Cross-encoder reranker: o componente que mais eleva qualidade do seu agente por dólar
Você gastou três dias trocando seu agente de Sonnet para Opus. Gastou mais um migrando o prompt para a versão "premium". E continua recebendo resposta meia-boca em metade das perguntas.
Spoiler: o problema raramente é o LLM. É o que chega até ele.
Neste post você vai entender por que o cross-encoder reranker é provavelmente o tijolinho que mais melhora a qualidade do seu agente por dólar gasto. Vamos olhar o trade-off latência x precisão, em qual cenário rerankar 50, 100 ou 200 documentos, e por que esse componente devolve mais ROI que trocar de modelo.
TL;DR
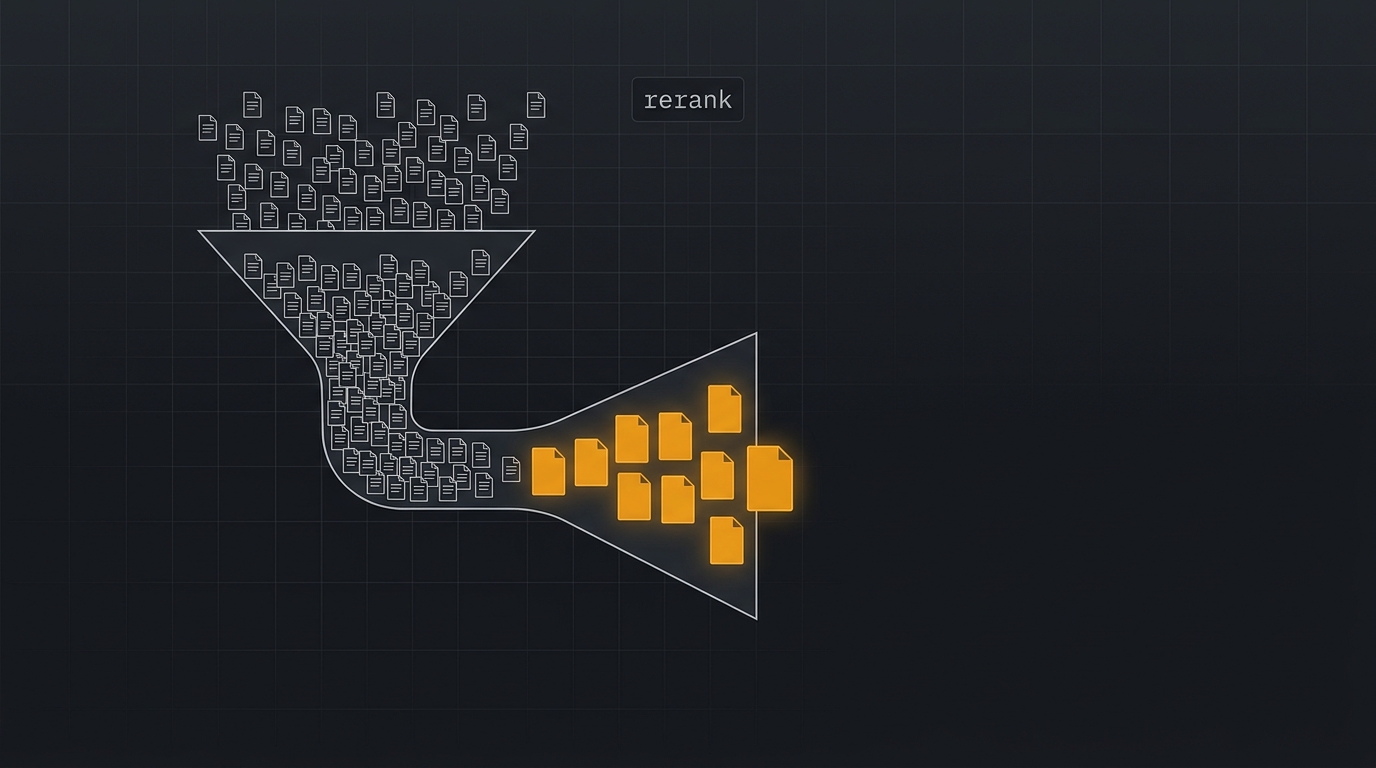
- O que é: modelo que reordena os candidatos do retrieval colocando os realmente relevantes no topo, antes de mandar para o LLM.
