Claude Sonnet 5: como interpretar os benchmarks na prática
Saiu o Claude Sonnet 5 hoje, 30 de junho de 2026.
E você já sabe o que vai acontecer no seu feed nas próximas horas.
Print da tabela de benchmark. "Sonnet 5 faz 80% em tal coisa." Caption empolgada. Zero contexto.
O problema não é o número.
O problema é que número solto não te diz nada sobre o seu trabalho. Nem se você usa o Sonnet dentro do Claude Code, nem se você integra o modelo num produto.
Então vamos fazer diferente. Vou pegar os benchmarks que a Anthropic publicou no anúncio oficial, te mostrar como ler cada um, e traduzir pra decisão prática: quando o Sonnet 5 resolve, quando você ainda precisa do Opus, e quanto isso custa por tarefa.
Isso aqui não é hype. É engenharia.
Primeiro, a tabela oficial
A Anthropic colocou o Sonnet 5 lado a lado com o antecessor (Sonnet 4.6) e com o irmão mais caro (Opus 4.8, ali "for reference"):
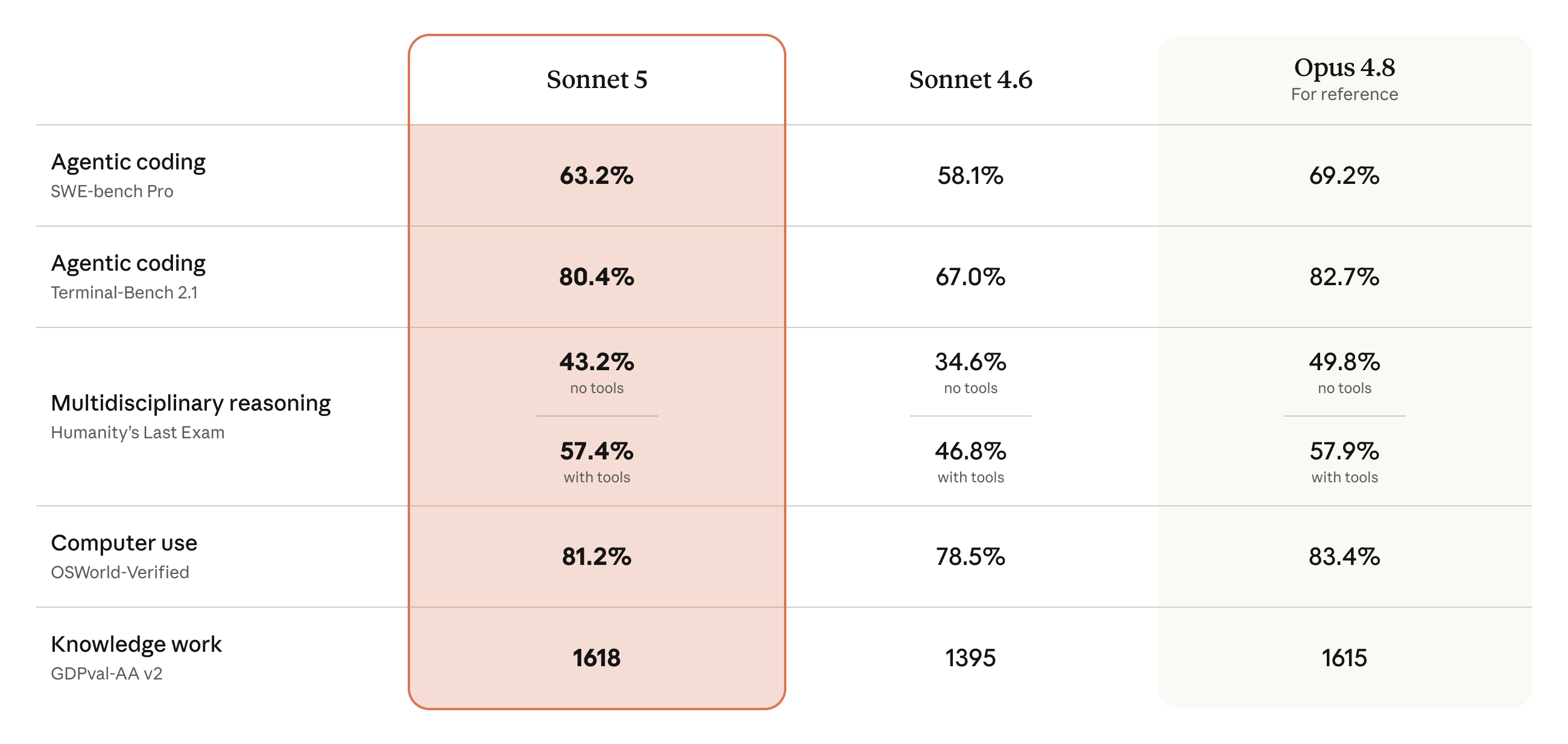
