Busca híbrida: a receita BM25 + vetor + RRF que resolve SKU, part-number e semântica
Sua busca de produto encontra "RX-7000" quando o cliente digita "RX-5000". Não porque o catálogo está errado. Porque o embedding acha que os dois são quase a mesma coisa.
Quando você empurra um catálogo inteiro para um modelo de embedding, "RX-7000" e "RX-5000" caem a milímetros de distância no espaço vetorial. Visualmente, são parecidos. Semanticamente, o modelo nem entende que aquilo é um identificador. Ele lê "RX, número, número, número" e mapeia para um vizinho qualquer.
Aí você troca para BM25 puro, achando que volta para o velho e bom full-text. E descobre que o cliente que digitou "tênis para corrida na chuva" continua sem encontrar o "calçado impermeável esportivo" que está no estoque.
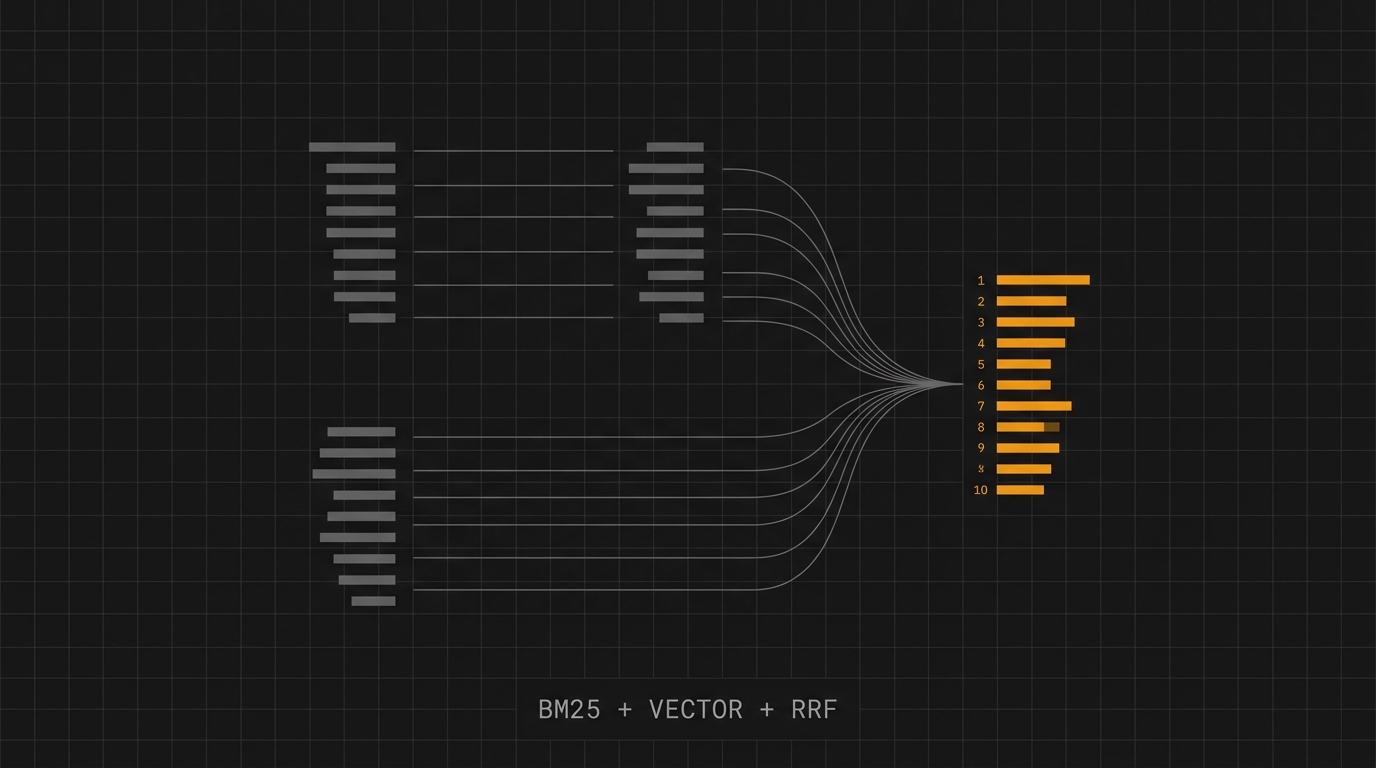
A resposta não é escolher entre os dois. É rodar os dois em paralelo e fundir os resultados com Reciprocal Rank Fusion. Neste post você vai entender por que essa receita funciona, ver a fórmula que sustenta ela e implementar um pipeline híbrido completo em Elasticsearch para um catálogo de produto.