- Stack: Cohere Rerank 3.5, Pinecone Rerank, Voyage Rerank, Jina Reranker v3 ou BGE Reranker self-hosted.
- Custo/Acesso: API paga (centavos por busca) ou modelo open-weight rodando em GPU própria.
- Repositório útil: docs Cohere Rerank V2.
O contexto: por que reranker importa antes de trocar de LLM
Pipeline RAG ingênuo é assim: usuário pergunta, embedding da query, busca no vector DB, top-5 documentos, joga tudo no prompt do LLM, responde.
Funciona em demo. Quebra em produção.
Quebra porque o vector search está procurando o documento "parecido" com a query, não o documento que responde a query. São coisas diferentes. E quando o seu corpus passa de 10 mil documentos, a diferença entre "parecido" e "responde" começa a custar caro.
A correção é arquitetural: você troca um estágio só (busca para LLM) por dois estágios (busca, depois reranker, depois LLM). E o ganho é desproporcional. Pesquisa da Ailog mostra +40% em accuracy de RAG ao adicionar cross-encoder. A ZeroEntropy reporta +28% NDCG@10 sobre baseline. Databricks já mostrou ganhos de até 48% em qualidade de retrieval com reranking.
Não existe truque de prompt que entregue 40% de melhoria. Trocar de modelo entrega menos que isso, na maioria dos casos. E custa muito mais.
Bi-encoder vs cross-encoder: a diferença é arquitetural, não de marketing
Para entender por que reranker é tão eficaz, precisa entender o que o bi-encoder (o motor do seu vector DB) faz de errado.
Bi-encoder é o que gera embeddings. Ele lê seu documento uma vez, no momento da indexação, e comprime todo o significado em um vetor de 1024 ou 1536 dimensões. Isso permite busca rápida: um único produto vetorial e você compara contra milhões de documentos. Mas tem um problema fundamental: como a Pinecone explica bem, bi-encoders precisam comprimir todos os significados possíveis de um documento em um único vetor, o que significa perda de informação.
Pior: o documento foi codificado antes da query existir. O modelo não sabia o que você ia perguntar. Então ele tentou ser bom em geral, e acabou sendo medíocre em específico.
Cross-encoder vira a mesa. Ele recebe query e documento juntos no transformer, faz uma inferência completa para cada par, e devolve um score de relevância. Não tem compressão. Não tem perda. O modelo enxerga a query e o documento ao mesmo tempo e julga: isso responde aquilo? Sim, com peso 0.94. Não, com peso 0.12.
O custo desse luxo: você não pode rodar cross-encoder em milhões de documentos. Cada par é uma inferência de transformer. Em 40 milhões de docs, Pinecone calculou, você esperaria mais de 50 horas. Bi-encoder com vector search resolve isso em menos de 100ms.
A solução prática é a obviamente óbvia: bi-encoder faz a triagem grossa (top-100), cross-encoder faz o julgamento fino (top-10). Cada um na função em que é melhor.
Quando rerankar 50 vs. 200 documentos
Aqui mora a engenharia. O top_k do retrieval, quantos candidatos você manda para o reranker, define o trade-off entre qualidade e latência. Não tem número universal. Tem regra de bolso.
Chat e agentes interativos (rerankar 50 docs): o usuário está esperando resposta. Cada 100ms a mais ele sente. Cross-encoder em 50 documentos roda em ~100-150ms na maioria dos provedores. É o sweet spot quando latência percebida importa.
RAG enterprise, busca documental, pesquisa jurídica (rerankar 100-200 docs): o usuário aceita esperar 1-2 segundos por uma resposta correta. Aqui o ganho de recall ao mandar mais candidatos compensa o custo. Jina Reranker v3 processa 100 docs em ~188ms entregando 81% de Hit@1. Nemotron faz o mesmo em 243ms com 83%.
Pipelines batch e enriquecimento offline (rerankar 200-1000 docs): sem usuário esperando, vale rerankar tudo que faz sentido. O limite do Cohere Rerank é 1000 documentos por chamada.