Traduzindo a tabela em texto, porque os números são o que importa:
| Benchmark | O que mede | Sonnet 5 | Sonnet 4.6 | Opus 4.8 |
|---|---|---|---|---|
| SWE-bench Pro | resolver bug/PR real num repo | 63,2% | 58,1% | 69,2% |
| Terminal-Bench 2.1 | trabalhar no terminal, rodar CLI | 80,4% | 67,0% | 82,7% |
| Humanity's Last Exam (sem tools) | raciocínio puro, sem ferramentas | 43,2% | 34,6% | 49,8% |
| Humanity's Last Exam (com tools) | raciocínio com busca/execução | 57,4% | 46,8% | 57,9% |
| OSWorld-Verified | usar o computador (mouse, tela, apps) | 81,2% | 78,5% | 83,4% |
| GDPval-AA v2 | trabalho de conhecimento "de escritório" | 1618 | 1395 | 1615 |
Antes de qualquer leitura fina, três coisas saltam:
- O Sonnet 5 esmaga o 4.6 em quase tudo. O salto no Terminal-Bench (67% → 80,4%) e no GDPval (1395 → 1618) é grande.
- Ele chega perto do Opus 4.8 em vários eixos. E no GDPval-AA v2 ele passa o Opus (1618 contra 1615).
