthropic (Claude), LangGraph/LangMem, LangSmith, vector DB (Weaviate/Pinecone).
- Custo/Acesso: parte é nativa da API (clearing é server-side e de graça), parte é open-source, parte exige infra própria.
- Link útil: Effective context engineering for AI agents — Anthropic.
O contexto: por que isso virou stack?
Antes a conversa era simples. Você escrevia um prompt bom e pronto. Hoje o agente roda em loop: chama ferramenta, lê arquivo, raciocina, chama de novo. Cada passo joga token na janela. E aí bate o context rot: estudos de "agulha no palheiro" mostram que, conforme o número de tokens na janela cresce, a capacidade do modelo de recuperar informação com precisão cai (Anthropic).
Traduzindo pro impacto em produto: janela cheia não é só caro, é pior. Um agente com 300 mil tokens de lixo acumulado responde com menos precisão do que o mesmo agente com 80 mil tokens curados. No cookbook da Anthropic, um agente de pesquisa sem nenhuma gestão chegou a 335.279 tokens de contexto — 96% disso era conteúdo de arquivo lido e nunca mais usado (Claude Cookbook).
Por isso a comunidade parou de tratar contexto como "escrever prompt" e começou a tratar como engenharia: dá pra medir, dá pra otimizar, e agora tem ferramenta de prateleira pra cada parte do problema. A boa engenharia de contexto, no fim, é achar o menor conjunto de tokens de alto sinal que maximiza o resultado. (Se o seu problema ainda é decidir o que entra no prompt antes de pensar em ferramenta, comece por o que vai no contexto e o que não vai.)
As ferramentas de engenharia de contexto que eu uso em produção
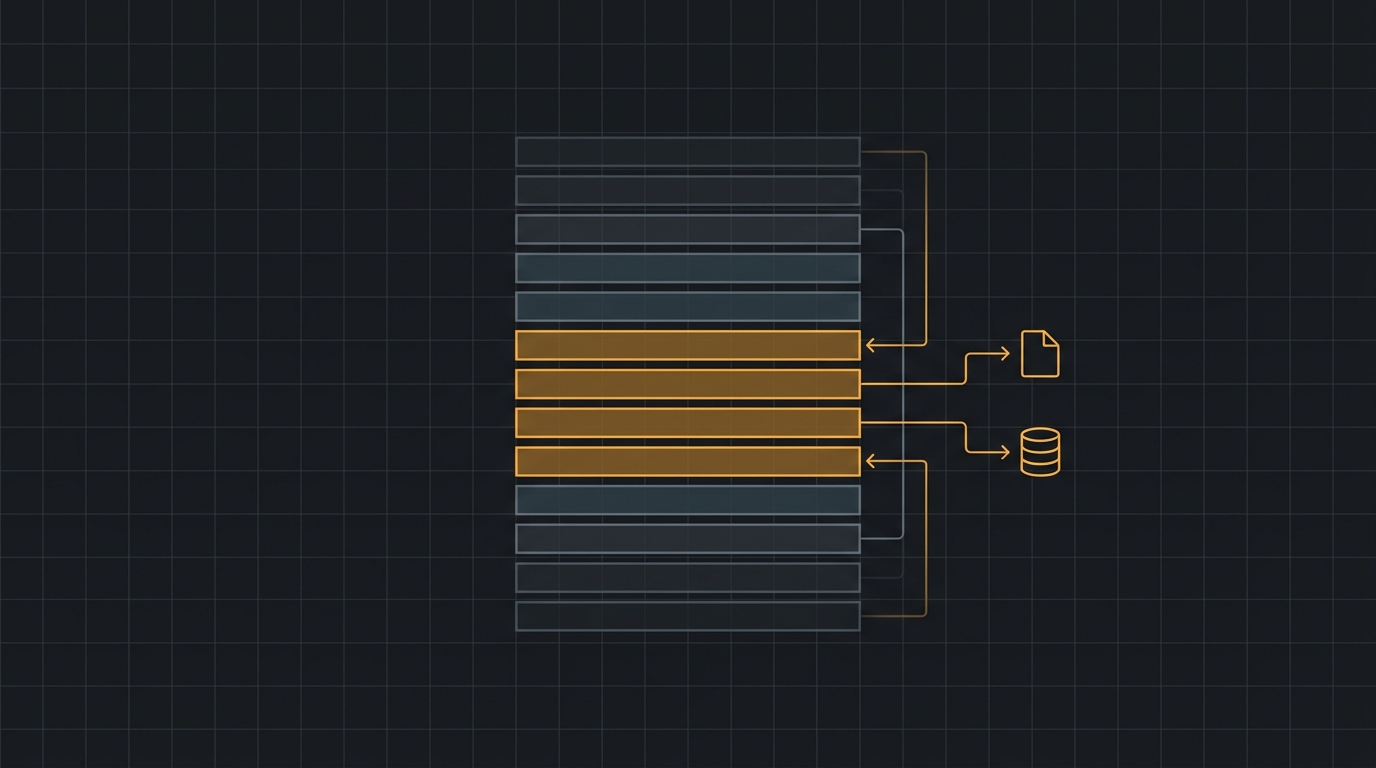
Eu separo por função. Cada agente que vai pra produção precisa resolver os quatro: segurar a janela, comprimir o que sobra, recuperar o que faz falta e enxergar o que está acontecendo.
