RAG híbrido na prática: BM25, embeddings e reranker
Você joga a pergunta do usuário no banco vetorial, pega os 5 chunks mais "parecidos" e manda pro modelo. Funciona na demo. Aí entra em produção e alguém busca por um código de erro, um nome de tabela, um SKU. O embedding devolve cinco textos que falam sobre o assunto e nenhum que tem o termo exato. A resposta sai errada, confiante, e o usuário some.
O problema não é o embedding. É achar que busca semântica resolve sozinha o que é, no fundo, um problema de recuperação de informação com 50 anos de história. A saída é o RAG híbrido: busca lexical (BM25) acerta exatamente onde o vetor erra, e um reranker no fim da fila ainda arruma a ordem antes do contexto chegar no modelo.
Neste tutorial você vai montar um RAG híbrido de verdade: BM25 + embeddings fundidos por Reciprocal Rank Fusion, com um cross-encoder reranqueando o topo. Código rodando em Python, com LangChain, e as decisões de arquitetura explicadas — não só o pip install.
TL;DR
- O que é: pipeline de recuperação que combina busca lexical (BM25) com busca semântica (embeddings), funde os dois rankings com RRF e reranqueia o topo com um cross-encoder.
- Stack/Modelos: Python, LangChain (
EnsembleRetriever,ContextualCompressionRetriever), um modelo de embedding qualquer, Cohere Rerank 3.5 (oubge-reranker-v2-m3local). - Custo/Acesso: BM25 e embeddings open-source rodam local; o reranker pode ser API paga (Cohere) ou modelo aberto self-hosted.
- Quando usar: sempre que a base tem termos exatos que importam — códigos, nomes próprios, jargão, identificadores — e não só prosa.
Por que embedding sozinho erra mais do que você imagina
Embedding transforma texto em vetor e mede similaridade de significado. É ótimo pra paráfrase: "como cancelo minha assinatura" casa com um doc que fala em "encerramento de plano" sem compartilhar uma palavra. Esse é o superpoder da busca densa.
Agora vira a moeda. Pergunte por ERR_CONN_4031 ou pela tabela fct_pedidos_v2. O embedding não tem nada de especial pra esse token — ele dilui o identificador no meio do significado geral da frase e te devolve documentos temáticos, não o que contém o termo. Num teste com 10 mil documentos técnicos, BM25 acertou 94% de recall em queries de exact-match (códigos de erro, SKUs) contra 67% da busca vetorial pura. Não é detalhe. É um terço das buscas exatas indo pro buraco.
BM25 (Best Match 25) é o algoritmo lexical que é a espinha dorsal de buscadores desde os anos 90 — o ranking padrão do Elasticsearch saiu dele. Ele pontua por frequência de termo e raridade. Termo raro que bate exato? Pontuação alta. É exatamente o caso que o embedding mais erra.
Repara no padrão: os dois métodos falham em lados opostos. Densa erra no literal, lexical erra no conceitual. Juntar os dois não é redundância. É cobrir o ângulo cego um do outro.