- Em coding "duro" (SWE-bench Pro), ainda tem uma folga pro Opus: 63,2% contra 69,2%.
Guarda essas três. Agora vem a parte que ninguém te mostra.
O eixo que falta em todo print: o custo
Aqui está o erro de leitura mais comum. A galera olha o número de acerto e ignora quanto custou pra chegar nele.
A própria Anthropic publicou os gráficos do jeito certo: acerto no eixo Y, custo por tarefa no eixo X (escala log). E mais: cada modelo aparece como uma curva, não como um ponto. Cada bolinha é um nível de esforço — low, medium, high, xhigh, max.
Olha o de busca agêntica (BrowseComp):
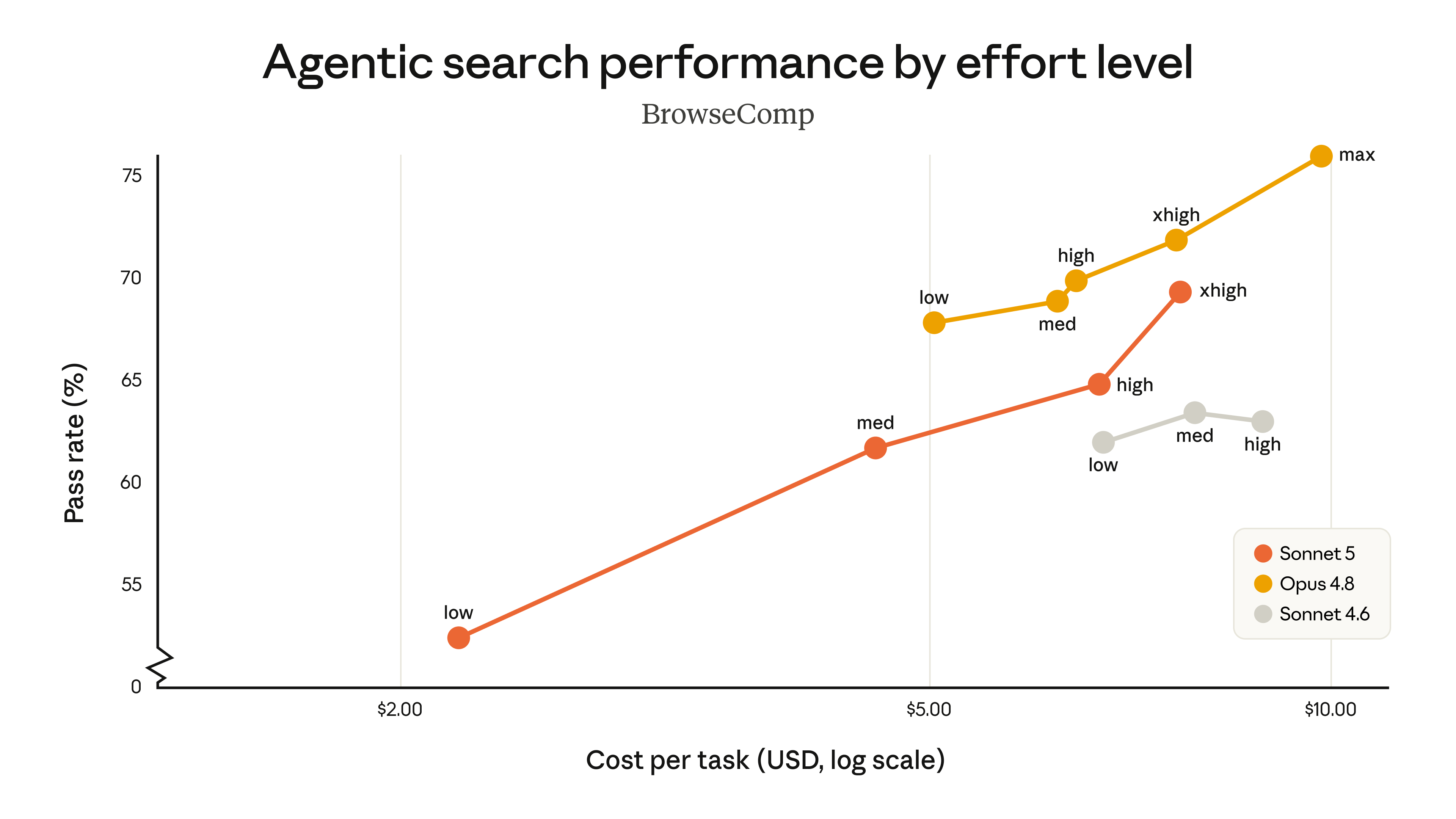
Lê assim: você não escolhe "o Sonnet 5". Você escolhe um ponto na curva do Sonnet 5. No esforço low, ele resolve menos mas custa quase nada por tarefa. Subindo pra high e xhigh, ele acerta mais e gasta mais. A curva inteira do Sonnet 5 (laranja) fica abaixo e à esquerda da do Opus (amarelo) — mais barato pelo mesmo acerto — e acima da do Sonnet 4.6 (cinza) o tempo todo.
