Adoção segura de IA na empresa: EU AI Act + NIST RMF na prática (e o que o jurídico quer ver)
Adoção segura de IA na empresa: EU AI Act + NIST RMF na prática (e o que o jurídico quer ver)
Você lembra daquela feature de "ranking automático de candidatos" que o time de RH pediu mês passado.
Roda em produção. Usa LLM. Ninguém escreveu uma linha de documentação sobre por que ela foi aprovada.
Em 2 de agosto de 2026 o EU AI Act entra na parte que tem dente. Multa, fiscal, processo. E o seu jurídico vai bater na porta perguntando coisas que nenhum dev quer responder no susto: qual o nível de risco do sistema? Quem aprovou? Como vocês medem viés? Tem log de decisão?
Esse post é o mapa para responder essas perguntas antes da pergunta chegar. Quatro níveis de risco do EU AI Act traduzidos pra exemplos de feature, o NIST AI RMF resumido no tempo de uma cerveja, checklist de 12 itens que você roda no seu próprio repo, e um template de AI Decision Record (AIDR) pronto pra colar. Sem teoria de consultoria. Engenharia.
TL;DR
- O que é: guia prático de governança de IA cobrindo EU AI Act (regulação obrigatória) + NIST AI RMF (framework voluntário virou padrão de facto).
- Stack/Modelos: agnóstico — vale pra Claude, GPT, Gemini, modelos open-source, agentes, RAG, classificação, scoring.
- Custo/Acesso: zero. Texto regulatório é público.
- Datas que importam: 2/ago/2026 = enforcement geral do EU AI Act + obrigações GPAI; 2/dez/2027 = sistemas de alto risco standalone (data revisada no acordo de maio/2026 entre Conselho e Parlamento).
- Documentos-fonte: AI Act consolidado, NIST AI 100-1 (RMF 1.0), NIST AI 600-1 (GenAI Profile).
O contexto — por que isso virou problema do dev e não só do jurídico
Quem trabalha com IA em produção hoje tem três opções: fingir que não tem regulação, esperar o jurídico explicar (e descobrir que o jurídico também não sabe), ou aprender o suficiente pra traduzir o regulatório em decisão de arquitetura.
O EU AI Act foi publicado no Jornal Oficial em 12 de julho de 2024. Já está em vigor — mas a aplicação é faseada. Em fevereiro/2025 entraram as proibições do Artigo 5 e os requisitos de AI literacy. Em agosto/2025 as obrigações para modelos de propósito geral (GPAI). Em 2 de agosto de 2026 entra o resto da máquina: governança, autoridades nacionais notificadoras, poderes de enforcement da Comissão, e penalidades.
E penalidade não é simbólica. Artigo 99 prevê três faixas:
- Prática proibida (Art. 5): até €35 milhões ou 7% do faturamento global anual — o que for maior.
- Não-conformidade de sistema de alto risco: até €15 milhões ou 3%.
- Informação incorreta a autoridade: até €7,5 milhões ou 1%.
Antes que você relaxe pensando "mas eu sou brasileiro": o AI Act é extraterritorial. Se o output do seu sistema é usado por gente na União Europeia, ou se você coloca um sistema/GPAI no mercado europeu, você está dentro. Não importa onde o servidor mora. Importa quem consome o resultado.
Em paralelo, do outro lado do Atlântico, o NIST publicou o AI Risk Management Framework 1.0 em janeiro de 2023, voluntário, e em julho de 2024 lançou o GenAI Profile (NIST AI 600-1) cobrindo 12 categorias de risco específicas de IA generativa.
EU AI Act diz o que você precisa atingir. NIST RMF e ISO/IEC 42001 mostram como rodar isso operacionalmente. Os três conversam — a sobreposição entre EU AI Act e ISO 42001 está em torno de 40–50% dos requisitos de alto nível.
Os quatro níveis de risco do EU AI Act — traduzidos pra feature real
A regulação classifica sistemas de IA em quatro níveis. Vou parar de copiar a definição da Comissão e mostrar com exemplos do dia a dia.
