30 perguntas de entrevista para AI engineer (e como eu respondo cada uma)

30 perguntas de entrevista para AI engineer (e como eu respondo cada uma)
Em maio de 2026 o BeBee lista mais de 540 mil vagas de Senior AI Engineer no Brasil, com faixa salarial entre R$ 72 mil e R$ 110 mil por ano. A Robert Half coloca Engenheiro de Inteligência Artificial entre R$ 19,5 mil e R$ 27 mil por mês. O mercado paga.
Só que o processo seletivo mudou. Em 2026, 60% das perguntas técnicas são sobre GenAI: RAG, evals, agentes, custo em produção. CNN e gradient descent ocuparam até pouco tempo a maior parte da prova técnica — hoje viraram ~25%. Quem chega no painel sabendo só "como funciona um transformer" toma vaga de junior.
Compilei aqui 30 perguntas que vi (eu mesmo ou candidatos do nosso círculo) em entrevistas reais de maio de 2026: OpenAI, Anthropic, fintechs brasileiras, startups de RAG, healthtechs. Mais 5 perguntas reversas pra você fazer pra empresa — porque entrevista é mão dupla, e tem muita vaga de "AI engineer" que é só prompt em produção sem evals.
TL;DR
- O que tem aqui: 30 perguntas (10 técnicas, 10 de arquitetura, 10 comportamentais) com 3 respostas cada — resposta curta (30s), resposta de senior (2min) e o red flag de junior. Mais 5 perguntas reversas pra filtrar empresa.
- Pra quem é: dev PHP/Python virando AI engineer, AI engineer pleno preparando salto pra senior, e gestor que precisa estruturar painel de entrevista.
- O que não é: lista de fórmulas decoradas. Cada resposta tem que sair do seu repertório, não da minha cópia.
- Fontes-base: compilados como DataCamp LLM 2026, as 8 perguntas que OpenAI/Anthropic/Google realmente fazem e o levantamento de 100 entrevistas reais do Adil Shamim.
Como ler esse compilado
Cada pergunta tem três respostas em camadas, porque entrevista boa não é monólogo. Você responde curto, o entrevistador puxa, você aprofunda.
- Resposta curta (30s): o que sai da boca primeiro. Frase de impacto + o conceito-chave. Funciona em screening de recrutador e em pergunta de aquecimento.
- Resposta de senior (2min): quando o entrevistador pede pra aprofundar. Aqui entram tradeoffs, números, nomes de ferramentas, papers, decisões de arquitetura.
- Red flag de junior: o que NÃO falar. Isso é o que separa quem leu tutorial de quem rodou em produção.
Bora.
10 perguntas técnicas
1. Como funciona o mecanismo de self-attention num transformer?
Resposta curta (30s): cada token gera três vetores — query, key, value — e atende a todos os outros tokens da janela calculando similaridade entre query e key. Isso quebra a sequencialidade do RNN e permite paralelizar treinamento.
Resposta senior (2min): entro nos detalhes de complexidade O(n²) na sequência, falo de multi-head attention dividindo o espaço de representação em sub-espaços paralelos, cito grouped query attention como otimização de memória do KV cache (Llama, Mistral, GPT-4 turbo), e menciono FlashAttention como reescrita IO-aware que reduziu memória em ordens de magnitude. Encerro conectando ao impacto: é por causa do KV cache que inference é memory-bound, não compute-bound, e é por isso que técnicas como PagedAttention (vLLM) ganharam tração.
Red flag de junior: "attention é tipo onde o modelo presta atenção nas palavras importantes". Sem mencionar Q/K/V, sem complexidade quadrática, sem KV cache.
2. Embeddings: o que são e onde quebram?
Resposta curta (30s): embeddings são representações vetoriais densas que mapeiam significado pra espaço euclidiano. Quebram em negação ("não cancele meu plano" e "cancele meu plano" ficam vizinhos), em raciocínio temporal e em domínio específico fora da distribuição de treino.
Resposta senior (2min): explico bi-encoder (rápido, embeddings independentes) vs cross-encoder (mais preciso, atende sobre o par). Cito ColBERT v2 com late interaction como meio-termo. Discuto dimensionalidade (Matryoshka embeddings da OpenAI permitindo truncagem), hard negative mining para fine-tuning de retriever, e onde substituo por reranker (quando o domínio é jurídico, médico ou tem entidades muito específicas). Recomendação prática: avalio retrieval com Recall@k e MRR no meu golden set antes de tocar no modelo de embedding.
Red flag de junior: "embedding é tipo um hash semântico". Confundir embedding com hash é o primeiro sinal de quem nunca debugou retrieval ruim.
3. Qual a diferença entre tokenização BPE, WordPiece e SentencePiece — e por que isso importa?
Resposta curta (30s): todas são subword tokenization, mas BPE (GPT, Llama) merge pares mais frequentes, WordPiece (BERT) merge pelo ganho de likelihood, SentencePiece (T5, Llama) trata o input como stream de bytes sem assumir whitespace. Importa porque tokens cobram, e tokenização ruim em português infla custo em até 30%.
Resposta senior (2min): menciono o problema clássico de português e japonês com tokenizers treinados em inglês — uma frase em pt-br pode usar 1.5–2x mais tokens que o inglês equivalente. Falo do impacto em contexto efetivo, custo de API e latência. Cito que o tokenizer do GPT-4o (tiktoken o200k) é melhor pra português que o do GPT-3.5. Encerro com o teste prático: rodo o mesmo prompt no tokenizer de cada provider antes de bater martelo em quem vai pra produção.
Red flag de junior: "tokens são tipo palavras". Quem nunca pagou conta de OpenAI em real responde isso.