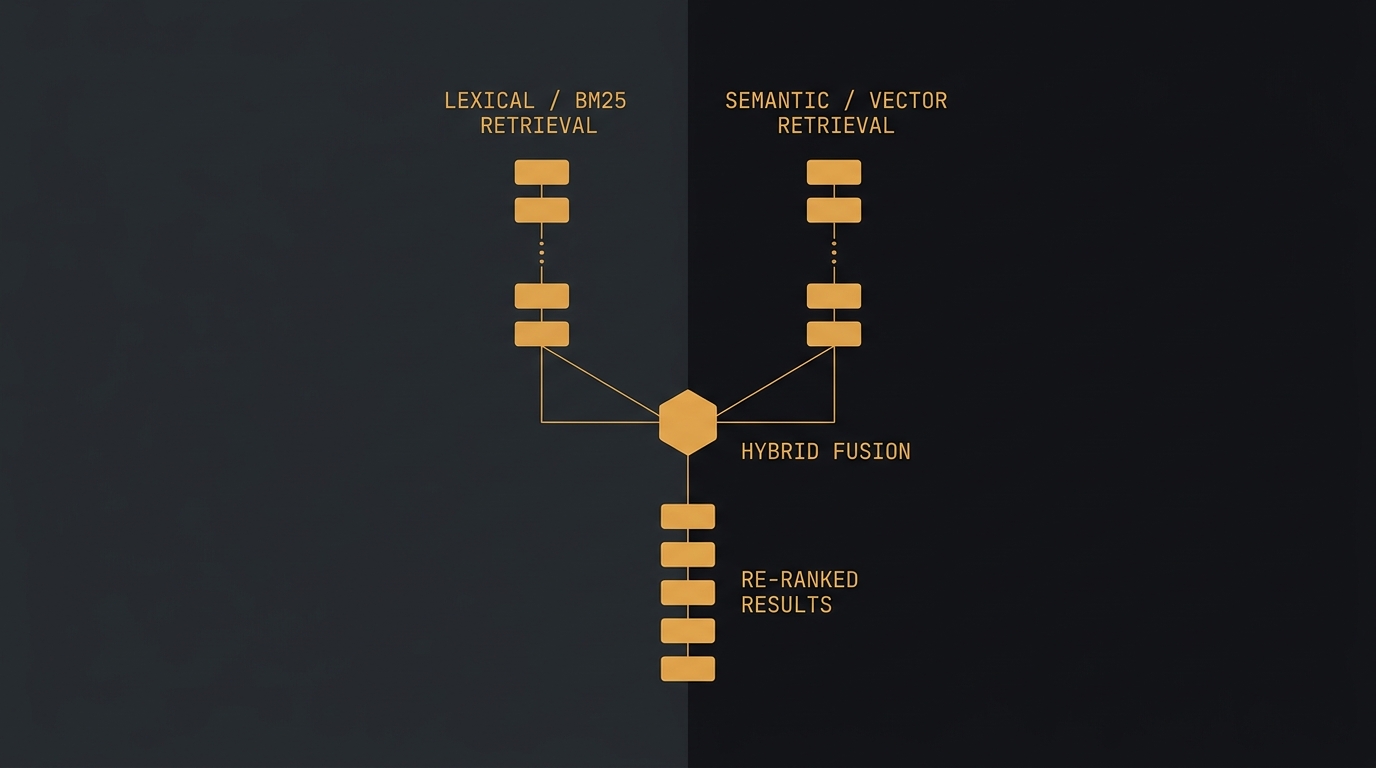
A arquitetura do RAG híbrido: recuperar amplo, fundir, reranquear
RAG híbrido bom tem três estágios. Não confunda.
- Recuperação dupla. A mesma query roda em paralelo no índice BM25 e no índice vetorial. Cada um devolve sua lista ranqueada — digamos, top 20 de cada.
- Fusão com RRF. Você tem duas listas com escalas de pontuação incompatíveis (BM25 dá score absoluto, cosseno dá 0–1). Não dá pra somar. Reciprocal Rank Fusion joga os scores fora e olha só a posição: cada documento ganha
1 / (k + rank)em cada lista, e os valores se somam. Por convençãok = 60. Um doc que aparece bem nas duas listas sobe; um que só uma lista amou fica no meio. Simples e robusto. - Reranking. Os ~20 candidatos fundidos passam por um cross-encoder, que reordena por relevância real query-documento. Só os top 3–5 vão pro modelo.
O primeiro estágio é sobre recall — não deixar o documento certo de fora. O terceiro é sobre precisão — botar o documento certo no topo. São objetivos diferentes, e por isso são etapas diferentes.
Pré-requisitos
- [ ] Python 3.11+ e
pip install langchain langchain-community rank_bm25. - [ ] Um modelo de embedding (OpenAI, um
sentence-transformerslocal, tanto faz) e um vector store (FAISS, Chroma, Qdrant). - [ ] Para o reranker: chave da Cohere (
pip install langchain-cohere) oupip install sentence-transformerspra rodar umbge-rerankerlocal. - [ ] Sua base já chunkada e indexada. Se você ainda não tem um RAG de pé, monte o básico primeiro e volte aqui.