A heurística mais útil que a ZeroEntropy publicou é a regra dos 2%: vai aumentando seu top_k em incrementos de 25 e medindo nDCG. Quando o ganho cair abaixo de 2% por incremento, parou. Acima disso é desperdício de latência e dinheiro.
Outra coisa que ninguém te conta: o reranker não conserta retrieval ruim. Se seu top-200 não tem a resposta, nenhum reranker do mundo vai inventá-la. Reranker pole o que existe. Se a resposta certa não está nos candidatos, troque a estratégia de embedding ou adicione busca lexical (BM25) em paralelo, não jogue mais documentos no reranker.
Mão na massa: integrando Cohere Rerank em uma chamada
Vamos ao código. Pega o cenário típico: você tem retrieval com Pinecone/Qdrant/pgvector devolvendo 100 candidatos, e quer reduzir para 10 antes do LLM.
Passo 1: cliente Cohere
import cohere
co = cohere.ClientV2(api_key="seu-token")
Passo 2: retrieval normal devolvendo top-100
candidatos = vector_db.search(query, top_k=100)
documentos = [c.text for c in candidatos]
Passo 3: rerank para top-10
resposta = co.rerank(
model="rerank-v3.5",
query=query,
documents=documentos,
top_n=10,
)
top_10 = [documentos[r.index] for r in resposta.results]
Pronto. Três linhas. O resposta.results vem ordenado por relevance_score de 0 a 1, e cada item tem o index original, útil se você precisa carregar metadados que não mandou para a API.
Passo 4: contexto enxuto para o LLM
contexto = "\n\n".join(top_10)
prompt = f"Contexto:\n{contexto}\n\nPergunta: {query}"
resposta_llm = anthropic.messages.create(
model="claude-sonnet-4-6",
messages=[{"role": "user", "content": prompt}],
)
Para Laravel, o padrão é o mesmo via Prism ou Guzzle direto na API REST do Cohere. Endpoint https://api.cohere.com/v2/rerank, payload com model, query, documents, top_n. Sem dependência exótica.
Erros comuns
- Estourar 4096 tokens por documento: o
max_tokens_per_docdefault trunca silenciosamente. Se seu chunk passa disso, parta antes ou suba o limite explicitamente. - Rerankar tudo no DB: alguém vai tentar mandar 5 mil candidatos achando que é "mais qualidade". É mais latência e mais custo, sem ganho. Respeite a regra dos 2%.
- Esquecer de logar o
relevance_score: sem isso você não sabe se vale a pena ajustar threshold, e perde a chance de detectar drift no corpus.
Tutorial te mostra o caminho — no Clã você constrói junto. Aula ao vivo toda semana, projetos reais de Engenharia de IA, ao lado de quem já está em produção.
Entrar no ClãPor que esse é o melhor ROI antes de chamar um LLM grande
Faz a conta com calma.
Trocar Sonnet por Opus em um agente que processa 100k requests/mês quase sempre dobra o custo do LLM. O ganho médio em qualidade, fora benchmarks específicos, fica na faixa de 5-15% em tarefas reais. Não é nada, mas é muito menos do que o que reranker entrega.
Adicionar Cohere Rerank ao mesmo pipeline custa centavos por busca. ZeroEntropy mostrou em um caso real que filtrar 75 candidatos para 20 antes do GPT-4o gerou 72% de redução de custo total mantendo 95% da accuracy. Você paga menos de LLM porque manda menos contexto, e responde melhor porque o contexto que vai é o certo.
A ordem de prioridade quando seu agente está medíocre é praticamente sempre essa:
- Melhorar chunking e estratégia de embedding.
- Adicionar reranker entre retrieval e LLM.
- Ajustar prompt e few-shots.
- Só então considerar trocar para um LLM mais caro.
Quem pula direto para o passo 4 está pagando a Anthropic e a OpenAI para resolver problema de retrieval. Não funciona, e quando funciona é caro demais.
Limitações e pontos de atenção
Reranker não é grátis e não é mágica. As armadilhas reais:
- Latência somada: mesmo o reranker mais rápido adiciona 100-300ms ao pipeline. Em agente conversacional pode ser percebido. Mede antes, decide depois.