TL;DR
- O que é: pipeline de busca que combina BM25 (lexical) + busca vetorial (semântica) e funde os rankings com Reciprocal Rank Fusion (RRF).
- Stack/Modelos: Elasticsearch 8.14+ ou OpenSearch 2.19+, qualquer modelo de embedding (OpenAI
text-embedding-3-small, Cohere, BGE, etc.), opcionalmente um reranker no topo. - Custo/Acesso: funciona na infra que você já tem. Elasticsearch e OpenSearch já trazem o RRF retriever nativo. Custo extra é o índice vetorial + chamada para gerar embedding.
- Repositório/Link útil: RRF retriever no Elasticsearch e RRF no OpenSearch Neural Search.
O contexto: por que embedding sozinho não resolve catálogo
Embedding é ótimo para entender intenção. "Tênis confortável para correr longa distância" cai perto de "calçado de corrida com amortecimento". Isso é puro suco de busca semântica e seria impossível só com BM25 sem um dicionário gigante de sinônimos.
O problema é que o mesmo modelo que entende intenção é péssimo para identificadores discretos.
SKU, part-number, código de modelo, ISBN, EAN, MPN. Tudo isso é uma string que o tokenizador BPE quebra em pedaços sem sentido semântico. "RX-7000" vira algo como ["RX", "-", "70", "00"]. "RX-5000" vira ["RX", "-", "50", "00"]. Os vetores resultantes são vizinhos imediatos no espaço de embedding. Para o modelo, você está pedindo "uma coisa que se parece com RX-algum-número".
E aí o cliente que veio buscar a peça certa para a máquina dele recebe a peça errada. Em e-commerce industrial, isso não é mau ranking. É devolução, ticket de suporte e cliente queimado.
BM25 não tem esse problema. Okapi BM25 trata cada token como discreto. "RX-7000" só casa com documentos que contém literalmente "RX-7000". Identificador é exatamente onde BM25 brilha.
Por que BM25 puro também não basta
Inverte o caso. O cliente digita "tênis para corrida na chuva". O produto no catálogo é descrito como "calçado esportivo impermeável de alta performance". Zero token em comum.
BM25 é exact match com peso. Sem token compartilhado, score zero. O produto fica fora do top-10, fora do top-100, e o cliente sai do site achando que você não tem o que ele quer. Você tinha. Só não conseguiu mostrar.
Resolver isso com sinônimos manuais é trabalho de Sísifo. Toda vez que entra produto novo, alguém precisa atualizar o dicionário. E sinônimos não capturam intenção composta — "presente para mãe que adora cozinhar" não é uma palavra. É um conceito.
Embedding resolve isso de olho fechado. O vetor de "tênis para corrida na chuva" cai perto do vetor de "calçado impermeável esportivo" porque o modelo aprendeu que esses contextos compartilham significado. É exatamente para isso que busca semântica existe.
Resumindo o impasse:
- BM25 acerta SKU, part-number, nome próprio, código. Erra intenção e sinônimo.
- Vetor acerta intenção, sinônimo, conceito. Erra identificador discreto.
A receita certa é não escolher.
Reciprocal Rank Fusion: a fórmula que cala a guerra de scores
Quando você tenta combinar BM25 e vetor manualmente, esbarra num problema chato: os scores vivem em escalas completamente diferentes. BM25 cospe um número que depende de TF-IDF, comprimento do documento e parâmetros do índice. Cosine similarity vive em [-1, 1]. Não dá para somar.
Você pode normalizar (min-max, z-score), aplicar pesos, calibrar por query type. Tudo isso funciona. Tudo isso exige tuning. E tuning quebra quando o catálogo muda.