Mão na massa
Passo 1: os dois retrievers
Indexe o mesmo corpus de duas formas. BM25 a partir dos documentos crus; o vetorial a partir dos embeddings.
from langchain_community.retrievers import BM25Retriever
from langchain_community.vectorstores import FAISS
from langchain_openai import OpenAIEmbeddings
# busca lexical
bm25 = BM25Retriever.from_documents(docs)
bm25.k = 20
# busca densa
vectorstore = FAISS.from_documents(docs, OpenAIEmbeddings())
dense = vectorstore.as_retriever(search_kwargs={"k": 20})
Pega 20 de cada, não 5. Aqui você quer recall: é melhor o documento certo chegar na posição 18 do que não chegar. O reranker conserta a ordem depois.
Passo 2: fundir com RRF
O EnsembleRetriever do LangChain já faz Reciprocal Rank Fusion nativamente. Você passa os dois retrievers e os pesos.
from langchain.retrievers import EnsembleRetriever
hybrid = EnsembleRetriever(
retrievers=[bm25, dense],
weights=[0.4, 0.6], # [lexical, semântico]
)
Os pesos enviesam a fusão. [0.5, 0.5] trata igual; [0.4, 0.6] dá um empurrão pro semântico. Não existe número mágico — depende da sua base. Base cheia de identificador e jargão pede mais peso no BM25. Base de linguagem natural solta pede mais no vetor. Isso se mede com um dataset de avaliação, não se chuta.
Passo 3: o reranker no topo
Agora a camada que muda o jogo (e que rende um post inteiro só pra ela). O ContextualCompressionRetriever envolve o retriever híbrido e passa os candidatos por um compressor — no caso, o reranker.
from langchain.retrievers import ContextualCompressionRetriever
from langchain_cohere import CohereRerank
reranker = CohereRerank(model="rerank-v3.5", top_n=4)
pipeline = ContextualCompressionRetriever(
base_compressor=reranker,
base_retriever=hybrid,
)
docs = pipeline.invoke("por que recebo ERR_CONN_4031 ao subir o deploy?")
O híbrido entrega 20–40 candidatos; o reranker devolve os 4 melhores, na ordem certa. É esse top_n=4 que vai pro prompt do modelo. Quer trocar a Cohere por um modelo aberto? Troca o compressor por um CrossEncoderReranker apontando pro BAAI/bge-reranker-v2-m3 — a estrutura do pipeline não muda.
Passo 4: erro comum — reranquear cedo demais
O engano clássico é recuperar só 5 candidatos e mandar pro reranker. Reranker não inventa documento: ele reordena o que recebe. Se o doc certo não passou no primeiro estágio, nenhum cross-encoder no mundo o traz de volta. Recupere largo (20–40), reranqueie estreito (3–5). Recall primeiro, precisão depois.
O reranker: por que cross-encoder, e não mais um embedding
Embedding é um bi-encoder: ele codifica a query e o documento separadamente, em vetores independentes, e compara no fim. Rápido — dá pra pré-computar tudo — mas a query nunca "olha" o documento durante a codificação.
Cross-encoder é outra coisa. Ele recebe o par query+documento junto e roda cross-attention entre os dois em tempo de query. Cada token da pergunta pesa contra cada token do documento. É muito mais caro — por isso você só roda nos ~20 finalistas, nunca na base inteira — e muito mais preciso no julgamento de relevância.
O ganho é real e medido. A Cohere reporta que o Rerank melhora a acurácia da resposta entre 20% e 35% sobre busca por embedding pura, ainda cortando tokens — porque você manda 4 chunks ótimos em vez de 10 mais ou menos. Em benchmarks de NDCG@10, modelos abertos como o bge-reranker-v2-m3 ficam praticamente empatados com a Cohere, e os dois batem busca vetorial pura com folga. Ou seja: dá pra ter o ganho sem depender de API paga.
