RAG tradicional busca uma vez e reza. Você manda a pergunta, o sistema puxa os top-k chunks do banco vetorial, joga tudo no prompt e espera que a resposta esteja ali. Quando está, funciona lindo. Quando não está, o modelo alucina com cara de confiança ou responde com o pedaço errado do contexto.
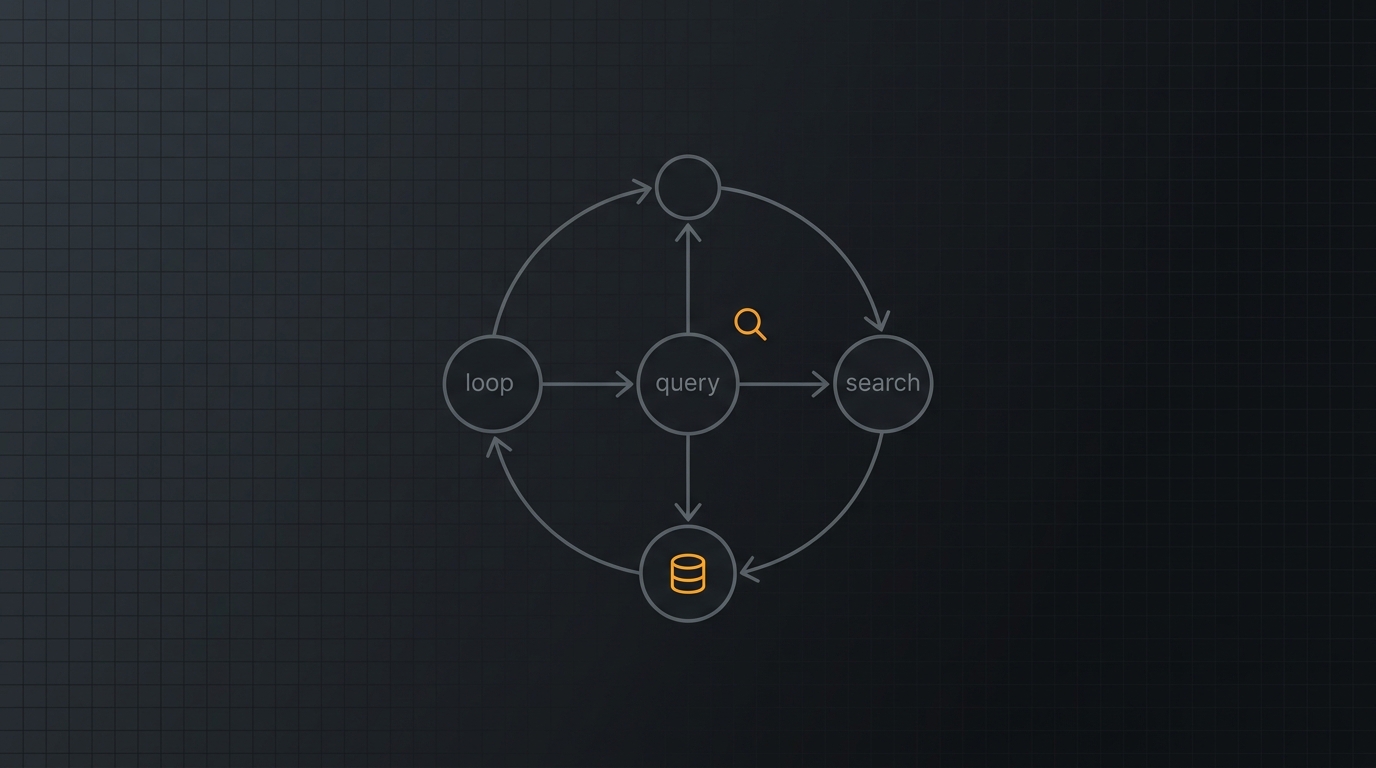
Agentic RAG vira esse jogo do avesso. Em vez de uma busca cega no início, o agente decide quando buscar, o que buscar e quando parar. Se o primeiro resultado é fraco, ele reformula a query e busca de novo. Se a pergunta tem duas partes, ele quebra em duas buscas. Se já tem o que precisa, ele para e responde.
Neste post você vai entender a diferença real entre RAG clássico e RAG com agente, ver onde cada um ganha (com número de paper, não achismo), e montar o loop de decisão sem deixar o custo explodir.
TL;DR
- O que é: RAG onde um agente controla a recuperação — decide se busca, formula a query, avalia o resultado e re-busca até ter contexto suficiente.
- Stack/Modelos: qualquer LLM com tool use (Claude, GPT, Gemini), um banco vetorial e um loop de controle. Sem framework obrigatório.
