Sakana Fugu: o modelo que rege Fable 5 e Mythos sem treinar nenhum frontier
Tem uma pergunta incômoda que todo time que constrói com IA evita fazer em voz alta: e se o modelo que você usa hoje sumir amanhã?
Não por falência. Por export control. Por mudança de política. Por um contrato que muda de cláusula no meio do ano. Quando a sua arquitetura inteira depende de um único endpoint de um único laboratório, você não tem um produto — tem um refém.
A Sakana AI, de Tóquio, acabou de lançar o Sakana Fugu como resposta para isso. E a resposta não é mais um modelo de fronteira. É um maestro.
TL;DR
- O que é: o Sakana Fugu — um LLM treinado para orquestrar um pool de outros modelos (chamar, delegar, verificar e sintetizar) atrás de uma única API compatível com OpenAI.
- Modelos:
fugu(baixa latência, padrão do dia a dia) efugu-ultra(qualidade máxima, pool profundo, contexto até 272K tokens). - Custo/Acesso: planos Standard US$ 20 / Pro US$ 100 / Max US$ 200; pay-as-you-go com
fugu-ultraa US$ 5 input / US$ 30 output por 1M tokens. - Link útil: anúncio oficial do Fugu.
O contexto: o Sakana Fugu fez a orquestração virar produto
Até ontem, "orquestração de modelos" era coisa que você montava na mão. Um roteador em LangGraph, um if-else decidindo se manda pro modelo barato ou pro caro, um verificador colado na saída. Cola, fita e muita gambiarra de produção.
O Sakana Fugu, lançado comercialmente em 22 de junho de 2026 depois de um beta que abriu em abril, vira isso de cabeça pra baixo. A orquestração deixou de ser um fluxo que você escreve e virou um modelo que você chama.
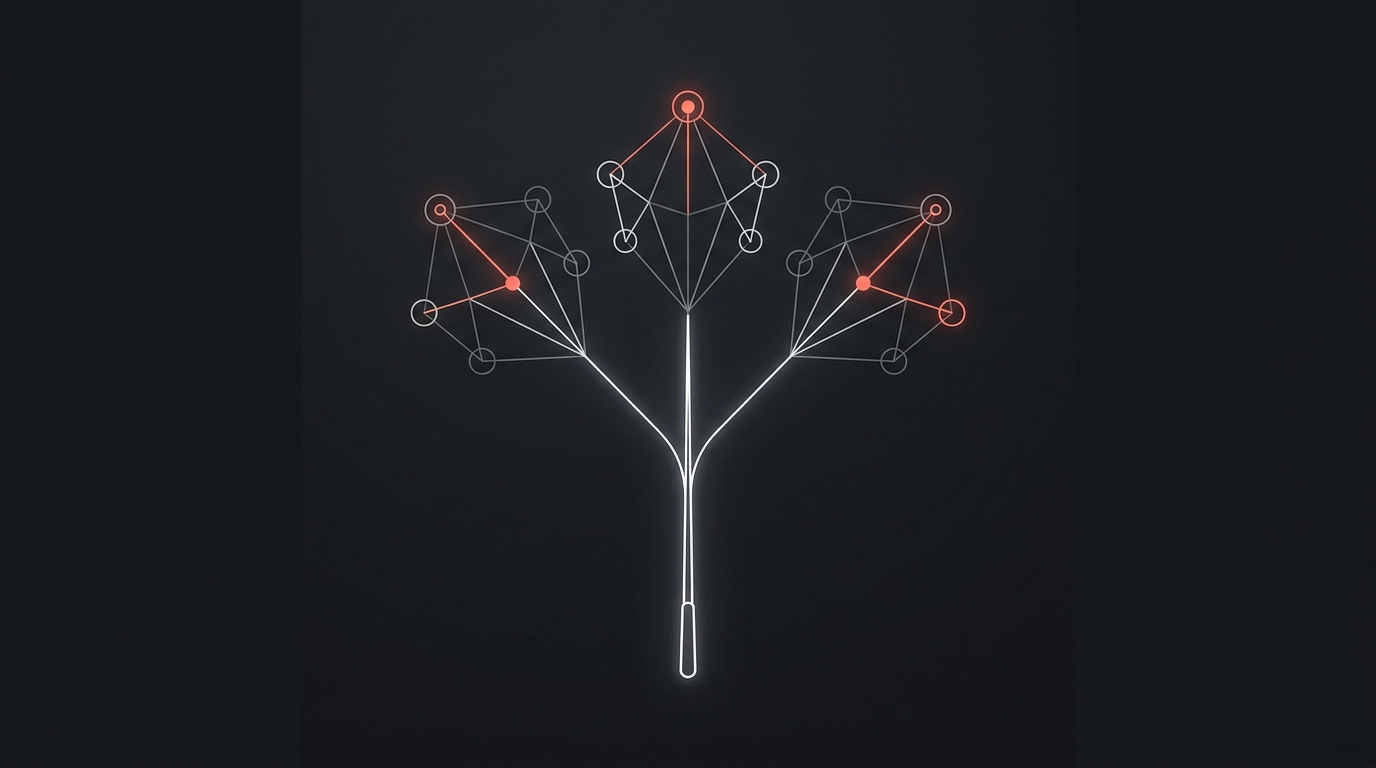
Funciona assim: o Fugu é, ele próprio, um modelo de linguagem. Mas em vez de só gerar a resposta, ele foi treinado para decidir quem responde. Recebe a sua requisição num único endpoint e, internamente, escolhe o modelo, delega o trabalho, verifica o resultado e sintetiza a resposta final. Da sua cadeira, é uma chamada só. Por baixo, é um time inteiro de modelos especializados trabalhando junto.
