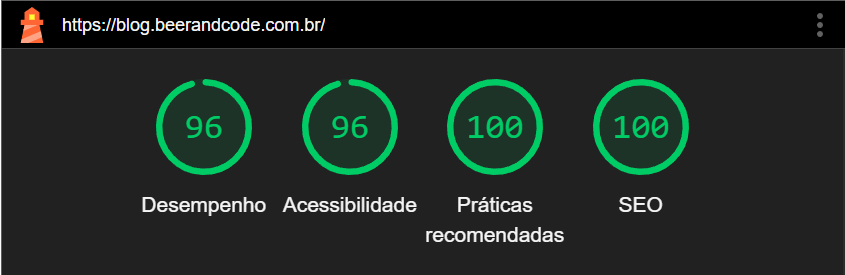
Otimize sua aplicação Laravel com o novo Memoized Cache Driver (Laravel 12.9)
O Laravel 12.9 trouxe uma novidade poderosa: o Memoized Cache Driver. Essa feature otimiza o desempenho das aplicações ao armazenar em memória os valores obtidos do cache durante o tempo de execução da requisição, evitando múltiplos acessos ao cache.