Cormack, Clarke e Buettcher publicaram em 2009 uma alternativa que ignora score completamente e olha só para a posição (rank) de cada documento em cada lista. A fórmula é uma linha:
score(d) = Σ 1 / (k + rank_i(d))
i
Onde rank_i(d) é a posição do documento d na lista do retriever i, e k é uma constante de amortecimento.
Lê assim: "para cada lista de resultado, pega o inverso do rank do documento mais um deslocamento k. Soma tudo." Documento que aparece no topo de várias listas vence. Documento que aparece longe em todas perde. E se um retriever cuspiu um outlier no topo, o k segura o impacto.
Os autores escreveram literalmente no paper: "The constant k mitigates the impact of high rankings by outlier systems." Eles escolheram k=60 por estudo piloto e mostraram que o ótimo é uma planície — qualquer k entre 20 e 100 praticamente não move o MAP. É por isso que Elasticsearch e OpenSearch usam 60 como default e ninguém perde sono ajustando isso.
Três coisas que isso resolve de graça:
- Sem normalização de score. Não importa que escala cada retriever usa.
- Sem peso a calibrar. O método é simétrico. Todos os retrievers têm voz.
- Robusto a outlier. O
kno denominador faz o documento de rank=1 valer só um pouco mais que o de rank=2. Sem outlier dominando.
A discussão acadêmica continua — um estudo recente do OpenSearch mostrou que RRF entrega NDCG@10 em média 3,86% abaixo de hybrid score-based em seis datasets, mas com latência ~1,6% melhor e zero tuning. Em produção, "zero tuning" costuma ganhar fácil.
Pré-requisitos e ferramentas
Para o passo a passo:
- [ ] Cluster Elasticsearch 8.14+ (RRF retriever ficou GA na 8.14) ou OpenSearch 2.19+.
- [ ] Modelo de embedding rodando (OpenAI, Cohere, Voyage, BGE local via llama.cpp, tanto faz).
- [ ] Catálogo com pelo menos
sku,name,descriptione um campoembedding(dense_vectorno Elastic). - [ ] Ideia clara da dimensão do seu embedding (
text-embedding-3-small= 1536,bge-small-en= 384).
Tutorial te mostra o caminho — no Clã você constrói junto. Aula ao vivo toda semana, projetos reais de Engenharia de IA, ao lado de quem já está em produção.
Entrar no ClãMão na massa: pipeline híbrido em Elasticsearch
Vou usar Elasticsearch porque o RRF retriever oficial é o exemplo mais limpo. A ideia é idêntica em OpenSearch (com hybrid query + RRF processor) e replicável em Qdrant, Weaviate e Milvus.
Passo 1: mapping do índice
PUT catalogo
{
"mappings": {
"properties": {
"sku": { "type": "keyword" },
"part_number": { "type": "keyword" },
"name": { "type": "text", "analyzer": "portuguese" },
"description": { "type": "text", "analyzer": "portuguese" },
"embedding": {
"type": "dense_vector",
"dims": 1536,
"index": true,
"similarity": "cosine"
}
}
}
}
Detalhe que muita gente esquece: SKU e part_number como keyword, não text. Você quer match exato e quer que apareça em term query, não tokenizado.
Passo 2: ingestão com embedding
Para cada produto, gera o embedding antes do indexar. Em PHP/Laravel, com Prism ou openai-php:
$produto = Produto::find($id);
$embedding = OpenAI::embeddings()->create([
'model' => 'text-embedding-3-small',
'input' => "{$produto->name}\n\n{$produto->description}",
])->embeddings[0]->embedding;
Elasticsearch::index([
'index' => 'catalogo',
'id' => $produto->id,
'body' => [
'sku' => $produto->sku,
'part_number' => $produto->part_number,
'name' => $produto->name,
'description' => $produto->description,
'embedding' => $embedding,
],
]);
Concatene name + description no input do embedding. SKU e part_number ficam de fora — eles vão para o BM25 puro fazer o trabalho deles.