1. Risco inaceitável — proibido
Não existe "depende". Esses sistemas são banidos. Citando os mais relevantes do Artigo 5:
- Manipulação subliminar que cause dano (ex: dark pattern com IA que empurra o usuário pra contratar produto que prejudica ele).
- Exploração de vulnerabilidade por idade, deficiência ou condição social/econômica.
- Social scoring por autoridade pública.
- Reconhecimento de emoção no ambiente de trabalho ou na escola (exceto razões médicas/segurança).
- Inferência de raça, opinião política, orientação sexual ou crença religiosa a partir de dados biométricos.
- Identificação biométrica remota em tempo real em espaço público para fins de law enforcement (com exceções estreitíssimas).
Se a sua feature se encaixa, não tem mitigação. O caminho é redesenhar ou matar o produto.
2. Alto risco — regulado pesado, mas permitido
A maior parte do trabalho do dev mora aqui. Anexo III lista oito áreas:
- Biometria (identificação remota, categorização biométrica, reconhecimento de emoção fora dos contextos proibidos).
- Infraestrutura crítica.
- Educação e formação profissional (admissão, avaliação, detecção de cola).
- Emprego e gestão de trabalhadores (triagem de currículo, ranking de candidato, decisão de promoção/demissão, monitoramento de performance).
- Acesso a serviços essenciais (crédito, seguro de vida e saúde, benefícios públicos, priorização de emergência).
- Law enforcement (perfilamento de risco criminal).
- Migração, asilo e controle de fronteira.
- Administração da justiça e processos democráticos.
Exemplos práticos que provavelmente passam pela sua mesa:
- Triagem de currículo com LLM que ranqueia ou rejeita candidatos → alto risco (categoria emprego).
- Score de crédito assistido por modelo → alto risco (serviços essenciais).
- Detecção de cola em prova online com visão computacional → alto risco (educação).
- Avaliação automatizada de desempenho que alimenta decisão de PDI/PIP → alto risco (gestão de trabalhadores).
Obrigações principais para sistema de alto risco: gestão de risco contínua (Art. 9), governança de dados (Art. 10), documentação técnica (Art. 11), logging (Art. 12), transparência ao deployer (Art. 13), supervisão humana (Art. 14), accuracy/robustez/cibersegurança (Art. 15), sistema de qualidade (Art. 17). O acordo de simplificação de maio/2026 empurrou a data efetiva pra 2 de dezembro de 2027 (standalone) e 2 de agosto de 2028 (embedded em produto regulado). Não é desculpa pra dormir — a documentação tem que existir antes, porque sem ela o sistema não pode entrar no mercado.
3. Risco limitado — obrigação de transparência
Chatbot, gerador de imagem, deepfake, sistema de recomendação de conteúdo. A regra é simples: o usuário tem que saber que está interagindo com IA ou consumindo conteúdo gerado por IA. Conteúdo sintético precisa estar marcado de forma legível por máquina.
Aplicação prática:
- Chatbot na home → label "Você está conversando com um assistente de IA" + handoff humano disponível.
- Imagem gerada por IA usada em produto → metadata C2PA ou label visível.
- Texto gerado por IA em interação direta → disclosure quando não for óbvio.
4. Risco mínimo — sem obrigações
Filtro de spam, recomendador interno de produto que não toma decisão sobre pessoa, jogo, classificação de tag. Sem requisitos formais — mas é justamente onde mora a maior parte das features de IA, e onde a empresa precisa decidir o quanto do framework voluntário (NIST/ISO) ela quer aplicar mesmo sem obrigação.
NIST AI RMF em cinco minutos
O NIST AI RMF 1.0 organiza tudo em quatro funções, e elas conversam direto com o ciclo de vida do sistema:
- GOVERN. Função transversal. Quem é dono do risco? Quais políticas? Como personas (PM, dev, jurídico, segurança, ética) se coordenam? Como incidente vira aprendizado? Sem GOVERN funcionando, as outras três viram teatro.
- MAP. Contexto. Pra que serve o sistema? Quem são os impactados? Qual o pior cenário plausível? Onde está o limite do modelo? Essa função é o review pré-build, não pós.
