No RAG clássico, a busca acontece sempre. O usuário pergunta, você dispara um embedding, recupera os top-k documentos e injeta tudo no prompt — antes mesmo de saber se aquela pergunta precisava de busca. Funciona. Até a pergunta ficar difícil.
Agentic RAG inverte a ordem do raciocínio. Em vez de buscar e depois pensar, o agente pensa primeiro: essa pergunta precisa de contexto externo? Se precisa, o que exatamente eu busco? E quando o resultado volta fraco — eu reformulo e busco de novo, ou já tenho o suficiente para responder?
Neste post você vai entender o que muda quando a recuperação vira uma tool na mão do agente, ver o padrão de código que implementa isso, e — mais importante — saber quando esse poder todo vale o custo. Porque ele tem um custo, e ele é alto.
TL;DR
- O que é: arquitetura de RAG onde o agente decide se busca, o que busca e quantas vezes itera, tratando a recuperação como uma ferramenta (tool call) em vez de um passo fixo do pipeline.
- Stack/Modelos: qualquer LLM com tool calling (Claude, GPT, Gemini) + um retriever (vector DB) + um orquestrador de loop como LangGraph ou um agente próprio.
- Custo/Acesso: o conceito é gratuito; a conta é de inferência. Estudos apontam ~3.3× mais tokens de entrada que um RAG bem ajustado.
- Quando usar: perguntas multi-hop, ambíguas ou compostas. Para FAQ factual de uma frase, é desperdício puro.
O contexto — por que o RAG clássico trava
O RAG clássico — o que a literatura chama de naive RAG — é um pipeline fixo: uma query, uma busca, uma geração. Como descrevem os autores de um estudo experimental recente no arXiv, é "a instância mais simples do paradigma RAG, onde um passo de recuperação extrai um número fixo de documentos para combinar com a query".
O problema é que esse passo único não aguenta pergunta composta.
Pensa numa pergunta tipo: "Qual framework PHP tem melhor suporte a filas, e como ele se compara ao Sidekiq do Ruby?". Um único embedding contra o índice vai cair em documentos sobre um tópico — filas em PHP ou Sidekiq, raramente os dois bem representados. A síntese sai incoerente, porque o modelo é forçado a costurar uma ponte entre duas buscas que nunca foram feitas.
No agentic RAG, a busca deixa de ser um evento único. Uma pergunta do usuário pode disparar entre cinco e vinte sub-recuperações internas: o agente quebra a pergunta, busca filas em PHP, busca Sidekiq, avalia os dois retornos e só então sintetiza. Ele orquestra. Ele decide que já tem evidência suficiente.
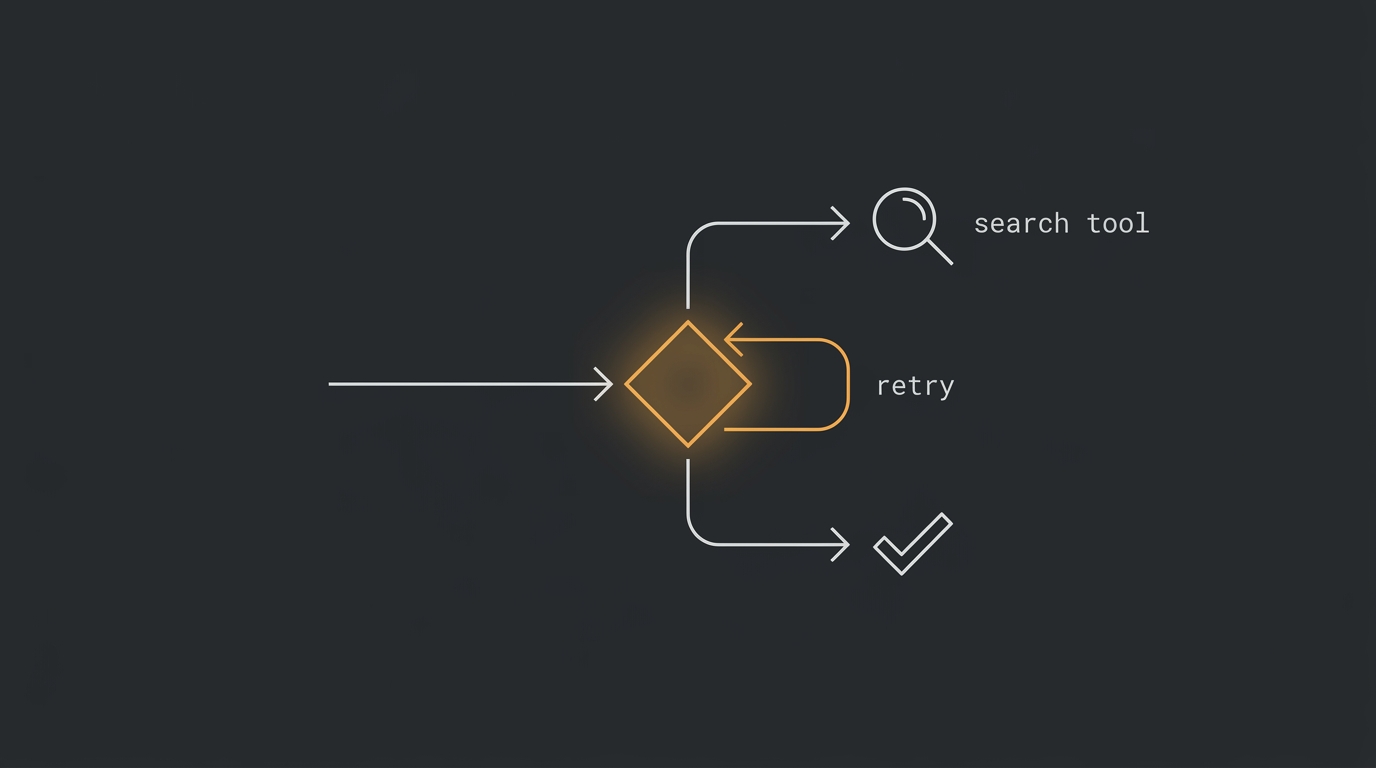
A mudança conceitual é essa: o LLM assume o controle do fluxo. Não é mais um pipeline com ordem predefinida. É um loop iterativo onde o modelo está no comando de cada decisão.
Pré-requisitos
Antes de sair codando, você precisa ter três coisas no lugar:
- [ ] Um LLM com tool calling funcionando (se você ainda não fez um agente chamar ferramenta, comece pelo tool calling na prática — agentic RAG é tool calling aplicado à busca).