Passo 3: query híbrida com RRF retriever
Esse é o coração. Uma única chamada, dois retrievers em paralelo, RRF fundindo:
POST catalogo/_search
{
"retriever": {
"rrf": {
"retrievers": [
{
"standard": {
"query": {
"multi_match": {
"query": "tênis para corrida na chuva RX-7000",
"fields": ["name^2", "description", "sku^5", "part_number^5"]
}
}
}
},
{
"knn": {
"field": "embedding",
"query_vector": [],
"k": 50,
"num_candidates": 200
}
}
],
"rank_window_size": 50,
"rank_constant": 60
}
},
"size": 10
}
O query_vector do knn é o array de 1536 floats gerado pelo embedding da query do usuário (cache esse embedding por 5 minutos para queries repetidas).
O que está acontecendo:
- O
standardretriever roda BM25 com boost agressivo emskuepart_number. Se a query contém um identificador, ele pula para o topo daquele lado. - O
knnretriever roda busca vetorial pura no campoembedding. Se a query é semântica, ele acha o produto certo mesmo sem token em comum. - O bloco
rrffunde as duas listas. Cada retriever entrega top-50 (rank_window_size), e o RRF aplica1 / (60 + rank)em cada documento de cada lista, soma e devolve top-10.
Se a query é "RX-7000 sem juros 12x", o BM25 vai retornar o produto certo no rank 1 e o vetor vai retornar uma coisa qualquer no top-50. Resultado: o produto certo ganha o RRF, porque rank 1 em BM25 + rank ~30 em vetor é melhor que rank 30+ em ambos.
Se a query é "calçado para corrida na chuva", BM25 talvez nem retorne o produto. O vetor retorna no rank 2. Resultado: o produto certo ganha mesmo sem o BM25 ajudar, porque o rank no vetor é forte.
Passo 4: erros comuns e como sair
Score esquisito ou tudo zerado. Provavelmente você está em uma versão antiga do Elasticsearch sem RRF retriever (pré 8.14). Atualiza ou usa a sintaxe via sub_searches + rank (deprecada, mas funciona).
Latência alta. O num_candidates no kNN é o vilão mais comum. 200 está OK até ~1M de docs. Acima disso, considere quantization (int8_hnsw no Elastic 8.13+) ou aumentar shards.
SKU não aparece quando o cliente digita só o número. Você esqueceu de manter SKU como keyword com boost alto no multi_match. Sem o ^5 no sku, ele compete em pé de igualdade com os outros campos e perde.
Embedding cospe vizinhos errados em SKU numérico. Era esperado — é exatamente por isso que você está fazendo busca híbrida. O BM25 vai cobrir esse buraco. Não tente "consertar" o embedding com prompt na frente do SKU. Não funciona.
Aplicação real: catálogo de produto industrial
Onde isso brilha mais é em catálogo onde o cliente mistura intenção e identificador na mesma query. Caso clássico de B2B.
Exemplo: distribuidor de peça automotiva. Cliente busca "filtro de óleo para Hilux 2018". A query tem três partes:
- Identificador implícito ("Hilux 2018") que precisa casar exato com a tabela de aplicação.
- Categoria semântica ("filtro de óleo") que precisa entender variações ("filtro lubrificação", "elemento filtrante de óleo").
- Modelo do veículo que pode ter código interno ("LN165", "GUN125") que o cliente não sabe.
BM25 puro cospe qualquer produto que tenha "filtro" e "Hilux" — mistura filtro de ar, de combustível, de cabine. Ranking caótico.
Vetor puro entende que é filtro de lubrificação, mas pode trazer filtros de Hilux 2015 e 2020 misturados, porque "2018" é só mais um token sem peso especial.
Híbrido com RRF: o filtro de óleo certo da Hilux 2018 aparece no top-3 das duas listas — semanticamente coerente (vetor) e com tokens exatos (BM25). RRF coloca no rank 1.
A diferença prática em catálogo grande: cai a taxa de "não encontrei" e sobe o CTR no top-3. É o tipo de melhoria que aparece direto no funil de conversão.