- MEASURE. Métrica. Como você mede qualidade, viés, robustez, drift, segurança, custo, latência? Métricas têm que existir antes do go-live, não depois do incidente.
- MANAGE. Ação. Prioriza risco, aloca recurso, monitora em produção, responde a incidente, comunica stakeholder. É o loop operacional.
O GenAI Profile (NIST AI 600-1) acrescenta 12 categorias específicas de IA generativa que você precisa varrer: CBRN, confabulação (alucinação), conteúdo violento/abusivo, privacidade de dados, impacto ambiental, viés/homogenização, configuração humano-IA, integridade de informação, segurança da informação, propriedade intelectual, conteúdo obsceno/degradante, e integração de cadeia de valor.
Cada uma dessas mapeia pra ações concretas dentro de GOVERN/MAP/MEASURE/MANAGE. São mais de 200 sub-ações sugeridas. Você não vai aplicar todas — vai escolher as que importam pro perfil de risco do seu sistema.
Pré-requisitos antes de você abrir o checklist
- [ ] Inventário de todos os sistemas de IA usados pela empresa (inclusive os que ninguém chamou de IA, tipo "automação inteligente").
- [ ] Decisão clara sobre se você é provider (constrói o sistema), deployer (usa um sistema de terceiro) ou os dois — as obrigações mudam.
- [ ] Pelo menos uma pessoa que entenda Anexo III bem o suficiente pra classificar caso a caso.
- [ ] Repositório vivo onde decisões de IA são versionadas (não basta deixar num Notion órfão).
Checklist técnico de 12 itens — pra você rodar no seu repo essa semana
Esses doze itens não substituem auditoria. Mas se você não passa pelos doze, não tem como olhar pro EU AI Act sem suor frio.
- Inventário versionado. Lista única (CSV, YAML, banco) de todos os sistemas de IA em uso ou desenvolvimento, com responsável, propósito, dados de entrada, dados de saída, fornecedor do modelo, status (POC, produção, deprecated).
- Classificação de risco documentada. Para cada sistema do inventário, um campo
eu_ai_act_risk_levelcom valorprohibited,high,limited,minimal+ justificativa em linguagem natural ligada ao artigo/anexo aplicável. - AI Decision Record (AIDR). Para cada sistema de risco limitado ou superior, um markdown no repo nos moldes de ADR técnico (template completo abaixo).
- Linhagem de dados. Documentação clara de onde os dados de treino, fine-tuning e avaliação vieram, com licença, base legal (LGPD/GDPR) e data de coleta. Sem isso, governança de dados (Art. 10) fica impossível.
- Cartão do modelo. Resumo público ou interno por sistema: uso pretendido, uso desaconselhado, métricas em dataset de avaliação, viéses conhecidos, limitações. Pode ser model card no estilo HuggingFace.
- Logging de decisão. Toda chamada de modelo que afeta pessoa precisa logar input, output, versão do modelo, prompt template, timestamp, identificador de sessão. Retenção compatível com o Art. 12.
- Avaliação contínua. Pipeline de eval com dataset de regressão rodando em CI ou em schedule. Métricas mínimas: accuracy/precision relevantes pro caso, taxa de alucinação se for LLM, viés por grupo protegido se for decisão sobre pessoa.
- Supervisão humana especificada. Para sistemas de alto risco, quem revisa, quando revisa, com que poder de override. "Humano no loop" sem decisão real é teatro de compliance.
- Política de transparência ao usuário final. Disclosure de IA quando aplicável (Art. 50). Texto pronto, posicionamento decidido, não improvisado pelo PM no dia.
- Plano de incidente de IA. Quem aciona, em quanto tempo, qual rollback existe, como você desliga o modelo sem quebrar o produto. Não é o mesmo plano do incidente de infra.
- Gestão de fornecedor. Para todo modelo de terceiro (OpenAI, Anthropic, Google, qualquer GPAI), DPA atualizado, escopo de uso definido, residência de dados confirmada, política de uso de dados de cliente para treino lida. Você é deployer — não pode terceirizar a obrigação.