A intuição que vale guardar: o primeiro estágio responde "isso parece relevante?". O cross-encoder responde "isso é relevante pra esta pergunta?". A segunda pergunta é a que importa.
Limitações e pontos de atenção
- Latência. São três passos em série; o reranker adiciona uma chamada (de rede, se for API). Em fluxo conversacional cabe; em autocomplete de baixa latência, meça antes de prometer.
- Custo do reranker. Reranker por API cobra por documento avaliado. Recuperar 100 candidatos pra reranquear sai caro e quase não melhora sobre 20–40. Acerte o
kdo primeiro estágio. - Tuning não é opcional. Pesos do RRF,
kde recuperação,top_ndo rerank — tudo isso é dado, não palpite. Sem um dataset de avaliação (nem que sejam 30–50 perguntas com a resposta certa anotada), você está otimizando no escuro. - Híbrido não conserta chunk ruim. Se você fatiou o documento no meio da frase, recuperação melhor só entrega lixo bem ranqueado. Chunking vem antes.
FAQ
BM25 não ficou obsoleto com os embeddings? Não, e é justamente o contrário. Ele continua ganhando exatamente nas queries que mais importam: termo exato, identificador, jargão raro. Em produção, são essas que mais doem quando falham.
Preciso de um vector DB que suporte híbrido nativo? Ajuda (Qdrant, Weaviate e Elasticsearch fazem fusão no servidor), mas não é obrigatório. O EnsembleRetriever funde duas listas no lado da aplicação — dá pra começar com FAISS + BM25 em memória.
Reranker resolve o "lost in the middle"? Ajuda bastante. Como ele entrega menos documentos e melhor ordenados, o modelo recebe um contexto curto e denso em vez de dez chunks medianos onde a informação certa se perde no meio.
Cohere ou modelo aberto? Comece pela Cohere pra validar o ganho sem fricção de infra. Se o volume justificar, migre pro bge-reranker-v2-m3 self-hosted — a qualidade é equivalente e o pipeline não muda.
Fechando
RAG híbrido não é hype de arquitetura. É reconhecer que recuperação tem duas naturezas — literal e semântica — e que jogar fora uma delas custa caro em produção. BM25 cobre o exato, embedding cobre o conceitual, RRF junta as duas listas sem brigar por escala de score, e o cross-encoder dá a palavra final sobre o que realmente responde a pergunta. Quatro peças simples, cada uma resolvendo um problema específico.
O próximo passo é parar de tratar isso como "feature de busca" e começar a tratar como engenharia do harness em volta do modelo — recuperação, avaliação, ordem do contexto, limite de tokens. É exatamente esse salto, do prompt isolado para o harness que sustenta um agente em produção, que a gente coloca na mesa no workshop Do Prompt ao Harness: construindo um agente de vendas, com o pipeline rodando de verdade.
Montou o seu, mediu o NDCG antes e depois do reranker, e o número subiu? Então você já entendeu a parte que separa demo de produto.

{AI Engineer} — apaixonado por Laravel, arquitetura de software e construir produtos com impacto. Compartilho aqui tutoriais, descobertas e reflexões sobre o dia a dia de engenharia.
Você também pode gostar
Reranker: o passo que faz seu RAG parar de devolver lixo
A busca vetorial traz 20 candidatos "parecidos" — mas parecido não é relevante. O reranker reordena por relevância real antes de mandar pro modelo. Este post mostra cross-encoder vs busca híbrida e quando cada um vale, com código rodando.
Cross-encoder reranker: o componente que mais eleva qualidade do seu agente por dólar
Retrieval traz 100 candidatos, reranker escolhe os 10 certos. Entenda o trade-off latência x precisão, quando rerankar 50 vs. 200 documentos e por que cross-encoder é o investimento de melhor ROI antes de trocar para um LLM mais caro.