1. Gestão de janela: Context Editing e Compaction (nativos da API)
Essa é a primeira coisa que eu ligo. A Anthropic expõe um campo context_management na API que faz pruning da janela sem você ter que reimplementar nada.
São dois mecanismos. O tool-result clearing (clear_tool_uses_20250919) troca resultados antigos de ferramenta por um placeholder, mantendo o registro da chamada. É a forma mais leve de compactação que existe — roda server-side e não custa nada de inferência. No teste do cookbook, ele derrubou o pico de contexto de 335 mil para 173.137 tokens (~48% de redução), liberando 163.817 tokens de leituras de arquivo que não eram mais necessárias.
context_management = {
"edits": [{
"type": "clear_tool_uses_20250919",
"trigger": {"type": "input_tokens", "value": 30_000},
"keep": {"type": "tool_uses", "value": 4}, # mantém os 4 últimos resultados
"clear_at_least": {"type": "input_tokens", "value": 10_000},
"exclude_tools": ["memory"], # nunca limpa a memória
}]
}
O segundo é a compaction (compact_20260112): quando a conversa em si — diálogo e raciocínio — enche a janela, o modelo resume tudo num bloco comprimido e reinicia a partir dele. No mesmo teste, com gatilho em 180 mil tokens, o pico caiu pra 169.164 tokens. Você pode passar instructions próprias pra garantir que os fatos que importam pro seu domínio sobrevivam ao resumo.
2. Compressão: sub-agentes e nós de sumarização
Clearing e compaction cuidam do volume bruto. A compressão de verdade vem de arquitetura de sub-agentes. Em vez de um agente gigante que carrega tudo, você delega tarefas focadas a sub-agentes com janela limpa, e cada um devolve só um resumo destilado — tipicamente 1.000 a 2.000 tokens — pro agente coordenador (Anthropic).
O ganho é direto: o trabalho pesado de explorar 30 arquivos acontece numa janela que você joga fora depois. O coordenador só vê a conclusão. Já destrinchei esse padrão de pesquisador/executor/validador com números reais em subagentes na prática. Em LangGraph dá pra fazer isso com nós de sumarização e utilitários de trimming de mensagem aplicados em pontos específicos do grafo — o que a LangChain chama de compress context: "reter apenas os tokens necessários para executar a tarefa" (LangChain).
3. Recuperação: memory tool, just-in-time e vector DB
Comprimir bem é metade. A outra é só trazer pra janela o que faz falta, na hora que faz falta — o padrão just-in-time: em vez de pré-carregar tudo, o agente mantém identificadores leves (caminhos de arquivo, queries salvas, links) e carrega o dado em runtime quando precisa.
Pra memória que cruza sessões eu uso a memory tool (memory_20250818) da Anthropic. É uma ferramenta client-side: o Claude chama comandos como view, create e str_replace, e você executa a escrita num diretório seu. Numa sessão de pesquisa, o agente escreveu ~3.000 tokens de achados em /memories; na sessão seguinte ele leu essas notas primeiro, em vez de reler os documentos do zero (Claude Cookbook).
Quando a base de conhecimento é grande, memória de arquivo não escala — aí entra vector DB (Weaviate, Pinecone) como memória de longo prazo, com RAG por cima. E aqui não tem mágica: o seu RAG é tão bom quanto o que ele recupera. Chunking, embeddings e reranking são parte da engenharia de contexto, não um detalhe de infra (Weaviate). E antes de sair plugando RAG em tudo, vale o mapa de quando usar RAG, fine-tuning ou contexto. Em LangGraph isso aparece como memória de longo prazo com retrieval por embedding, e a LangChain ainda separa esse "select context" do "write context" feito pela LangMem.
4. Observabilidade de contexto: LangSmith e context awareness
Você não otimiza o que não enxerga. Antes de mexer em gatilho de clearing ou em estratégia de chunk, eu preciso ver o que entrou na janela em cada turno. LangSmith é o que eu uso pra tracing e avaliação: dá pra inspecionar token a token o que o agente recebeu e medir o impacto de cada mudança de contexto (LangChain).