- Revisão periódica. Calendário (trimestral basta pra maioria) onde cada AIDR é re-aberto, métricas são reavaliadas, drift é checado, decisão de manter/mudar/desligar é registrada.
Se você só consegue fazer três dessa lista nos próximos 60 dias, faz inventário (1), classificação (2) e AIDR (3). O resto desabrocha a partir deles.
Template — AI Decision Record (AIDR)
Coloca isso em docs/aidr/AIDR-NNNN-nome-curto.md no seu repo. Versionado em Git, revisado em PR, igual ADR de arquitetura. Sem isso, jurídico não tem como te defender.
# AIDR-0007: Triagem assistida de currículo para vagas de engenharia
- **Status:** Approved
- **Data:** 2026-05-23
- **Autor:** Lucas Almeida (Eng), Marina Tavares (Jurídico), Rafael Lima (Produto)
- **Revisão programada:** 2026-08-23
- **Sistema:** `talent-screening-service`
- **Versão do modelo:** `claude-sonnet-4-6` via Anthropic API, prompt template v3.2
## Contexto e propósito
Reduzir o tempo do recrutador na pré-triagem de currículos para vagas
técnicas. O sistema recebe currículo + descrição da vaga e devolve um
resumo estruturado + score de fit (0-100) + 3 perguntas sugeridas para
entrevista.
## Classificação EU AI Act
- **Nível:** Alto risco.
- **Base legal:** Anexo III, ponto 4(a) — sistemas para triagem ou
avaliação de candidatos a emprego.
- **Justificativa:** o output influencia decisão de avanço no funil de
contratação, ainda que a decisão final seja humana.
## Mapeamento NIST AI RMF
- **GOVERN:** dono do risco = Head of Talent. Política de IA em RH
publicada em `policies/ai-talent.md`.
- **MAP:** stakeholders impactados = candidatos a vaga. Pior cenário =
exclusão sistemática de grupo demográfico. Limite do modelo =
alucinação sobre experiência não mencionada no CV.
- **MEASURE:** métricas em dataset balanceado (500 CVs) → precisão de
classificação de senioridade 89%, taxa de alucinação 2.4%, viés por
gênero (diferença de score médio) 1.2pp.
- **MANAGE:** revisão humana obrigatória antes de qualquer rejeição.
Score nunca é mostrado ao recrutador como decisão, só como sinal.
## Dados
- **Entrada:** texto livre do CV (PDF parseado) + JD textual.
- **Não enviar:** foto, idade, gênero declarado, estado civil.
- **Retenção do log:** 24 meses (compatível com Art. 12).
- **Base legal LGPD:** legítimo interesse com avaliação documentada em
`legal/lia-talent-screening.md`.
## Supervisão humana
- Toda rejeição passa por recrutador antes de notificação ao candidato.
- Override registrado com motivo livre + categoria fixa.
- Métricas de override revisadas mensalmente; override >30% dispara
retreinamento do prompt.
## Transparência
- Candidato é informado no formulário de candidatura que IA assiste a
triagem inicial. Texto em `legal/disclosure-candidato.md`.
- Direito a revisão humana garantido e acionável por e-mail.
## Riscos identificados e mitigação
| Risco | Mitigação | Owner |
|-------|-----------|-------|
| Viés por nome / endereço | Mascarar nome e endereço antes do prompt | Eng |
| Alucinação sobre experiência | System prompt com restrição explícita + eval de regressão | Eng |
| Drift de qualidade da JD | Validação de schema antes de envio ao modelo | Eng |
## Decisão de prosseguir
Aprovado para produção sob as condições acima. Re-avaliação obrigatória
em 90 dias ou antes se métricas de viés ultrapassarem 3pp.
Esse template parece longo. Não é. É uma página de Markdown que substitui três reuniões e cobre 80% do que um auditor vai pedir pra ver.