4. Por que LLM inference é memory-bound, não compute-bound?
Resposta curta (30s): porque cada token novo precisa atender a todo o KV cache acumulado. A operação é matriz × vetor pequeno repetida muitas vezes — o gargalo é largura de banda de memória, não FLOPS de GPU.
Resposta senior (2min): entro em prefill (compute-bound, processa todo o prompt em paralelo) vs decode (memory-bound, gera token por token). Explico por que GPUs A100/H100 ficam ociosas em ~60% durante decode se você não fizer continuous batching. Cito vLLM com PagedAttention reduzindo fragmentação de KV cache, speculative decoding como técnica pra usar o "tempo morto" do decode, e tensor parallelism vs pipeline parallelism pros casos onde o modelo não cabe em uma GPU. Conecto ao impacto financeiro: TPS por dólar é a métrica que importa, não throughput puro.
Red flag de junior: "depende do modelo". Não. Decode autoregressive é memory-bound por construção.
5. Temperature, top-k, top-p — qual o impacto prático?
Resposta curta (30s): temperature reescala a distribuição de probabilidade (alta = mais diverso, baixa = mais determinístico). Top-k corta os K tokens mais prováveis. Top-p (nucleus sampling) corta no menor conjunto cuja soma de probabilidade ≥ p. Pra produção, normalmente uso temperature 0–0.3 e top-p 0.95.
Resposta senior (2min): menciono que temperature 0 não é determinístico de verdade em provider remoto por causa de batching não-determinístico (problema documentado pela OpenAI). Pra rerun reproducible, fixo seed e aceito que ainda assim posso ter drift. Falo de min-p sampling como evolução do top-p, e cito que pra tool calling sempre baixo temperature porque output estruturado (JSON) odeia criatividade. Em geração criativa, subo pra 0.7–0.9 e adiciono frequency penalty pra evitar loops.
Red flag de junior: "uso temperature 0.7 padrão". Padrão pra quê? Não tem padrão, tem caso de uso.
6. Como você lida com hallucination?
Resposta curta (30s): hallucination não se "lida", se mitiga em camadas: grounding com RAG, system prompt restritivo, schema de saída forçado (structured output), e validação determinística pós-modelo. Em domínio crítico, adiciono LLM-as-judge como segundo passe.
Resposta senior (2min): parto da causa raiz — LLM é gerador de probabilidade de próximo token, não banco de fatos. Detalho as 4 camadas: (1) retrieval: dou contexto autoritativo no prompt, com citação de fonte obrigatória; (2) prompt: instruo o modelo a dizer "não sei" quando o contexto não cobrir; (3) structured output: forço JSON com campos answer e sources, falha se source não tiver no contexto; (4) validação: regex/SQL/checagem com base de verdade. Cito RAGAS (faithfulness, context precision) e DeepEval pra medir hallucination rate em CI. Encerro: meta não é zero, é "alucinação acontece <X% e a gente sabe quando aconteceu".
Red flag de junior: "uso temperature 0 que resolve". Não resolve. Temperature 0 só remove variabilidade entre runs, não cria fato.
7. PEFT (LoRA / QLoRA): quando fine-tuning faz sentido em 2026?
Resposta curta (30s): fine-tuning faz sentido quando: (a) preciso de estilo/tom muito específico, (b) preciso reduzir custo migrando de modelo grande pra modelo pequeno em tarefa repetitiva, ou (c) tenho dado proprietário que não cabe em RAG. LoRA é o default — fine-tuning full é raro fora de lab.
Resposta senior (2min): entro nos números: LoRA treina ~0.1–1% dos parâmetros, ajusta matrizes de baixa rank A * B em torno dos pesos congelados. QLoRA adiciona quantização 4-bit pra treinar Llama 70B numa única H100 (Dettmers et al., 2023). Cito o critério da Anthropic e da OpenAI nas docs: se prompt engineering + RAG não resolve em 3 iterações, aí avalio fine-tune. Discuto risco: fine-tune fixa comportamento, dificulta troca de modelo base, e ataca capability sem ganhar grounding (continua alucinando). Em produção, prefiro fine-tune de modelos pequenos (Llama 3.1 8B, Qwen 2.5 7B) pra rodar self-hosted barato em tarefa repetitiva.
Red flag de junior: "fine-tune é melhor que RAG porque o modelo aprende de verdade". Não aprende fato, aprende padrão.
8. Como você escolhe entre RAG, fine-tuning e long-context?
Resposta curta (30s): RAG pra fato dinâmico e dado fresco. Fine-tune pra estilo, formato ou redução de modelo. Long-context pra documentos grandes consultados raramente. Combinação é regra — só RAG ou só fine-tune é resposta de junior.
Resposta senior (2min): monto a matriz: dado muda com frequência? → RAG. Comportamento é o problema, não o conteúdo? → fine-tune. Contexto é único e <200k tokens? → joga no prompt e usa prompt caching. Cito o famoso "lost in the middle" do Liu et al. 2023 — long-context degrada em documentos muito longos, então mesmo com Claude 1M ainda recupero antes via RAG. Discuto custo: RAG é mais caro por query (retrieval + LLM), fine-tune é caro upfront mas barato por query, long-context queima token em todo request (mitigado por prompt caching com TTL de 5min na Anthropic).
Red flag de junior: "RAG é melhor". Melhor pra quê?
9. Prompt injection e jailbreak: qual sua estratégia de defesa?
Resposta curta (30s): defesa em camadas. Separação clara entre prompt do sistema e input do usuário (delimitadores + structured output), classificador de input (Llama Guard, OpenAI moderation), least-privilege em tool use (whitelist de tools, sandbox), e classificador de output antes de devolver pro usuário.