O mesmo padrão no computer use (OSWorld-Verified):
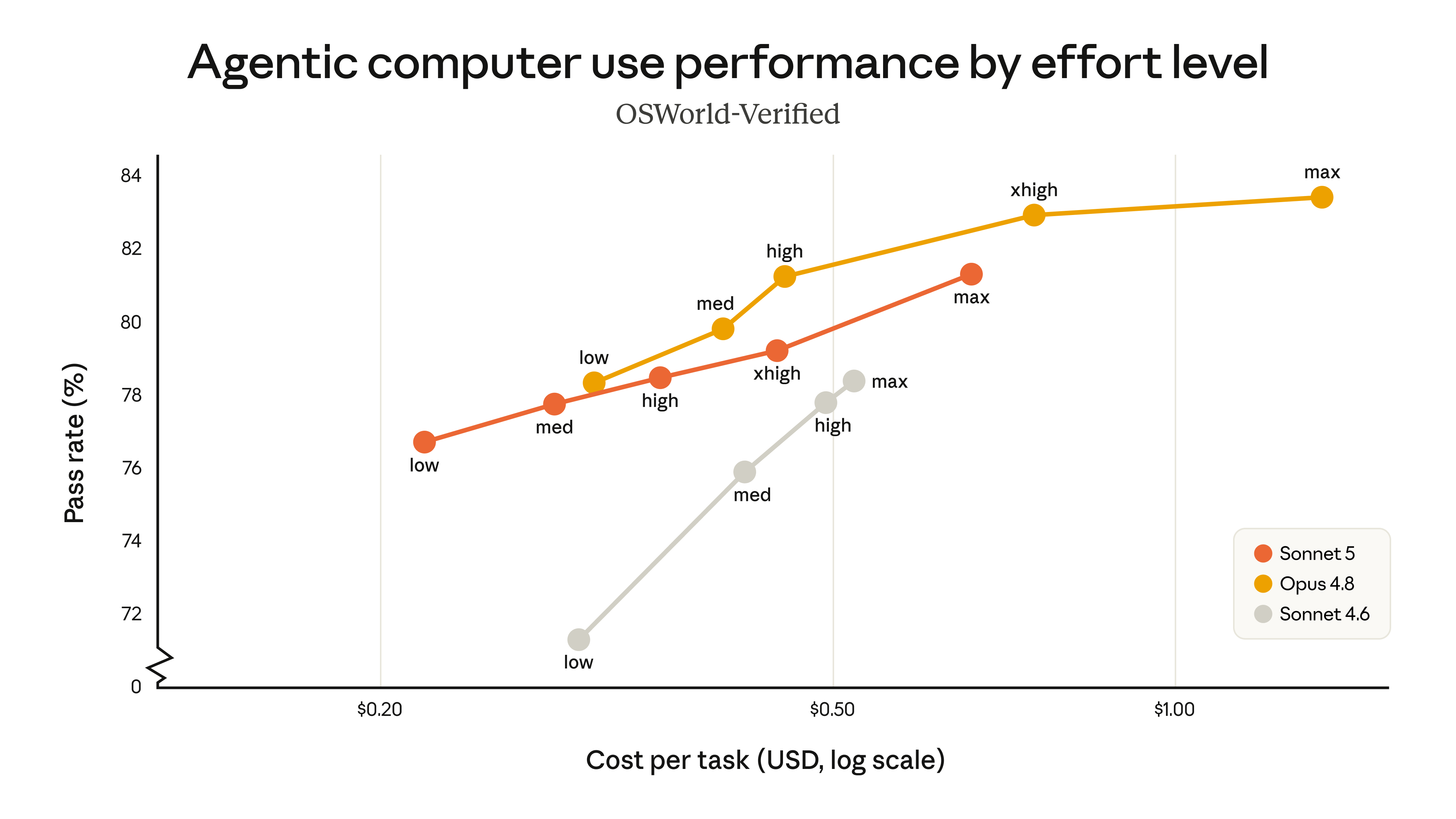
Repara que o Sonnet 5 no low (uns US$ 0,21 por tarefa) já bate o Sonnet 4.6 no max (uns US$ 0,50). Mesmo eixo, metade do custo, mais acerto.
É isso que "modelo melhor" significa de verdade. Não é "subiu X pontos". É: a curva inteira de custo-versus-acerto se deslocou pra um lugar melhor. Pra cada nível de qualidade que você precisa, agora paga menos.
Quem só lê o número de pico está olhando uma bolinha de uma curva e jogando o resto fora.
SWE-bench Pro e Terminal-Bench medem coisas diferentes
Esses dois aparecem juntos sob "agentic coding", mas não são a mesma coisa — e a diferença importa pro seu dia.
SWE-bench Pro pega bug ou pull request real de repositório open source e pergunta: o modelo consegue, sozinho, entender o issue, achar os arquivos, escrever o patch e passar nos testes? É a tarefa mais perto de "fecha esse card pra mim de ponta a ponta". É a mais difícil — daí o 63,2%, bem abaixo dos outros benchmarks.