Limitações e pontos de atenção
Algumas armadilhas que custam caro:
- "Mas a IA é só sugestão" não te isenta de Anexo III. O critério é o uso pretendido, não o disclaimer no rodapé. Sistema que ranqueia candidato é alto risco mesmo que o RH "decida no final".
- Provider vs. deployer não é fixo. Você pode ser deployer pra GPT-4 e provider de uma feature de scoring que vende pra clientes B2B. As obrigações vão pesar diferente em cada papel.
- Fine-tuning não te transforma em provider de GPAI, mas pode te transformar em provider do sistema final. Lê o Artigo 25 com calma.
- NIST RMF não é certificação. Não tem auditor que assina "estou em conformidade com NIST RMF". O framework é uma régua. Quem certifica é ISO 42001 (e mesmo essa, ainda não é harmonised standard sob o AI Act).
- Não terceirize o entendimento. Comprar uma plataforma de "EU AI Act compliance" sem que dev e jurídico tenham lido o texto da regulação garante que você vai gastar dinheiro e ainda assim falhar em auditoria. O texto é público e legível — começa pelo resumo oficial da Comissão.
FAQ rápido
Sou uma startup brasileira sem clientes na Europa. Preciso me preocupar com o EU AI Act?
Hoje, provavelmente não. Mas se você vende SaaS, basta um cliente europeu usar seu produto pra você cair na regra. E o Brasil está discutindo o PL 2338/2023 com estrutura muito similar — vale começar agora.
O Brasil já tem alguma coisa equivalente?
Não com força de lei ainda. O PL 2338/2023 (Marco Legal da IA) tramita no Congresso e bebe fortemente do EU AI Act. ANPD já publicou guias sobre IA e LGPD. Quem se prepara pro AI Act sai na frente do que vier por aqui.
Posso usar API da OpenAI/Anthropic sem violar nada?
Sim, desde que você documente como deployer: contratos, escopo de uso, residência de dados, política de uso para treino. Os providers de GPAI grandes estão publicando suas próprias compliance summaries — leia antes de assinar.
Qual a diferença entre AI Decision Record e Architecture Decision Record?
ADR registra decisão técnica ("escolhemos PostgreSQL ao invés de MongoDB"). AIDR registra decisão sobre sistema de IA incluindo classificação regulatória, riscos para pessoa, supervisão humana e plano de revisão. É um ADR especializado.
Conclusão
Adoção segura de IA não é freio. É chassi.
Quem trata regulação como inimigo vai correr atrás em agosto/2026. Quem trata como restrição de design constrói feature melhor: dado mais limpo, supervisão humana real, métrica de viés que existe antes do incidente, decisão registrada antes do TechCrunch ligar.
EU AI Act te diz o que. NIST RMF te diz como. ISO 42001 te diz como manter. E o AIDR no seu repo te dá a única coisa que importa quando o auditor liga: prova versionada de que você pensou antes de fazer.
Esse tipo de conversa — engenharia de IA em produção, com regulamentação, dor de implantação, decisão de arquitetura — é o que rola toda semana na Beer and Code, a melhor comunidade de AI engineering em português, com grupo no WhatsApp aberto pra quem está construindo IA em produção.
Começa pelo inventário. Tudo desabrocha dali.

{AI Engineer} — apaixonado por Laravel, arquitetura de software e construir produtos com impacto. Compartilho aqui tutoriais, descobertas e reflexões sobre o dia a dia de engenharia.
Você também pode gostar

Compliance EU AI Act + NIST RMF: checklist de 18 itens para times brasileiros que vendem pra fora
EU AI Act entra em vigor em 2 de agosto de 2026, com multas de até 7% do faturamento global. Checklist técnico de 18 itens em ordem de prioridade, mapeado para NIST RMF (Govern/Map/Measure/Manage), com templates Markdown prontos para colar no repositório.