Resposta senior (2min): parto da premissa: você não vai impedir 100%, vai aumentar o custo do atacante. Cito o OWASP LLM Top 10 com LLM01 (prompt injection) e LLM02 (insecure output handling). Detalho técnicas práticas: spotlight prompting (Microsoft), instruction hierarchy (OpenAI GPT-4o usa internamente), dual LLM pattern do Simon Willison (LLM "isolado" sem acesso a ferramentas processa input, LLM "privilegiado" só vê output sanitizado). Em agentes, dou exemplo de tool design: nunca dou ao agente uma tool execute_sql(query) raw — dou tools de domínio (get_invoices(customer_id, date_range)) com parâmetros tipados. Encerro com red team: testo com PyRIT ou garak antes de subir.
Red flag de junior: "uso um system prompt forte". O atacante também usa.
10. Como você escolhe modelo de embedding pra produção?
Resposta curta (30s): monto golden set de 100–500 pares (query, doc relevante) do meu domínio, mido Recall@k e MRR em 3–5 candidatos (text-embedding-3-large, voyage-3, bge-large, cohere-embed-v3, nomic-embed), e escolho pelo Pareto entre qualidade, custo e latência. Sem benchmark próprio, MTEB engana.
Resposta senior (2min): explico por que MTEB sozinho não basta: o leaderboard é otimizado pra média geral, não pro meu corpus. Em domínio jurídico/médico/financeiro brasileiro, modelos open-source bem ranqueados às vezes performam pior que text-embedding-3-small por causa de cobertura de português. Cito Matryoshka embeddings da OpenAI (posso usar 256 dim em vez de 3072 e cortar 90% do storage por <2% de qualidade). Discuto fine-tune do embedding com hard negatives — é uma das maiores melhorias práticas em RAG e ninguém faz. Encerro com observabilidade: log query, top-k docs e relevância julgada pelo usuário em produção pra ter dataset de tuning rolando.
Red flag de junior: "uso text-embedding-ada-002 porque é o mais usado". Esse modelo está deprecated. Sinal de que não acompanhou changelog.
10 perguntas de arquitetura
11. Desenhe um RAG end-to-end pra suporte ao cliente
Resposta curta (30s): ingestão → chunking (512 tokens com 50 de overlap, semântico em headers) → embedding (modelo escolhido por benchmark próprio) → vector store (pgvector se já tenho Postgres, Pinecone/Qdrant se preciso de escala) → retrieval híbrido (BM25 + denso, reciprocal rank fusion) → reranker cross-encoder no top 20 → LLM com prompt grounded → eval contínua com RAGAS.
Resposta senior (2min): desenho num quadro, anoto decisões: por que híbrido (BM25 pega entidade exata tipo SKU, denso pega paráfrase); por que reranker no top 20 não top 100 (custo); por que pgvector e não Pinecone (já tenho Postgres, latência menor sem network hop); por que prompt obriga <sources> ou retorna "não encontrei". Falo do que medir: faithfulness e context precision (RAGAS), thumbs up/down de usuário, taxa de deflexão de ticket pra atendente humano. Discuto failure modes que vi em produção: chunk pequeno demais perdendo contexto, query do usuário em português mal recuperando em base com chunks em inglês, prompt deixando o modelo inventar mesmo com <sources>.
Red flag de junior: desenhar só query → embedding → vector DB → LLM. Falta reranker, falta avaliação, falta híbrido, falta tratamento de fallback.
12. Como você avalia um sistema de RAG em produção?
Resposta curta (30s): três camadas: (1) retrieval: Recall@k, MRR, NDCG num golden set; (2) generation: faithfulness e answer relevance (RAGAS ou LLM-as-judge); (3) negócio: deflexão, CSAT, custo por interação. Sem golden set, é vibe.
Resposta senior (2min): descrevo o pipeline: golden set evolui (começa em 50, vira 500, depois 2000), curado de tickets reais; LLM-as-judge calibrado contra ~100 julgamentos humanos antes de virar métrica de produção; rubrica explícita pro juiz (não "isso é bom?", mas "essa resposta tem citação válida pro contexto fornecido? sim/não/parcial"). Cito frameworks: RAGAS, DeepEval, Promptfoo pra regression testing em CI. Discuto vieses do juiz (position bias, verbosity bias, self-enhancement bias) e como mitigar com swap de posição e modelo diferente do gerador. Encerro com observabilidade: Langfuse ou Phoenix pra trace + dataset rolando em CI.
Red flag de junior: "uso BLEU/ROUGE". Esses métricos morreram pra geração aberta. Quem cita BLEU em 2026 está em 2019.
13. Quando agente vs workflow determinístico?
Resposta curta (30s): agente quando o caminho é dinâmico e o número de estados é grande demais pra mapear. Workflow quando a árvore de decisão cabe num diagrama. 90% dos problemas são workflow disfarçado de agente.
Resposta senior (2min): cito o post da Anthropic "Building Effective Agents" e o consenso de mercado em 2026: workflows com checkpoints determinísticos ganham de agente "open-ended" em produção. Detalho padrões: prompt chaining (steps lineares), routing (classifier escolhe handler), parallelization (map-reduce sobre LLM), evaluator-optimizer (loop com critic), e por último orchestrator-workers (aí sim é agente). Critério prático: se posso enumerar os 5–8 caminhos possíveis, workflow. Se cada interação gera nova combinação de tools e o usuário decide o curso, agente. Cito o dado de 65% das falhas em AI enterprise tracarem de harness defects — context drift, schema misalignment, state degradation. Bound > free-roam.
Red flag de junior: "vou usar agente porque é mais poderoso". Mais poderoso é mais frágil.
14. Como você desenha tool schemas pra agente?
Resposta curta (30s): tools são API contracts. Nomes explícitos de domínio, parâmetros tipados com enum quando faz sentido, descrição que explica quando usar (não o quê), e erros estruturados que o modelo possa interpretar. Nunca dou tool execute_arbitrary_code.