Terminal-Bench mede outra habilidade: operar no terminal. Rodar comando, ler a saída, encadear ferramenta de CLI, se virar num shell. É a mecânica do loop agêntico, não o raciocínio sobre o código em si. Daí o número alto, 80,4%.
Por que separar importa? Porque um modelo pode ser ótimo de terminal e medíocre de resolver o bug — ele executa lindamente os passos errados. Quando você compara modelos pra coding agêntico, esses dois eixos contam histórias diferentes, e o vencedor muda conforme o cenário. Olhar só um deles é como avaliar um motorista só pela velocidade, ignorando se ele chegou no endereço certo.
"Com ferramentas" vs "sem ferramentas": o número que importa pra quem integra
Olha de novo a linha do Humanity's Last Exam. Sonnet 5: 43,2% sem ferramentas, 57,4% com ferramentas.
Catorze pontos de diferença. Mesmo modelo, mesmas perguntas. A única mudança é dar a ele busca e execução de código.
Essa é a métrica mais importante pra quem constrói produto com IA, e a mais ignorada.
Porque o modelo "no vácuo" — só pesos, sem nada plugado — não é o que você coloca em produção. Em produção ele tem RAG, tem function calling, tem acesso ao seu banco, à sua API, à documentação. A coluna "com tools" é a que se parece com o seu sistema real.
Lição prática: quando você for escolher modelo pra um agente, o benchmark "sem ferramentas" é quase folclore. O que prevê o comportamento do seu produto é "o modelo sabe usar as ferramentas que EU dou?". E é exatamente nesse eixo que o Sonnet 5 deu o maior salto sobre o 4.6 (46,8% → 57,4%).
Se a sua arquitetura de IA não dá boas ferramentas pro modelo, você está rodando ele na coluna errada da tabela — e culpando o modelo pelo que é limitação do seu harness.
O que o Sonnet 5 muda no Claude Code na prática
Aqui é onde a teoria vira mão na massa.
O Claude Code expõe justamente o que aqueles gráficos mostram: você controla o nível de esforço do modelo. É a mesma escala low/medium/high/max das curvas lá de cima. Não é firula de config — é o botão que move você ao longo da curva de custo-acerto.
Com o Sonnet 5, isso fica mais interessante por um motivo simples: a curva dele inteira é melhor. Na prática:
- Tarefa mecânica (renomear, ajustar teste, mexer em config, escrever boilerplate): Sonnet 5 em esforço baixo. Pelos gráficos, ele entrega no
low/mediumo que o 4.6 só entregava nohigh. Você gasta menos token e termina mais rápido. - Tarefa de raciocínio (entender um bug chato, refatorar com cuidado, planejar uma feature): sobe o esforço. Você anda pra direita na curva, paga mais por tarefa, e o acerto acompanha.
- O Sonnet 5 vira o default honesto. Antes, pra muita coisa séria você pulava direto pro Opus. Agora o Sonnet 5 cobre boa parte do caminho a uma fração do custo — e o preço introdutório ajuda: US$ 2 por milhão de tokens de entrada e US$ 10 de saída até 31 de agosto de 2026 (depois sobe pra US$ 3 / US$ 15).
Quando ainda vale o Opus 4.8? Onde a folga é real: SWE-bench Pro (69,2% contra 63,2%) e raciocínio puro sem ferramentas (HLE 49,8% contra 43,2%). Tradução: bug genuinamente difícil em código, ou raciocínio pesado sem muletas de ferramenta. Pro resto do fluxo de Claude Code no dia a dia, o Sonnet 5 segura — e essa decisão de "qual modelo pra qual tarefa" é metade do jogo de não transformar agente em prejuízo.
E pra quem integra IA em produto
Se você bota o Sonnet 5 atrás de uma API, a leitura dos benchmarks vira decisão de arquitetura e de custo:
- OSWorld-Verified (81,2%) é o sinal pra agente que mexe em interface — navegador, apps, automação de tela. O Sonnet 5 está a três pontos do Opus aqui, por um custo bem menor por tarefa. Pra esse tipo de carga, ele é a escolha de custo-benefício óbvia.