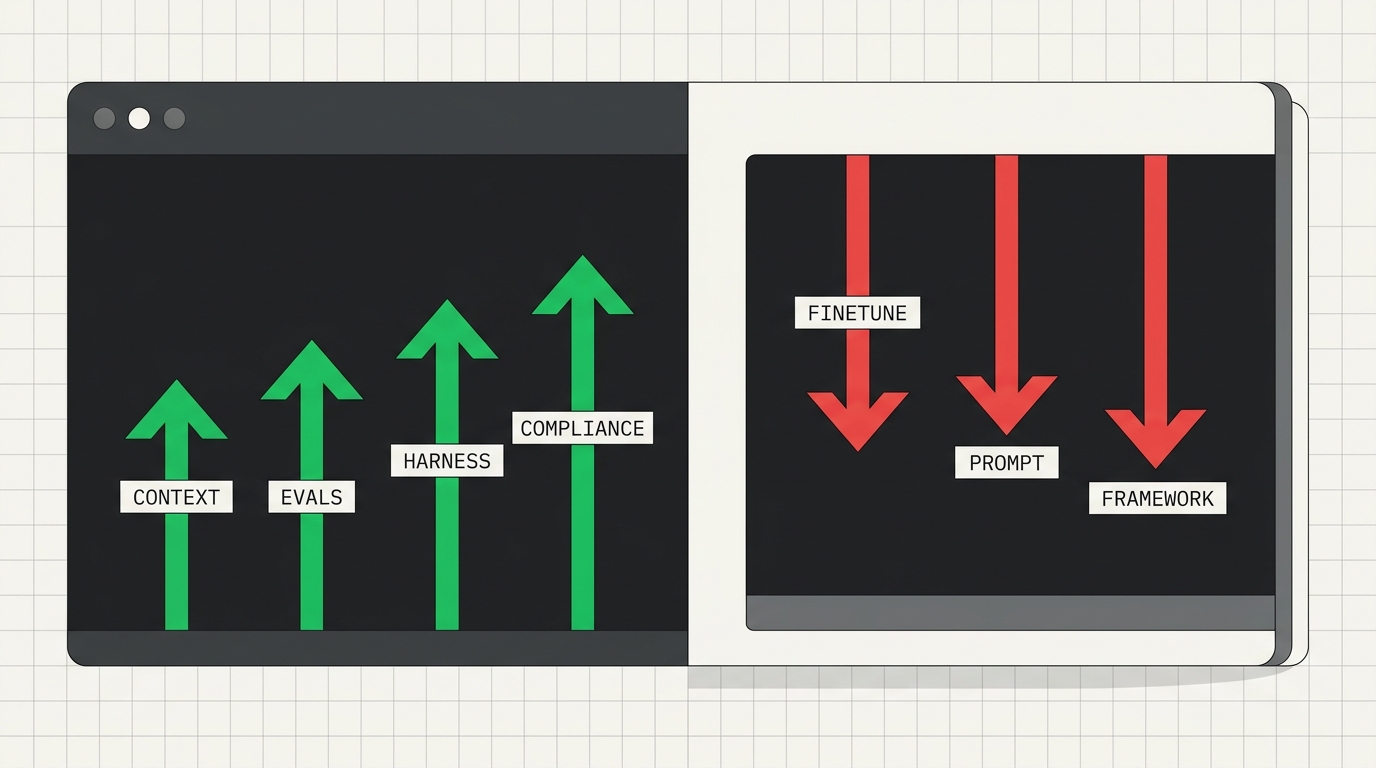
AI engineer no 2º semestre de 2026: o que o recrutador vai pedir
Li 200 vagas de AI engineer postadas em maio de 2026 e separei sinal de ruído: quatro skills que sobem (context engineering, evals, harness e compliance), três que perdem peso e um roteiro de 90 dias pra entrar na shortlist do segundo semestre.

Prontidão para IA: como deixar sua empresa pronta de verdade
Comprar licença de IA não deixa a empresa pronta pra IA. Um framework de prontidão para IA em quatro frentes — dados, processos, pessoas e governança — com os números que mostram onde a maioria trava.
Vibe coding: o que é, por que todo dev fala disso e onde ele quebra
Vibe coding — construir software conversando com a IA sem revisar o código — é o termo do momento. Veja o que é de verdade, onde acelera e onde vira dívida técnica silenciosa.