Resposta senior (2min): mostro o padrão na prática: em vez de query_database(sql: str), dou list_invoices(customer_id: str, status: enum["paid", "pending", "overdue"], date_range: DateRange). O LLM erra muito menos. Descrição da tool foca em "quando chamar", porque o modelo já infere "o que faz" do schema. Erro de tool retorna {error: "code", recovery_hint: "..."} pra o agente tentar recuperar. Cito o MCP (Model Context Protocol) como padrão emergente pra separar implementação de tool da lógica do agente. Em segurança: least privilege (tool só vê dados do tenant atual), idempotency keys em ações que mutam, rate limit por agent session.
Red flag de junior: dar tool execute_python(code) ou read_file(path) sem sandbox.
15. Como você reduz custo de tokens num app com 1M queries/dia?
Resposta curta (30s): três frentes: (1) caching (prompt caching da Anthropic/OpenAI corta 90% do custo de contexto repetido, semantic cache pra queries parecidas); (2) routing (modelo pequeno responde 80% do tráfego, escala pra Sonnet/Opus só no que o classifier marcar como difícil); (3) compressão (resumir histórico, truncar contexto irrelevante, prompt encurtado por A/B test).
Resposta senior (2min): trago números: prompt caching reduz preço em ~90% no que está em cache (~10% no Anthropic, ~50% OpenAI) com TTL de 5min na Anthropic e 1h na OpenAI; semantic cache (Redis com embeddings) tem hit rate de 20–40% em domínio de atendimento; model tiering com Haiku 4.5 absorvendo 70% do tráfego e Sonnet 4.6 nos 30% complexos rebaixou meu custo em ~5x num caso real. Discuto monitoramento: cost-per-resolved-ticket, não cost-per-call — call barata que não resolve é cara. Cito que speculative decoding e small-LLM drafts (Llama 3 8B desenha pra Llama 3 70B aceitar) cortam latência em ~2x sem perder qualidade.
Red flag de junior: "uso GPT-4o-mini que é barato". E quando o problema for difícil?
16. Como você instrumenta observability num agente em produção?
Resposta curta (30s): trace distribuído de toda a sessão do agente, com span por LLM call, tool call, retry e tokens. Logs de input/output sanitizados (PII redacted). Métricas: latência por span, taxa de tool error, custo por session, taxa de loop. Ferramentas: Langfuse, LangSmith, Arize Phoenix, Braintrust.
Resposta senior (2min): descrevo o stack: OpenTelemetry como protocolo, Langfuse self-hosted como backend (LGPL), traces correlacionados com user_id e session_id, todo span carregando model, temperature, tokens_in/out, cost. Pra debugging em produção, mantenho replay completo da session por 30 dias — sem isso, agent failure é impossível de reproduzir. Métricas-chave: turn count distribution (loop detection), tool error rate por tool, ratio de "tool não usada" (sinal de schema ruim), tempo médio até done. Falo de evaluation contínua: amostro 1% das sessions pra LLM-as-judge offline, alimentando golden set. Cito Langfuse evals em produção e dataset versionado.
Red flag de junior: só log "input" e "output" do modelo. Sem span, sem custo, sem session id.
17. Como você desenha memória pra um agente?
Resposta curta (30s): quatro tipos: working memory (contexto da sessão), episodic (interações passadas, recuperadas por similaridade), semantic (fatos extraídos do usuário, armazenados como key-value), procedural (workflows que o agente aprende). Default pra produção: working + semantic explícita, episodic via RAG.
Resposta senior (2min): detalho a stack: working é o histórico truncado ou resumido (cap de turnos ou de tokens, summarization automática quando passa do limite); semantic é JSON estruturado ({"user.preferred_language": "pt-BR", "user.last_complaint_category": "billing"}) que viro key-value e injeto no system prompt; episodic é RAG sobre transcript histórico, recuperado quando a sessão referencia algo. Cito o paper MemGPT como referência conceitual e Letta como evolução prática. Discuto o problema real: memória explícita é frágil — extração errada vira contexto poluído, e poluição de contexto degrada agente mais rápido que falta de contexto. Critério de produção: memória opt-in, com confirmação pro usuário em ações irreversíveis.
Red flag de junior: "uso vector store pra tudo". Memória semântica é structured, não vector.
18. Latência: como você reduz time-to-first-token e time-to-last-token?
Resposta curta (30s): TTFT corta com streaming, prompt menor, prompt caching e modelo menor pra primeira resposta enquanto o grande processa em paralelo. TTLT corta com response shorter (instrução), structured output (modelo para no schema), e speculative decoding em self-hosted.
Resposta senior (2min): trago números de baseline: GPT-4o em região US-east, prompt de 4k tokens, TTFT ~800ms; com prompt caching cai pra ~300ms. Anthropic Claude Sonnet 4.6 em região Frankfurt, TTFT ~600ms com cache hit. Discuto técnicas avançadas: speculative decoding em vLLM aumenta TPS em ~2x sem perder qualidade; continuous batching no servidor mantém GPU ocupada (sem isso, GPU fica ociosa entre requests); para UX, streaming + skeleton + "respondendo..." dá percepção de latência muito menor que mesmo tempo absoluto sem feedback. Pra agentes, o multiplicador é número de turns — corto turns com tool design melhor (mais info por chamada), prompting mais direto e early stopping em quando atingido o objetivo.
Red flag de junior: "uso modelo mais rápido". E o resto?
19. Multi-agent: quando vale e quais os padrões?
Resposta curta (30s): vale quando há especialização real (papéis com prompts e tools distintos) ou paralelismo forte (vários workers em sub-tasks independentes). Padrão dominante: orchestrator + workers com escopo bem definido. Multi-agent solto, em rede plana, é hype.