- Custo/Acesso: o loop custa caro — até 3,6x mais tokens que um RAG enhanced (arXiv:2601.07711). Vale quando a busca de uma rodada não resolve.
- Quando usar: perguntas multi-hop, domínios heterogêneos, query que precisa de reformulação. Não vale para FAQ de uma rodada.
O contexto — por que o RAG clássico trava
O pipeline RAG clássico é uma linha reta: embed da pergunta → busca os top-k → injeta no prompt → gera. É um one-shot. Como resume a Weaviate, "o contexto é recuperado uma vez. Não há raciocínio nem validação sobre a qualidade do que voltou".
Isso quebra em três cenários clássicos:
- Pergunta multi-hop. "Qual a stack do projeto que o time do João tocou em 2025?" Uma busca só não acha — você precisa primeiro descobrir qual projeto, depois buscar a stack dele.
- Query mal formulada. O usuário escreveu "aquele erro de timeout no deploy". O embedding dessa frase não bate com o chunk que fala "504 gateway na pipeline de CI".
- Contexto ruim que ninguém valida. Os top-k vieram, mas são irrelevantes. O RAG clássico não percebe — ele entrega o lixo pro modelo e o modelo trabalha com lixo. (Se o seu RAG vive nesse buraco, vale entender as causas reais de um RAG que não funciona antes de partir pro agente.)
O agentic RAG ataca exatamente esses pontos. Em vez de uma sequência fixa, ele coloca um loop de controle no meio: o modelo decide se deve recuperar, escolhe a ferramenta, formula a própria query, avalia o que voltou e decide se precisa buscar de novo. A survey de 2025 sobre reasoning RAG chama isso de passar do System 1 (heurística rápida e fixa) para o System 2 (raciocínio lento, deliberativo e adaptativo). É a diferença entre reagir e pensar.
Os três padrões de agentic retrieval
Não existe um "agentic RAG" único. Existem níveis. Do mais barato pro mais caro:
1. Router (single-agent)
O mais simples. O agente tem duas ou mais fontes — banco vetorial interno, busca web, uma API — e a única decisão dele é para onde mandar a query. "Pergunta sobre nossa doc? Vai pro vetorial. Pergunta sobre notícia de hoje? Vai pra web." É o ponto de entrada do rag agêntico e já resolve muita coisa sem custo alto.
2. Query rewriting + re-busca
Aqui o loop aparece. O agente busca, olha o resultado, e se ele for fraco, reformula a query e busca de novo. É onde o agentic retrieval mais ganha do RAG estático: no paper Is Agentic RAG worth it?, a reescrita adaptativa de query deu +2,8 pontos de NDCG@10 na média (55,6 contra 52,8) e até +7,8 em datasets heterogêneos como o NQ. Quando a query do usuário não bate com o vocabulário dos seus documentos, é isso que salva.
3. Decomposição multi-hop (planner)
O nível mais caro. O agente quebra uma pergunta complexa em sub-perguntas, busca cada uma, junta as evidências e só então responde. É o território do Self-RAG, onde o modelo usa tokens de reflexão para criticar o próprio rascunho e decidir, no meio da geração, se precisa buscar mais. Poderoso e caro — guarde pra quando uma rodada de busca genuinamente não resolve.
Tutorial te mostra o caminho — no Clã você constrói junto. Aula ao vivo toda semana, projetos reais de Engenharia de IA, ao lado de quem já está em produção.
Entrar no ClãMão na massa — o loop de decisão
A peça central do agentic RAG não é o banco vetorial. É o grader: o passo que avalia se o contexto recuperado é bom o suficiente. Sem ele, você só tem um RAG clássico com passos extras.
Passo 1: defina a ferramenta de busca
O agente precisa enxergar a busca como uma ferramenta que ele escolhe chamar, não como um passo automático. Com tool use:
tools = [{
"name": "buscar_docs",
"description": "Busca trechos na base de conhecimento interna. "
"Use quando precisar de fatos que não estão no contexto atual. "
"Reformule a query se a busca anterior trouxe resultado fraco.",
"input_schema": {
"type": "object",
"properties": {
"query": {"type": "string", "description": "consulta semântica"}
},
"required": ["query"],
},
}]
A descrição é o que ensina o agente quando buscar. "Use quando precisar de fatos que não estão no contexto" e "reformule se o resultado foi fraco" — essas frases viram comportamento.
Passo 2: o grader que decide re-buscar
Depois de cada busca, um passo barato classifica o resultado. Não precisa do modelo grande aqui — um modelo pequeno e um prompt enxuto resolvem:
GRADER_PROMPT = """Pergunta: {pergunta}
Trechos recuperados:
{trechos}
Esses trechos contêm o suficiente para responder a pergunta?