- [ ] Um retriever já indexado: vector DB, embeddings, top-k retornando. RAG clássico funcionando é o degrau anterior.
- [ ] Um orquestrador de loop. Pode ser LangGraph, pode ser um
whileseu na mão. O que importa é poder voltar ao modelo depois de cada observação.
Se você já entende tool calling e já montou um RAG, agentic RAG não é uma stack nova. É a junção dos dois pilares — e é por isso que ele é a evolução natural de quem já passou por esses dois assuntos.
Mão na massa — montando um agentic RAG
O coração do agentic RAG é ridiculamente simples de enunciar: em vez de chamar o retriever você, no código, você entrega o retriever ao modelo como uma ferramenta e deixa ele decidir quando chamar.
Passo 1: registre o retriever como ferramenta
No RAG clássico, a busca é uma linha de código que sempre roda. Aqui, ela vira uma função que o modelo pode (ou não) invocar:
from langchain.tools import tool
@tool
def buscar_docs(query: str) -> str:
"""Busca na base de conhecimento técnica do blog.
Use quando a pergunta exigir fatos, benchmarks ou
detalhes que você não tem com confiança."""
docs = retriever.invoke(query)
return "\n\n".join(d.page_content for d in docs)
# a mágica está aqui: o modelo recebe a busca como opção, não como obrigação
model_com_busca = model.bind_tools([buscar_docs])
Repare na docstring. Ela não é decoração — é o que o modelo lê para decidir se e com qual query chamar a ferramenta. No agentic RAG, a docstring da tool é tão parte do prompt quanto o system message.
Passo 2: o nó de decisão e o nó de avaliação
O padrão oficial do LangGraph organiza o loop em quatro nós, e vale entender cada um porque é aqui que mora a inteligência:
- Generate query — o modelo olha a pergunta e decide: respondo direto ou chamo
buscar_docs? Se a pergunta for "oi, tudo bem?", ele não busca nada. Esse é o ganho que o RAG clássico não tem. - Retrieve — se ele pediu a tool, executa a busca.
- Grade documents — e aqui está o pulo do gato: um segundo passo do modelo avalia se o que voltou é relevante. Saída estruturada,
yesouno. - Generate answer / Rewrite — se relevante, responde. Se não, reescreve a query e volta pro começo do loop.
def avaliar_relevancia(state) -> str:
pergunta = state["question"]
docs = state["documents"]
nota = grader.invoke({"question": pergunta, "docs": docs})
return "responder" if nota.relevante == "yes" else "reescrever"
Passo 3: o loop que fecha — saber a hora de parar
A diferença entre um agente útil e um que queima sua fatura é uma só: critério de parada. O loop reescreve-e-busca pode rodar para sempre se você não colocar um teto. Sempre defina um número máximo de iterações:
if state["tentativas"] >= 3:
return "responder_com_o_que_tem" # melhor uma resposta honesta que um loop infinito
Esse if parece bobo. Não é. É a diferença entre uma demo bonita e algo que você deixa em produção sem medo de receber a conta no fim do mês.