Resposta senior (2min): cito o post recente da Anthropic sobre research multi-agent system — eles usam orchestrator + workers paralelos em research aberto, ganho de 90% sobre single-agent em benchmark próprio, mas com custo ~15x. Discuto quando vale o custo: research, code reasoning sobre repos grandes, análise comparativa. Quando não vale: customer support, agendamento, qualquer fluxo com SLA apertado. Padrões úteis: hand-off explícito (não "agente A grita pra agente B", mas "orchestrator recebe summary do worker e decide próximo passo"), evaluator-actor (um agente propõe, outro critica), debate (raro, mas útil em decisão de alto risco). Falo do failure mode clássico: agentes em loop conversando entre si, custo explodindo, e sem observability ninguém percebe até a fatura chegar.
Red flag de junior: "vou montar um sistema com 5 agentes especializados". Por quê? Mostra a evidência.
20. Segurança e PII em RAG/agentes: qual a arquitetura?
Resposta curta (30s): PII redaction antes da ingestão (não confio em modelo pra redactar), criptografia em repouso e em trânsito, separação por tenant no vector store, prompt do sistema sem PII, e logs com PII mascarada. Pra LGPD, pipeline de "esquecimento" deleta do índice e do log.
Resposta senior (2min): detalho o pipeline: ingestão passa por Presidio ou regex customizado por domínio antes do embedding (CPF, RG, telefone, email viram tokens <PII_*>); vector store tem namespace por tenant_id (pgvector com índice composto, Pinecone com namespace); retrieval valida tenant no filtro antes de retornar; prompt nunca interpola dado bruto sem template. Em agente, tool call carrega contexto do usuário como parâmetro explícito (get_orders(user_id=context.user_id)), nunca o LLM escolhe o user_id. Cito LGPD: artigo 18 dá direito à exclusão — então embedding store precisa de delete real, não soft delete. Em log/trace, mascaro antes de gravar (Langfuse tem hooks pra isso). Pra audit, mantenho hash do prompt em vez do prompt cru quando há PII.
Red flag de junior: "uso modelo da OpenAI mas não envio PII". Como você sabe que não envia? Você instrumentou?
10 perguntas comportamentais
21. Me conta uma vez que você reduziu hallucination num sistema em produção
Resposta curta (30s): descreva o sistema, a métrica (faithfulness ou taxa de erro reportada pelo usuário), o experimento (mudança de prompt, reranker, structured output) e o resultado em número. Se não tem número, não rodou em produção.
Resposta senior (2min): estrutura STAR aplicada: situação ("chatbot de suporte de uma fintech, ~5k queries/dia, hallucination reportada em ~8% segundo curadoria semanal"), tarefa ("reduzir hallucination sem perder cobertura"), ação ("instrumentei RAGAS com 500-question golden set, identifiquei que 70% das alucinações vinham de prompt deixando 'criatividade' pro modelo. Mudei pra structured output forçando campo sources no JSON, adicionei reranker no top 20 que melhorou context precision de 0.62 pra 0.84, e adicionei LLM-as-judge offline em 1% da amostra"), resultado ("hallucination reportada caiu pra 2.1%, CSAT subiu de 78 pra 86, custo aumentou 12% pelo reranker mas absorvido pela deflexão"). Encerro com o que aprendi: "o que matava não era o modelo, era o prompt deixar caminho".
Red flag de junior: "ajustei o prompt e melhorou". Sem número, sem método, sem causa raiz.
22. Conta uma vez em que você tomou uma decisão técnica e errou
Resposta curta (30s): decisão concreta + por que parecia certa na hora + qual sinal de produção provou que estava errada + o que mudou + o que aprendeu sobre como decidir melhor. Sem "errei mas no fundo deu certo" — entrevistador odeia.
Resposta senior (2min): caso real: "escolhi montar um agente multi-tool pra automatizar análise de documentos jurídicos em vez de workflow determinístico em 3 etapas. Pareceu certo porque o cliente queria 'extensibilidade'. Quebrou em produção: agente entrava em loop em PDFs grandes, custo por análise subiu de R$ 0.40 pra R$ 2.30, latência foi de 8s pra 45s. Refatorei pra workflow com 3 steps determinísticos + 1 step agêntico só na parte de raciocínio jurídico. Custo voltou pra R$ 0.55, latência pra 12s, e ganhei observability que o agente original não dava. Aprendi: 'extensibilidade' é desculpa pra sobre-engenharia. Workflow primeiro, agente quando o caminho realmente diverge".
Red flag de junior: "errei mas foi por causa do time/cliente/prazo". Ownership não terceiriza.
23. Como você se mantém atualizado num campo que muda toda semana?
Resposta curta (30s): três loops: leio papers (Arxiv Sanity, AI News do Swyx), acompanho changelog de 3–4 providers principais (Anthropic, OpenAI, Google, Meta), e construo. Construir é o que separa quem entende de quem leu thread no Twitter.
Resposta senior (2min): detalho minha rotina: Anthropic blog e OpenAI cookbook em RSS, HuggingFace daily papers filtrado por tag, Latent Space podcast no carro, e um projeto pessoal por trimestre testando o que aprendi. Cito a regra do "não acredito até rodar": GPT-4 vision saiu, esperei a empolgação passar, rodei em meu caso de uso (extração de tabela de PDF brasileiro) e descobri que ainda perdia pra layout-parser específico. Discuto curadoria: ignoro thread viral, vou direto na fonte (paper, release note, system card). Pra time, mantenho doc interno com "tendência X — testei em Y — concluí Z" que vira repertório compartilhado.