Do lado da API tem o context awareness: o modelo recebe feedback em tempo real de quanto resta de capacidade na janela depois de cada chamada de ferramenta. Isso muda o comportamento do agente — ele aprende a ser econômico quando sabe que está perto do limite, em vez de estourar no meio de uma tarefa longa.
Tutorial te mostra o caminho — no Clã você constrói junto. Aula ao vivo toda semana, projetos reais de Engenharia de IA, ao lado de quem já está em produção.
Entrar no ClãComo eu junto tudo num harness real
Na prática esses mecanismos compõem. A própria Anthropic recomenda empilhar os três edits nativos, na ordem certa: limpa o thinking antigo, depois os resultados de ferramenta, e só compacta a conversa quando ela ficar muito grande — sempre deixando a memória de fora do clearing.
context_management = {
"edits": [
{"type": "clear_thinking_20251015",
"trigger": {"type": "input_tokens", "value": 100_000}},
{"type": "clear_tool_uses_20250919",
"trigger": {"type": "input_tokens", "value": 80_000},
"keep": {"type": "tool_uses", "value": 6},
"exclude_tools": ["memory"]},
{"type": "compact_20260112",
"trigger": {"type": "input_tokens", "value": 200_000},
"instructions": "Preserve decisões de arquitetura, bugs encontrados e números."},
]
}
Por cima disso: memory tool pra cruzar sessões, sub-agentes pro trabalho pesado, vector DB pro conhecimento grande e LangSmith pra enxergar tudo. Esse é o harness. Não é prompt — é arquitetura de contexto.
Limitações e pontos de atenção
Onde você se queima se não souber:
- Limpar tem custo escondido. Se o agente precisar de um arquivo que o clearing já apagou, ele tem que chamar a ferramenta de novo. Ajuste
keeppelo seu workload — clearing agressivo demais vira retrabalho. - Compaction perde o específico. No teste do cookbook, fatos de alto nível sobreviveram ao resumo, mas valores estatísticos obscuros de uma tabela de apêndice foram descartados. Se um número específico é crítico, escreva ele na memória — não confie no resumo.
- Cada edit invalida cache. Mexer no início da janela quebra o prompt caching. Por isso existe o
clear_at_least: só vale limpar se for liberar token suficiente pra compensar. - RAG ruim envenena o contexto. Recuperar o chunk errado é pior que não recuperar nada — você está injetando ruído com cara de fato. Meça a qualidade do retrieval antes de culpar o modelo.
FAQ rápido
Engenharia de contexto é a mesma coisa que engenharia de prompt? Não. Engenharia de prompt é escrever a instrução. Engenharia de contexto é gerenciar tudo que cerca essa instrução ao longo de uma sessão inteira — histórico, ferramentas, memória, recuperação. O prompt é um turno; o contexto é o agente vivo.
Preciso de framework ou dá pra fazer na mão?
A gestão de janela já é nativa na API do Claude (context_management), então o básico você liga sem framework. LangGraph/LangMem ajudam quando você quer orquestrar sub-agentes e memória com mais estrutura. Vale pela observabilidade do LangSmith, não pela mágica.
O tool-result clearing custa token? Não. É uma edição server-side: a Anthropic remove o conteúdo antes da próxima inferência, sem cobrar pela operação. A compaction, sim, custa — é uma chamada de inferência pra gerar o resumo.
Quando uso memory tool e quando uso vector DB? Memory tool resolve memória de agente (notas, progresso, decisões) que cruza poucas sessões. Vector DB é pra base de conhecimento grande, com busca semântica. Não são concorrentes — num agente sério você usa os dois.
Conclusão
Context engineering deixou de ser sobre escrever o prompt perfeito. É sobre construir o harness que segura o agente quando a janela enche: gestão de janela nativa, compressão por sub-agente, recuperação just-in-time e observabilidade pra enxergar tudo. As ferramentas existem e a maioria é de prateleira — o trabalho é de arquitetura, não de truque.
E é exatamente esse salto — sair do prompt isolado pra um harness que aguenta produção — que a gente vai construir ao vivo, do zero, no workshop Do Prompt ao Harness: construindo um agente de vendas: a engenharia de contexto saindo do slide e virando código rodando. Porque o próximo salto do dev não é usar IA. É saber construir produto real com ela — e produto de IA em produção é arquitetura, contexto e avaliação, não prompt bonito.

{AI Engineer} — apaixonado por Laravel, arquitetura de software e construir produtos com impacto. Compartilho aqui tutoriais, descobertas e reflexões sobre o dia a dia de engenharia.
Conteúdo é o que não falta. Falta quem desembaralhe: o que importa agora é como implementar do jeito certo. No Clã você tem isso ao vivo, toda semana, com quem já filtrou o ruído.
Entrar no Clã