Limitações e pontos de atenção — onde você vai se queimar
Aqui é onde eu preciso ser honesto, porque a internet vendeu agentic RAG como solução universal e não é. Tem engenharia séria nos números.
Um estudo experimental publicado no arXiv em 2026 comparou agentic RAG com um RAG clássico bem ajustado (o que eles chamam de enhanced) e os resultados são desconfortáveis para quem comprou o hype:
- Custo: o setup agentic exigiu 3.3× mais tokens de entrada e 1.9× mais tokens de saída. Em média.
- Latência: 1.5× mais lento ponta a ponta.
- Refinamento que não refina: quando o agente reformulava e buscava de novo, 53% dos documentos recuperados continuavam os mesmos. Ou seja: ele gastou um ciclo inteiro de inferência para trazer a mesma coisa.
- Pode piorar: no dataset FEVER, a performance agentic despencou para um F1 de 64.6, contra 87.9 do enhanced.
O recado dos autores é cirúrgico: "um RAG clássico bem otimizado pode igualar ou superar a performance agentic sendo mais eficiente". O ganho real do agentic aparece em query rewriting — ali ele entregou +2.8 pontos de NDCG@10 em média, e +7.8 no dataset NQ.
Traduzindo para decisão de produto: o salto de qualidade só paga o custo em perguntas difíceis, ambíguas, multi-hop. Para uma consulta factual de uma linha — "qual a versão atual do PHP?" — agentic RAG é desperdício puro. Você está pagando três vezes mais para reformular uma pergunta que nunca precisou ser reformulada.
A arquitetura mais sólida quase nunca é "tudo agentic". É híbrida: deixa o agente decidir se e como buscar, mas usa um reranking clássico e barato para refinar o que voltou. O melhor dos dois.
FAQ rápido
Agentic RAG substitui o RAG clássico? Não. Ele é uma camada de decisão por cima. O retriever, os embeddings, o vector DB — tudo continua igual. O que muda é quem aperta o gatilho da busca: agora é o modelo, não o seu código.
Por que meu agente entra em loop infinito de reescrita?
Falta critério de parada. Sem um teto de iterações e sem uma condição clara de "tenho evidência suficiente", o nó de grading pode reprovar documentos para sempre. Coloque um max_iterations e um fallback que responde com o que tem.
Vale a pena para um chatbot de FAQ? Quase nunca. FAQ é factual e de passo único — o cenário exato onde o RAG clássico ganha em custo e latência. Guarde o agentic para suporte técnico complexo, pesquisa, análise de documentos longos.
Preciso de LangGraph?
Não. LangGraph organiza o loop e dá observabilidade, mas o padrão é um while com tool calling. Comece simples, entenda o fluxo, e só adote framework quando a complexidade do grafo justificar.
Conclusão
Agentic RAG não é uma tecnologia nova que você precisa aprender do zero. É o encontro de dois assuntos que você já domina: tool calling e RAG. A recuperação deixa de ser um passo obrigatório do pipeline e vira uma ferramenta que o agente escolhe usar — ou não. Esse "ou não" é o ponto inteiro.
Mas poder decidir não é o mesmo que decidir bem. Os números mostram que agentic RAG mal calibrado custa 3× mais para entregar a mesma coisa, ou pior. A engenharia aqui não está em ligar o loop. Está em saber quando ele vale a pena, onde colocar o critério de parada, e onde um reranking clássico e barato resolve melhor.
É exatamente esse tipo de decisão de arquitetura — quando usar agente, quando usar pipeline fixo, onde está o trade-off real — que a gente coloca na mesa no Workshop Arquitetando Soluções de IA, um encontro prático de como desenhar software de verdade com agents de IA, sem slide motivacional. Se você chegou até aqui entendendo o trade-off do agentic RAG, é a conversa natural seguinte.
O próximo passo da sua parte é menor do que parece: pega o RAG que você já tem rodando, transforma o retriever numa tool e adiciona um nó de grading. Você acabou de construir seu primeiro agentic RAG. Se quiser ver esse mesmo padrão aplicado em PHP de verdade, com Prism e pgvector, é o que destrincho no agente multi-tool com RAG em Laravel. Agora a pergunta interessante não é mais "como faço o agente buscar" — é "quando eu deixo ele decidir".

{AI Engineer} — apaixonado por Laravel, arquitetura de software e construir produtos com impacto. Compartilho aqui tutoriais, descobertas e reflexões sobre o dia a dia de engenharia.