Red flag de junior: "sigo influencers de IA no Twitter". OK, mas o que você construiu?
24. Conta uma vez que você teve que explicar uma decisão técnica pra alguém não-técnico
Resposta curta (30s): público (CFO, jurídico, produto), decisão (X), o medo deles, a analogia que funcionou, o resultado (decisão aprovada ou ajustada). Foco em como você adaptou linguagem, não em "ensinei eles".
Resposta senior (2min): caso: "precisei convencer o jurídico de uma seguradora a aprovar uso de Claude pra triagem de sinistros. Medo deles era LGPD e 'AI Act europeu'. Em vez de explicar inference, mostrei o pipeline: dado entra mascarado por Presidio, vai por API com data residency US (apresentei o DPA da Anthropic), retorno tem campo confidence que aciona review humano sob threshold. Eles entenderam porque virou processo, não tecnologia. Saiu uma POC de 60 dias com 3 critérios de pass/fail definidos por eles. Passou nos 3". Discuto o princípio: jurídico quer responsabilidade rastreável, não inovação. Produto quer outcome, não método. Quanto antes eu falar a língua deles, antes o projeto sai.
Red flag de junior: "expliquei como funciona um LLM pra eles". Ninguém quer aula.
25. Como você prioriza entre melhorar evals, reduzir custo e adicionar feature?
Resposta curta (30s): depende da fase. Pré-produção: evals primeiro, sem isso não há sinal. Produção pequena: feature pra ganhar tração, custo otimizo depois. Produção em escala: custo e latência viram feature, evals continuam rolando em CI. Decisão por dado, não por gosto.
Resposta senior (2min): trago framework: olho o gargalo do produto, não o do modelo. Se o problema é "usuário não confia na resposta" — evals. Se é "queima de margem" — custo. Se é "adoção parada" — feature ou UX. Cito exemplo: num projeto, time queria adicionar 4 features novas; rodei análise de logs e 60% das queries eram em uma feature que tinha hallucination rate de 11%. Defendi: nada de feature até essa cair pra <3%, porque feature em cima de produto desconfiado não engaja. Saiu briga, ganhei com dado, viramos a chave em 6 semanas, retenção subiu 18%. Encerro: prioridade é decisão de produto, não de modelo. AI engineer que não conversa com PM/dados toma decisão errada com confiança.
Red flag de junior: "faço o que o PM mandar". OK, mas com dado ou sem?
26. Conta uma vez que você teve que dizer "não" a um stakeholder pedindo IA
Resposta curta (30s): caso concreto, motivo do "não" (custo desproporcional, risco regulatório, problema mal definido), alternativa que ofereci, resultado. Dizer "não" bem é sinal de senioridade. Dizer "sim" pra tudo é sinal de junior.
Resposta senior (2min): caso: "diretor de marketing pediu 'um agente que responda email de cliente automaticamente'. Disse não. Razão: volume era 200 emails/dia, 80% triviais, mas 5% eram cancelamento — e responder cancelamento errado é churn imediato. Custo de errar > custo de manter humano. Alternativa: build classificador (não LLM, modelo pequeno) que tagueia email em 4 buckets, RAG-assistido pra atendente humano com sugestão de resposta, log pra evals. Saiu com 4 sprints, atendente respondia 3x mais rápido, taxa de erro caiu, ninguém foi demitido. Marketing entendeu que IA boa não é a que substitui, é a que aumenta". Princípio: 'agente autônomo' é resposta tentadora e quase sempre errada em domínio com custo de erro alto.
Red flag de junior: "topei e fui descobrindo na implementação". Bem-vindo ao firefighting.
27. Como você lida com modelo que muda comportamento depois de um upgrade do provider?
Resposta curta (30s): regression test em CI rodando golden set sempre que o provider lança update. Pin de versão de modelo (não uso alias latest), gate de rollout, e plano B com modelo de outro provider mapeado. Sem regressão automática, você descobre que quebrou pelo cliente.
Resposta senior (2min): detalho a prática: uso claude-sonnet-4-6 ou gpt-4o-2024-08-06 pinned, nunca latest; quando provider anuncia novo modelo, rodo golden set offline antes de promover; se eval cair >3% em alguma métrica, investigo antes. Cito caso real (genérico, sem cliente): mudei pra GPT-4o-mini em uma feature, eval mostrou que faithfulness caiu de 0.91 pra 0.84 — fiquei no anterior até o problema cobrir, depois mudei. Discuto multi-provider: para tasks críticas, mantenho Anthropic e OpenAI ambos cobertos com mesmo prompt, troco com feature flag se um cair (SLA) ou ficar caro. Em failure mode interessante: prompt cache invalidado depois de deploy do provider gerou pico de custo num cliente — descobrimos por monitoramento de cost-per-query, não por usuário reclamando.
Red flag de junior: "uso o modelo mais novo porque é melhor". Melhor pra quem mediu?
28. Conta uma vez que você quebrou produção (com IA envolvida)
Resposta curta (30s): o que quebrou, como você detectou, MTTR, post-mortem (causa raiz, não sintoma) e o que mudou no processo pra não acontecer de novo. Sem culpar o modelo. Sem culpar o estagiário.
Resposta senior (2min): caso: "deploy de novo prompt entrou sexta-feira 17h (não fiz code freeze). Fim de semana, suporte recebeu 40 tickets reclamando que o bot estava 'agressivo'. Detectei domingo por alerta de spike em thumbs down (configurado pra alarmar em >2σ do baseline). Rollback do prompt em 12min. Causa raiz: testei o novo prompt num set de 50 casos balanceados, mas não rodei contra o subset 'reclamação de cobrança' que tinha tom diferente. Pós: golden set agora estratificado por intent, regression test bloqueia merge se qualquer subset cair >5%, e prompt change exige aprovação de 2 pessoas". Aprendizado: prompt change é mudança de produção como qualquer outra. CI/CD não opcional.