- Privacidade: API de reranker recebe os documentos no payload. Se seu corpus tem dado sensível (cliente, médico, financeiro), avalia self-hosted (BGE, Jina, ZeroEntropy zerank-1-small) antes de assinar contrato com vendor.
- Custo escala com documentos x queries: Cohere conta como search unit cada query com até 100 docs. Se você roda muito tráfego com
top_kalto, faça a conta antes do mês fechar. - Reranker bom em inglês não é reranker bom em PT-BR: o Rerank 3.5 e o BGE-reranker-v2-m3 são multilíngues sólidos. Modelos só em inglês degradam em português, especialmente em domínio técnico ou jurídico nacional. Testa antes.
- Não conserta retrieval podre: se a resposta não está no top-200 do retrieval, reranker não inventa. Investe primeiro em embedding e chunking decentes.
Sem essas observações você vai entrar em produção, ver a latência, ver a fatura, e culpar o reranker. A culpa é da arquitetura.
Quer construir agentes que aguentam produção?
Reranker é um exemplo do tipo de decisão que separa "agente de demo" de "agente em produção". A maioria dos devs que estão entrando em IA aplicada nunca ouviu falar de cross-encoder, monta RAG ingênuo, e acha que o problema é o modelo.
A gente trata exatamente esse tipo de assunto, engenharia de IA aplicada de verdade, com Laravel e PHP, dentro do Clã Beer & Code. Se quer evoluir nessa direção, entra na nossa newsletter e acompanha os próximos posts práticos.
FAQ rápido
Posso usar reranker 100% open-source self-hosted?
Sim. BGE Reranker v2-m3 é o padrão atual: multilíngue, ~568M parâmetros, roda em GPU pequena. Para latência menor olhe os modelos pequenos da família Jina ou o zerank-1-small da ZeroEntropy. A escolha entre API paga e self-host vira conta de servidor vs assinatura.
Funciona bem em português? Funciona, desde que você escolha um modelo multilíngue. Cohere Rerank 3.5 e BGE-reranker-v2-m3 cobrem PT-BR de forma sólida. Modelos só em inglês degradam, especialmente em jurídico, médico e técnico nacional. Sempre rode uma avaliação no seu corpus antes de fechar a escolha.
Quando NÃO usar reranker? Em três cenários: (1) seu corpus é muito pequeno, tipo 100-500 documentos, e vector search puro já resolve; (2) latência é crítica abaixo de 200ms ponta a ponta, e não dá folga para o reranker; (3) você ainda não consertou chunking e embedding, e reranker em retrieval ruim é gasto inútil.
Reranker substitui usar um embedding melhor? Não. São camadas diferentes. Embedding bom melhora o recall (a resposta certa entrar no top-100). Reranker melhora a precisão (a resposta certa virar top-1). Você precisa dos dois. Trocar embedding ruim por embedding bom é etapa zero. Reranker vem em cima.
Conclusão
Cross-encoder reranker é, hoje, o componente que mais eleva qualidade de agente por dólar gasto. Não é hype, não é truque novo: é arquitetura clássica de IR aplicada a RAG. A diferença entre um agente que responde bobagem e um agente que responde certo geralmente está nesse passo intermediário entre busca e LLM.
O próximo salto dessa parte da stack são os late-interaction rerankers estilo ColBERT e os listwise rerankers com LLMs pequenos avaliando todo o ranking de uma vez. Vão chegar ao mainstream nos próximos meses. Mas antes de correr atrás do brilho novo, garanta que sua pipeline já tem o cross-encoder no lugar certo. É de longe o investimento de melhor retorno disponível agora.

{AI Engineer} — apaixonado por Laravel, arquitetura de software e construir produtos com impacto. Compartilho aqui tutoriais, descobertas e reflexões sobre o dia a dia de engenharia.
Conteúdo é o que não falta. Falta quem desembaralhe: o que importa agora é como implementar do jeito certo. No Clã você tem isso ao vivo, toda semana, com quem já filtrou o ruído.
Entrar no Clã