A Sakana descreve isso como atribuir papéis de Thinker, Worker e Verifier — pensador, executor e verificador — e delegar de forma adaptativa conforme a tarefa. Se isso soa familiar, é porque é: são os mesmos três padrões de multi-agent que a gente já testou em produção — Orchestrator, Hierarchical, Swarm. A Sakana só treinou tudo isso pra dentro de um modelo só. Não é workflow chumbado. É coordenação aprendida, em cima de dois papers que eles apresentaram no ICLR 2026: o TRINITY (um coordenador evoluído pra reger múltiplos LLMs) e o Conductor (que aprende estratégias de coordenação em linguagem natural via RL).
Presta atenção nisso porque muda o jogo: o Fugu não foi treinado pra ser melhor que o GPT-5.5 num benchmark. Foi treinado pra saber quando chamar o GPT-5.5.
Os números — e a parte que dói
Aqui entra a provocação que a Sakana plantou de propósito. Olha os benchmarks do fugu-ultra, segundo o the-decoder:
| Benchmark | Fugu Ultra | Opus 4.8 | GPT-5.5 | Gemini 3.1 |
|---|---|---|---|---|
| SWE-Bench Pro | 73,7 | 69,2 | 58,6 | 54,2 |
| LiveCodeBench | 93,2 | 87,8 | 85,3 | 88,5 |
| GPQA-D | 95,5 | 92,0 | 93,6 | 94,3 |
E a Sakana afirma que o Fugu Ultra fica "ombro a ombro" com o Fable 5 e o Mythos Preview da Anthropic nos testes mais duros de engenharia e raciocínio. O detalhe que faz a frase morder: nem o Fable 5 nem o Mythos estão no pool do Fugu — porque não são publicamente acessíveis. Ele iguala dois modelos de fronteira sem ter nenhum dos dois na equipe.
Como? Coordenando bem modelos que você consegue chamar. É a tese central do produto: a capacidade de fronteira não precisa morar num único pesão treinado por um único lab. Ela pode emergir da forma como você rege modelos médios.
Nos testes de código, beta testers (uns 500) relataram que o Fugu Ultra apontou mais de vinte problemas num review onde outras ferramentas flagavam três. Faz sentido — um verificador dedicado, olhando a saída de um executor, pega o que um modelo único, gerando de uma vez só, deixa passar.
O pitch real: "frontier sem o risco de export control"
A jogada de marketing é cirúrgica. O slogan é "capacidade de fronteira sem o risco de export controls".
Traduzindo pra dor de quem constrói: o pool do Fugu é swappable. Se um provedor restringe acesso amanhã — por sanção, por política, por preço —, o Fugu rerota para outro modelo do pool e a sua aplicação nem percebe. Você pode até tirar agentes específicos do pool por privacidade ou compliance, sem trocar uma linha do seu código, porque o endpoint é o mesmo: Chat Completions, padrão OpenAI.
A Sakana cita explicitamente as restrições recentes sobre os modelos da Anthropic como o cenário que o Fugu resolve. "Acesso aos melhores sistemas de IA pode sumir da noite pro dia por mudança regulatória ou decisão de política externa", diz o argumento. Para um time no Japão — ou no Brasil —, essa não é uma preocupação abstrata. É arquitetura de sobrevivência.
Isso aqui não é hype. É engenharia de risco de fornecedor virando feature de produto.
O que isso ensina sobre construir agents
Tira o nome "Sakana" da frase por um segundo e olha o padrão. O Fugu é a prova comercial de uma ideia que a gente já vinha martelando: o próximo salto não é um modelo maior, é uma arquitetura de orquestração melhor.
Pensa no que o Fugu faz e no que você faz quando constrói um agente sério de produção:
- Roteamento — qual modelo (ou ferramenta) responde a esta tarefa?