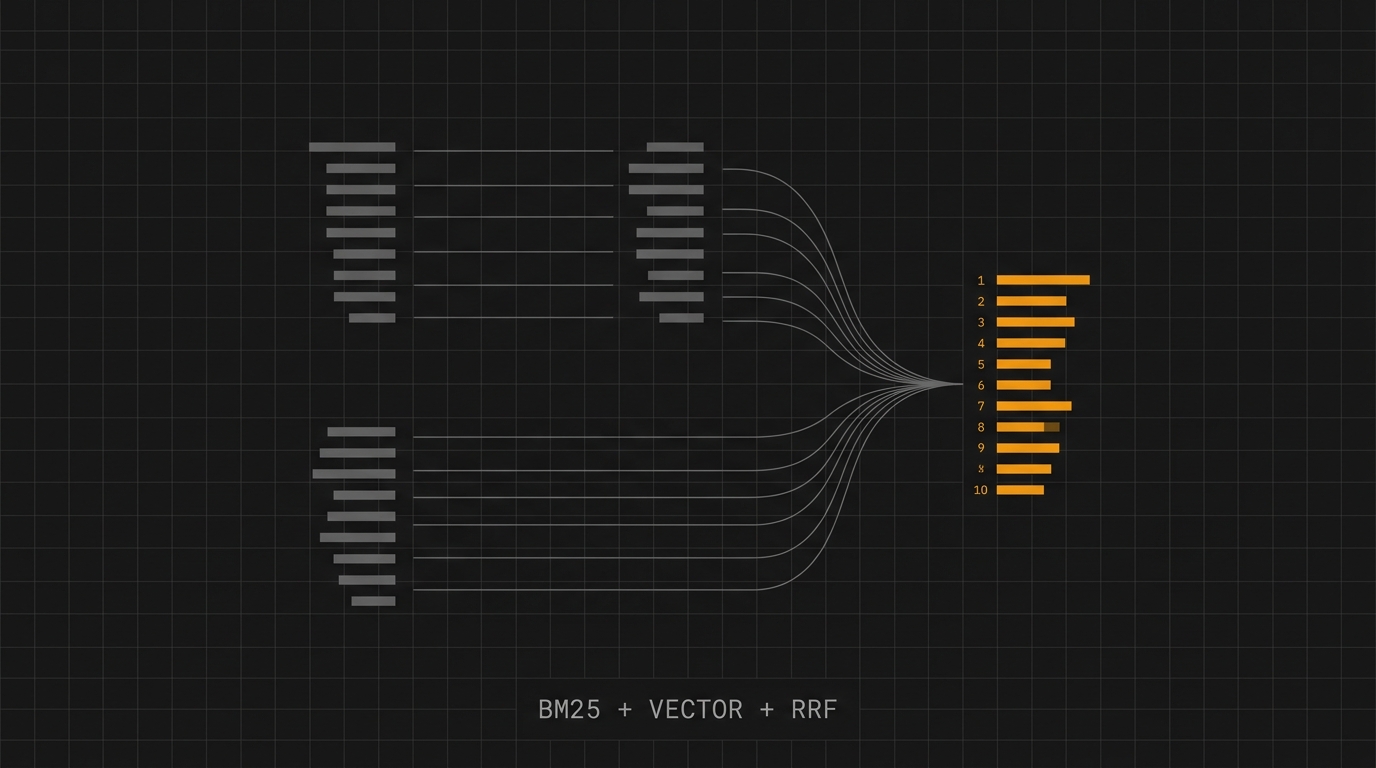
Busca híbrida: a receita BM25 + vetor + RRF que resolve SKU, part-number e semântica
Embedding puro confunde "RX-7000" com "RX-5000". BM25 puro perde sinônimos. A receita certa é rodar os dois em paralelo e fundir os rankings com Reciprocal Rank Fusion. Neste post, a fórmula que sustenta tudo isso, o pipeline completo em Elasticsearch e como aplicar em catálogo de produto que mistura SKU, part-number e busca semântica.
RAG do zero: chunking, embeddings e busca que funciona
RAG não é mágica: é quebrar texto, virar vetor e buscar bem. O passo a passo de um RAG do zero — chunking recursive com overlap, embeddings com text-embedding-3-small e busca por similaridade no Postgres com pgvector e índice HNSW. Errar o chunking é onde 80% dos RAGs nascem ruins.