Red flag de junior: "nunca quebrei nada". Mentira ou nunca subiu nada.
29. Como você decide entre construir self-hosted vs API gerenciada?
Resposta curta (30s): API gerenciada por default. Self-hosted quando: (a) volume torna economicamente óbvio, (b) data residency/compliance exige, (c) latência precisa de inferência regional não coberta, ou (d) tarefa repetitiva onde modelo pequeno fine-tuned ganha do grande. "Quero controle" sem dado de uso não conta.
Resposta senior (2min): trago a matemática: API a $3/M tokens output × 50M tokens/dia = $150/dia = $4.5k/mês. Self-host Llama 70B em 2x H100 reserved = ~$8k/mês, mas com qualidade menor e ops próprio. Crossover honesto fica em 100M+ tokens/dia em domínio onde modelo open compete. Discuto compliance: dado de saúde no Brasil (ANS) ou bancário (Bacen) às vezes obriga inferência on-prem ou em nuvem nacional — aí self-host vira tabela. Cito experiência: a maioria das empresas que falam "queremos self-hosted por privacidade" descobrem em 2 semanas que ops de GPU é outro mundo. Pra time pequeno, recomendo Bedrock/Vertex como meio-termo (data residency + provider gerenciado).
Red flag de junior: "self-hosted é mais barato sempre". Não é. Conte ops.
30. Onde você quer estar daqui a 2 anos?
Resposta curta (30s): resposta honesta + alinhada com a vaga. Se você quer virar staff/principal e a vaga é IC senior, fala. Se você quer virar EM e a empresa não tem trilha, descobrir agora é melhor que depois.
Resposta senior (2min): evito clichê ("crescer com a empresa"). Trago algo específico do meu repertório: "Em 2 anos quero ser staff AI engineer com escopo de plataforma — desenhar o pipeline de evals, harness de agente, infra de RAG que outros times consomem como produto interno. Tô construindo isso hoje no [projeto X], onde sou o ponto único, e quero próximo passo onde escalo via plataforma, não via mãos. Se aqui o plano de produto encaixa com plataforma de IA, quero discutir. Se for muito IC puro de feature, é honesto saber agora". Princípio: entrevista é mão dupla. Eu também tô avaliando.
Red flag de junior: "quero aprender muito com o time". OK, mas e depois?
Bônus: 5 perguntas reversas pra filtrar empresa
Entrevistador termina perguntando "tem alguma pergunta?". A maioria responde "como é o time?" e perde. Aqui vão 5 perguntas que separam empresa séria de "vaga de AI engineer" que é prompt em Notion. Se a empresa não souber responder, você acabou de descobrir o nível de maturidade.
R1. Como vocês medem qualidade de output de LLM em produção hoje?
O que você quer ouvir: golden set, métricas concretas (faithfulness, helpfulness), LLM-as-judge calibrado contra humano, observability tool específica. Se ouvir "olhamos por amostragem" ou "o time de QA testa", entendeu — não tem evals.
R2. Qual é o caso de uso mais sucedido de IA na empresa, e como vocês mediram que ele deu certo?
O que você quer ouvir: caso concreto + métrica de negócio (deflexão, GMV, conversão) + custo absorvido. Se ouvir "implementamos chat com IA no site, parece estar engajando", o caso ainda é demo.
R3. Como vocês decidem entre build interno, API gerenciada e modelo open-source?
O que você quer ouvir: framework explícito, dado de uso considerado, conversa com finance e segurança. Se for "a gente usa OpenAI porque é o que sabemos", você vai brigar pra trazer escolha.
R4. Qual o budget mensal de tokens e como ele evoluiu nos últimos 6 meses?
O que você quer ouvir: número, evolução, e quem é dono da otimização. Se ouvir "não acompanhamos detalhadamente" ou recusa polida, ou é zero ou está fora de controle.
R5. Vocês têm pessoa dedicada a evals e observability de IA, ou divide entre os AI engineers?
O que você quer ouvir: clareza de papel. Pode ser distribuído (cada AI engineer dono dos evals do seu sistema, com infra compartilhada) ou centralizado (platform team). Se a resposta for vaga, é provável que ninguém faça.
O padrão por trás das 30 perguntas
Releia as 30 e o padrão aparece sozinho.
Junior responde com definição. Senior responde com decisão. Definição é "RAG é Retrieval-Augmented Generation". Decisão é "uso RAG aqui porque tenho dado dinâmico e custo de fine-tune não compensa com X queries/dia".
Junior cita ferramenta. Senior cita tradeoff. Ferramenta é "uso Pinecone". Tradeoff é "uso pgvector porque já tenho Postgres e a latência de network hop pra Pinecone não vale o ganho de scaling pro nosso volume atual".
Junior fala em modelo. Senior fala em sistema. Modelo é "Claude Sonnet 4.6 é bom". Sistema é "esse fluxo precisa de Sonnet 4.6 com prompt caching, retriever híbrido top 20 + reranker, e structured output validado, porque tradeoff de custo × latência × faithfulness fechou nessa configuração no eval".
Junior gosta de agente. Senior desconfia de agente. Agente é a resposta tentadora pra quase tudo, e quase sempre errada. Workflow primeiro, agente quando o caminho diverge de verdade.
A diferença em entrevista não é ter a resposta certa. É ter o raciocínio certo — e ele aparece quando você já bateu a cabeça em produção, viu custo subir do nada, debugou hallucination em quarta-feira 23h e mediu o impacto antes de chamar de "melhor".