Limitações e pontos de atenção
Hybrid não é varinha mágica. Onde ele falha ou exige cuidado:
- Custo de embedding. Cada produto novo e cada query precisam ser vetorizados. Em catálogo de 1M+ SKUs com atualizações frequentes, isso vira linha de custo relevante. Cache agressivo de query embedding ajuda muito.
- Latência de busca vetorial. kNN exato é caro. Use HNSW (default no Elastic) e tune
num_candidatespor carga. Acima de 5M docs, considere quantization int8 ou int4. - Reranking ainda é melhor para top-K. RRF entrega um top-10 sólido. Se você precisa de top-3 cirúrgico, jogue um reranker cross-encoder (Cohere Rerank, BGE Reranker, Voyage Rerank) sobre os top-50 do RRF. Custo extra é uma chamada e ~50ms.
- Drift do modelo de embedding. Se você troca o modelo (de
text-embedding-ada-002paratext-embedding-3-small, por exemplo), tem que reindexar tudo. Versione o nome do modelo nos metadados do índice para não confundir embeddings de gerações diferentes. - RRF é cego para a confiança do retriever. Se um dos retrievers está com performance baixa naquela query, RRF não sabe — ele só conta rank. Para casos críticos, Elastic permite pesos no RRF (weighted RRF), mas você volta ao mundo do tuning.
Newsletter Beer & Code
Cada semana eu mando um e-mail curto com casos de IA aplicada que valem a pena para quem constrói produto: arquitetura de RAG, busca, agentes em produção, pipelines de avaliação. Sem hype. Assina aqui.
Se você quer ver o pipeline híbrido completo (com Laravel, Elasticsearch e geração de embedding via OpenAI) rodando em projeto real, entra no Clã Beer & Code — tem um módulo dedicado a busca, RAG e embeddings com código rodando.
FAQ rápido
Por que não usar só hybrid score-based (combinação linear) ao invés de RRF? Funciona, mas exige normalização de score e calibração de pesos por query type. O paper original do Cormack mostrou que RRF, sem nenhum tuning, bate a maioria das fusões score-based em benchmarks de TREC. E em produção, manutenção zero vence.
Posso fazer híbrido em Postgres com pgvector ao invés de Elasticsearch?
Pode. Roda uma query com tsvector (full-text) e outra com <=> (pgvector). Pega top-N de cada, faz RRF na aplicação. Funciona perfeitamente em catálogos abaixo de 1M SKUs e tem a vantagem de manter tudo no Postgres. Acima disso, Elastic ou OpenSearch escalam melhor.
RRF substitui reranker? Não. RRF é fusão de listas — combina retrievers. Reranker é reordenação de top-K com modelo cross-encoder mais pesado. Stack completa de busca de produção tem retrievers paralelos, depois RRF, depois reranker. Cada camada faz uma coisa.
E quando o usuário busca só por SKU exato? RRF ainda funciona — o BM25 vai retornar o SKU no rank 1 e o vetor vai retornar lixo no top-50. A soma do RRF coloca o SKU certo em primeiro. Se você quer ainda mais segurança, detecta padrão de SKU na query (regex) e rebaixa o peso do retriever vetorial só naquele caso.
Conclusão
Embedding sozinho confunde "RX-7000" com "RX-5000". BM25 sozinho perde "calçado impermeável" quando o cliente digita "tênis para chuva". Os dois métodos juntos, fundidos por uma fórmula de uma linha publicada em 2009, resolvem o problema sem virar projeto de tuning de 6 meses.
A próxima fronteira não é trocar embedding ou aumentar dimensão. É construir esse pipeline híbrido bem, observar onde ele falha (queries que ninguém previu), e adicionar reranking só onde precisa.
Se você quer ir mais fundo em RAG e busca para produto, veja como a gente fala sobre embeddings em outro post — é o tijolo que sustenta tudo isso.

{AI Engineer} — apaixonado por Laravel, arquitetura de software e construir produtos com impacto. Compartilho aqui tutoriais, descobertas e reflexões sobre o dia a dia de engenharia.
Conteúdo é o que não falta. Falta quem desembaralhe: o que importa agora é como implementar do jeito certo. No Clã você tem isso ao vivo, toda semana, com quem já filtrou o ruído.
Entrar no Clã