- GDPval-AA v2 (1618) é "trabalho de escritório" — relatório, análise, tarefa de conhecimento de ponta a ponta. Ele passou o Opus 4.8 nesse. Se o seu produto é assistente de trabalho, leia isso com atenção: você não precisa pagar Opus pra ter qualidade Opus aqui.
- Faça a conta por tarefa, não por token. O eixo X daqueles gráficos é dólar por tarefa, não por token, de propósito. Um modelo que precisa de menos idas e voltas pra resolver pode sair mais barato no fim mesmo com preço de token parecido. É a métrica que entra na sua planilha de unit economics — não o número de pico do benchmark.
- Dê ferramentas de verdade. Voltando ao ponto do HLE: o ganho de "com tools" só aparece se as suas ferramentas forem boas. Schema claro, descrição honesta, retorno enxuto. O modelo é metade; o harness é a outra metade.
A Anthropic ainda destaca que o Sonnet 5 alucina e bajula menos que o 4.6, recusa melhor pedido malicioso e resiste mais a prompt injection — com os cyber safeguards ligados por padrão. Pra quem coloca isso na frente de usuário real, isso é tão "feature" quanto qualquer ponto de benchmark.
Fechando
Lançou modelo novo? Ótimo. Mas não leia benchmark como placar de futebol.
Um número de acerto sozinho não diz se vale pro seu caso. O que diz é a curva inteira: quanto acerto, a que custo, com quais ferramentas, em qual tarefa. SWE-bench Pro e Terminal-Bench medem coisas diferentes. "Com tools" é a coluna que parece com a sua produção. E o nível de esforço é o botão que você de fato controla — no Claude Code e na API.
O Sonnet 5 é, no fim, um deslocamento de curva: qualidade perto de Opus numa fatia grande do trabalho, a um custo bem menor. Isso muda mais a sua conta do que qualquer manchete de "X%".
E se você quiser ir mais fundo em qual modelo usar pra qual cenário de código, o comparativo lado a lado de Claude Code, Cursor e Copilot continua valendo — agora é só trocar o Sonnet pela versão 5 e refazer a conta por tarefa.

{AI Engineer} — apaixonado por Laravel, arquitetura de software e construir produtos com impacto. Compartilho aqui tutoriais, descobertas e reflexões sobre o dia a dia de engenharia.
Você também pode gostar

Code Review com IA sem virar carimbador: padrões que pegam bug e ignoram estilo
Todo PR abre, o bot comenta a mesma coisa: considere adicionar testes, refatore isso, verifique aquilo. Em duas semanas o time muta o canal. Code review com IA não é problema de modelo, é problema de filtro. Neste post: prompt em três camadas, ferramentas que validam antes de palpitar, scoring de confiança 0 a 100 com threshold de 80, workflow Laravel + Claude no GitHub Actions pronto para colar e uma métrica honesta de precision e recall do bot.

Qual IA usar para programar em 2026: Claude Code vs Codex
Comparativo prático entre Claude Code e Codex para coding agêntico em 2026: onde cada um ganha em repo real, terminal e custo. A melhor IA para programar em 2026 não é um nome — é uma decisão de cenário.
Portfólio de AI Engineer: 5 projetos que abrem porta sem precisar de mestrado
Recrutador olha 11 segundos. Notebook de fine-tuning de Llama no Colab não convence ninguém. Cinco projetos pequenos que provam skill real de AI engineer e cabem em 1 a 3 fins de semana cada.
Claude Opus 4.8 chegou: o que muda de verdade pra quem entrega IA em produção
A Anthropic lançou o Claude Opus 4.8 hoje. Filtramos o que importa pra quem coda e roda agentes: liderança no SWE-Bench Pro, 84% em browser-agent, tool calling com menos passos, 4x menos bug sem comentar, multimodal 61% mais barato e Dynamic Workflows com centenas de subagentes no Claude Code, tudo no mesmo preço do 4.7.