Esse tipo de conversa — debate de tradeoff, número de produção, dor de eval, harness real — é o que rola toda semana na Beer and Code, a melhor comunidade de AI engineering em português, com grupo no WhatsApp aberto pra quem está construindo IA em produção. Se as 30 perguntas acima te lembraram de algo que você viveu ou tá vivendo, é o lugar pra trocar.
Próximo passo prático: pega 3 dessas perguntas onde sua resposta hoje é mais "definição" que "decisão". Vai atrás do dado de produção (ou do projeto pessoal mais próximo) que transforma definição em decisão. Aí você tá pronto pra entrevista séria — não a do recrutador, a do tech lead que vai ser seu colega.

{AI Engineer} — apaixonado por Laravel, arquitetura de software e construir produtos com impacto. Compartilho aqui tutoriais, descobertas e reflexões sobre o dia a dia de engenharia.
Você também pode gostar
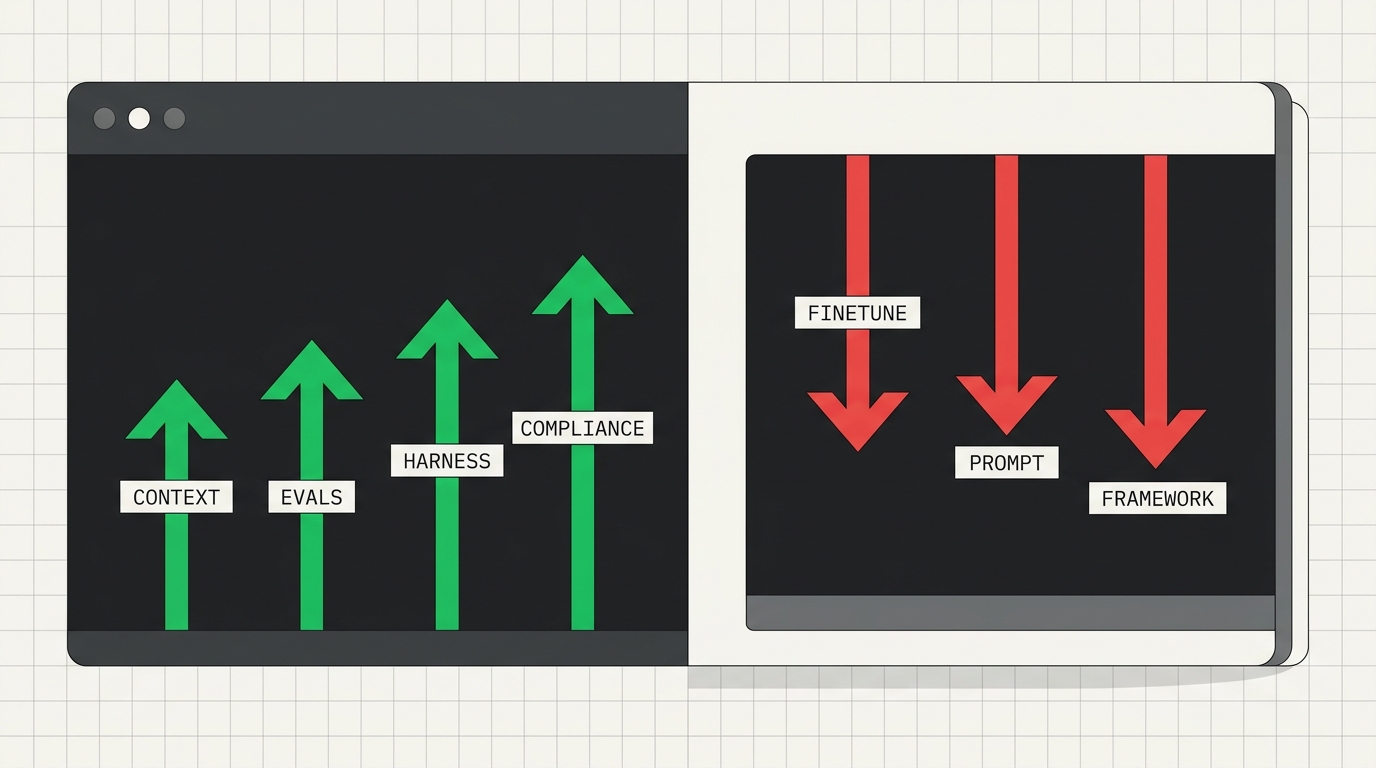
AI engineer no 2º semestre de 2026: o que o recrutador vai pedir
Li 200 vagas de AI engineer postadas em maio de 2026 e separei sinal de ruído: quatro skills que sobem (context engineering, evals, harness e compliance), três que perdem peso e um roteiro de 90 dias pra entrar na shortlist do segundo semestre.
Portfólio de AI Engineer: 5 projetos que abrem porta sem precisar de mestrado
Recrutador olha 11 segundos. Notebook de fine-tuning de Llama no Colab não convence ninguém. Cinco projetos pequenos que provam skill real de AI engineer e cabem em 1 a 3 fins de semana cada.
Glossário do AI Engineer 2026: 30 termos que todo engenheiro precisa saber (sem hype)
Dicionário de campo com 30 termos que aparecem em todo projeto sério de IA em 2026: núcleo, capacidades, padrões agênticos, recuperação, engenharia e operação. Cada termo em uma linha clara, com um exemplo concreto e zero hype. Mais mini-FAQ com 10 perguntas que economizam reunião.

AI Engineer no Brasil: as 6 senioridades que o mercado realmente paga (e o que cada uma entrega)
RH pede 5 anos em IA agêntica para um campo que não tem 5 anos. A escala real é outra. Mapa de 6 senioridades de AI Engineer no Brasil em 2026 com entregáveis por nível, faixa salarial e o critério de promoção que recrutador respeita.