Responda APENAS com JSON: {{"suficiente": true|false, "motivo": "..."}}"""
def avaliar(pergunta, trechos):
resp = client.messages.create(
model="claude-haiku-4-5-20251001", # modelo barato pro grader
max_tokens=150,
messages=[{"role": "user",
"content": GRADER_PROMPT.format(pergunta=pergunta, trechos=trechos)}],
)
return json.loads(resp.content[0].text)
Passo 3: o loop com freio
Agora você junta tudo num loop — com um teto de iterações, que é o que segura o custo:
def agentic_rag(pergunta, max_rodadas=3):
query = pergunta
contexto = []
for rodada in range(max_rodadas):
trechos = vector_db.search(query, k=4)
contexto.extend(trechos)
veredito = avaliar(pergunta, contexto)
if veredito["suficiente"]:
break
# contexto fraco: peça ao modelo uma query melhor e tente de novo
query = reformular_query(pergunta, contexto, veredito["motivo"])
return responder(pergunta, contexto)
O max_rodadas=3 não é detalhe. É a diferença entre um sistema que custa 1,5x um RAG normal e um que entra em loop infinito reformulando query e queima seu orçamento de tokens numa pergunta só.
Limitações do agentic RAG e pontos de atenção
Aqui mora o motivo de o agentic RAG não ser a resposta pra tudo. O mesmo paper Is Agentic RAG worth it? mediu o preço da brincadeira:
- Custo. O agentic consome 3,3x mais tokens de entrada e até 3,6x mais custo total que um RAG enhanced. Cada rodada de avaliação e re-busca é mais prompt pago.
- Latência. É 1,5x mais lento. E a geração da resposta final já domina 45-50% do tempo nos dois — o loop só empilha em cima.
- Não ganha sempre. Em refinamento de documentos, o RAG enhanced com reranking marcou 49,5 de NDCG@10 contra 43,9 do agentic. Em domínios abertos e ruidosos como o FEVER, o roteamento simples foi mais confiável. A conclusão do paper é direta: "nenhuma abordagem é universalmente superior".
Traduzindo pra produção: não transforme seu RAG em agente porque é tendência. Transforme quando uma rodada de busca genuinamente não resolve o seu caso — multi-hop, query que precisa de reformulação, fontes heterogêneas. Para FAQ de uma rodada, o agente só adiciona custo e latência pra entregar a mesma resposta.
FAQ rápido
Quando usar agentic RAG e quando ficar no clássico? Use agentic quando a pergunta exige mais de uma busca (multi-hop), quando a query do usuário não bate com o vocabulário dos documentos, ou quando você tem várias fontes e precisa rotear. Fique no clássico para base homogênea e perguntas de uma rodada — é mais barato e mais rápido.
O loop não vai entrar em recursão infinita?
Só se você deixar. Sempre coloque um teto de iterações (max_rodadas) e um critério de parada no grader. Sem freio, o agente reformula query pra sempre e queima tokens.
Preciso de LangGraph ou LlamaIndex pra isso?
Não. Framework ajuda a organizar grafos complexos, mas o núcleo — buscar, avaliar, re-buscar — você monta com tool use puro e um loop for. Comece simples; só adicione framework quando o grafo de decisão crescer.
Dá pra usar um modelo barato no grader? Deve. O grader é classificação binária com prompt curto — é o caso de uso perfeito pra um Haiku ou similar. Guarde o modelo grande pra geração da resposta final, onde ele faz diferença.
Conclusão
RAG clássico é uma linha reta: busca uma vez e torce. Agentic RAG fecha um loop: busca, avalia, reformula, re-busca e só responde quando o contexto está de pé. O ganho é real em multi-hop e em query mal formulada — mas vem com 3,6x de custo e 1,5x de latência, então o trabalho de engenharia é saber quando o loop se paga e botar freio nele antes que ele rode sozinho.
O próximo passo é parar de pensar em "RAG" e começar a pensar em "agente que tem busca como uma das ferramentas". Quando a recuperação vira só mais um tool na cinta do agente, o resto da arquitetura — planejamento, memória, ação — entra naturalmente. É essa virada do prompt isolado pro harness completo que a gente coloca a mão de verdade no Do Prompt ao Harness: construindo um agente de vendas, pegando um agente do prompt até rodar em produção. Se você curtiu montar esse loop de decisão, é o desdobramento natural dele em cima de um caso real.

{AI Engineer} — apaixonado por Laravel, arquitetura de software e construir produtos com impacto. Compartilho aqui tutoriais, descobertas e reflexões sobre o dia a dia de engenharia.
Conteúdo é o que não falta. Falta quem desembaralhe: o que importa agora é como implementar do jeito certo. No Clã você tem isso ao vivo, toda semana, com quem já filtrou o ruído.
Entrar no Clã