- Delegação — quebrar o problema e mandar cada pedaço pra quem resolve melhor.
- Verificação — um passo dedicado que checa a saída antes de ela virar resposta final.
- Síntese — juntar tudo numa resposta única e coerente.
É exatamente o esqueleto de qualquer harness de agente que aguenta produção. A diferença é que a Sakana embutiu esse esqueleto dentro de um modelo e vende como API. Você, construindo o seu agente de verdade, monta esse harness com as mãos — e é aí que mora o aprendizado, porque entender Thinker/Worker/Verifier na unha é o que te deixa decidir quando comprar a abstração pronta e quando construir a sua.
Esse é exatamente o terreno que a gente percorre no Do Prompt ao Harness: construindo um Agent de Vendas, um workshop hands-on do AI Engineering LAB onde você sai do prompt solto e chega num agente de vendas montado de ponta a ponta — roteamento, delegação e verificação no harness de produção, não no slide.
Limitações e pontos de atenção
Antes de trocar o seu endpoint, respira.
- Latência e custo do
fugu-ultra. Coordenar um pool de modelos significa múltiplas chamadas por requisição. Qualidade alta tem preço: US$ 5 input / US$ 30 output por 1M tokens, e a faixa muda acima de 272K de contexto. Pra tarefa simples, é canhão em mosquito — pra isso existe ofuguleve. - Você terceiriza a decisão de roteamento. A orquestração é aprendida e fica numa caixa que você não controla fino. Ótimo pra velocidade, ruim quando você precisa saber exatamente qual modelo viu qual dado — o que importa muito em compliance.
- Benchmark é da casa. Os números vêm da própria Sakana. Ombro a ombro com Fable 5 e Mythos é uma afirmação forte que ninguém auditou de forma independente ainda. Trate como hipótese promissora, não como fato fechado.
FAQ rápido
Dá pra plugar no meu código que já usa OpenAI? Sim. A API é compatível com o formato Chat Completions. Você aponta o cliente existente pro endpoint do Fugu com a sua chave e roda. Foi desenhado pra ser swap de uma linha.
fugu e fugu-ultra são modelos diferentes?
São dois modos do mesmo sistema. O fugu (que se chamava fugu-mini no beta) prioriza latência pro dia a dia — chatbot, review rápido. O fugu-ultra aciona o pool profundo pra problemas duros e multi-step.
O Fable 5 ou o Mythos estão no pool? Não. Nenhum dos dois é publicamente acessível, então o Fugu não consegue chamá-los. A graça é justamente igualar o benchmark deles sem tê-los na equipe.
Conclusão
O Fugu não é "mais um modelo". É um sinal. A camada onde a competição estava — treinar o maior pesão — está sendo flanqueada por uma camada nova: reger bem os modelos que já existem.
Pra quem constrói produto, a lição é direta. Saber chamar uma API de orquestração é commodity. Saber desenhar a orquestração — quando rotear, o que verificar, como sintetizar, onde cortar custo — é o que separa o agente de demo do agente que aguenta cliente real.
O Fugu provou que isso vale como produto de fronteira. Agora a pergunta volta pra você: o seu próximo agente vai ser um prompt grande torcendo pra dar certo, ou um harness que sabe reger?
Fontes: Sakana AI — Fugu · the-decoder.

{AI Engineer} — apaixonado por Laravel, arquitetura de software e construir produtos com impacto. Compartilho aqui tutoriais, descobertas e reflexões sobre o dia a dia de engenharia.
Você também pode gostar
Fable 5 bloqueado: o OpenRouter Fusion prova que painel de modelos já supera qualquer frontier
O Claude Fable 5 durou três dias disponível antes de ser bloqueado pelo governo dos EUA. Enquanto isso, o OpenRouter publicou dados que mudam a pergunta: e se painel de modelos baratos já superar qualquer frontier solo em deep research?
Engenheiro de IA em 2026: o que faz, e por que não é só usar ChatGPT no trabalho
Em 2024 era cargo inventado pelo LinkedIn. Em 2026 é o sênior mais disputado dos EUA. O que faz um Engenheiro de IA na prática: as 5 entregas em qualquer JD sênior, o stack típico (LLM API, harness, vector store, evals, observability) e por que a maioria veio de backend, não de Data Science.

Como implementar Agent Builder e Chatkit da OpenAi com Laravel
A OpenAI lançou o Agent Kit, um pacote que une o poder do Agent Builder e do Chat Kit para simplificar a criação de agentes inteligentes em qualquer aplicação web.

Claude Fable 5: 10 coisas que o Opus 4.8 não fazia bem
A Anthropic liberou o Claude Fable 5, primeiro modelo da classe Mythos para uso geral. Veja 10 tarefas reais que ele resolve e que o Opus 4.8 fazia mal ou não fazia.
