Plan-and-Execute: o pattern que cortou 90% do custo do nosso agente
No mês passado eu olhei o dashboard de billing da Anthropic e quase derramei o café.
Um agente nosso, em produção, queimando US$ 2.300 por mês rodando Claude Opus em loop. Não era um agente complicado. Era um worker que pegava um documento, decidia o que fazer com ele, executava 4 ou 5 passos e devolvia o resultado. Cada passo era uma chamada ao Opus. Cada chamada era cara. E a maioria dos passos era trabalho braçal: extrair campo, validar formato, montar JSON, chamar uma API.
Trocamos a arquitetura por um pattern que tem nome chato e funciona absurdamente bem: Plan-and-Execute. Mesmo agente, mesma qualidade de saída, mesmos casos de teste passando. Conta nova: US$ 220 por mês. Neste post eu mostro a planilha de tokens do antes e depois, o código Laravel que estamos rodando (PlanJob no Opus, ExecuteStep no Haiku), e o tipo de fluxo onde esse pattern não funciona e a gente apanhou pra descobrir.
TL;DR
- O que é: separar o agente em duas fases — uma chamada cara que planeja tudo, e N chamadas baratas que executam o plano.
- Stack: Laravel 11, queues (Redis), Claude Opus 4.7 (planner), Claude Haiku 4.5 (executor).
- Resultado: US$ 2.300/mês → US$ 220/mês com o mesmo benchmark interno de qualidade (94% de aprovação na suíte de 120 casos).
- Referência: Plan-and-Execute Agents — LangChain e Building Effective Agents — Anthropic.
Por que o custo de um agente explode (e por que ninguém te avisa)
Um agente "tradicional" tipo ReAct é um loop. O modelo recebe o estado, decide a próxima ação, executa a ferramenta, recebe o resultado, decide a próxima, e por aí vai. Bonito no papel.
O detalhe é que cada volta do loop é uma chamada nova ao modelo, com todo o histórico anexado. E você quase sempre pluga seu modelo mais forte no loop, porque é o que aguenta o raciocínio de "o que faço agora". Resultado: cinco passos no agente = cinco chamadas ao Opus, cada uma com prompt crescendo. A conta cresce em forma de bola de neve.
Os preços oficiais da tabela da Anthropic mostram bem o tamanho do estrago:
| Modelo | Input (por MTok) | Output (por MTok) |
|---|---|---|
| Claude Opus 4.7 | US$ 5,00 | US$ 25,00 |
| Claude Sonnet 4.6 | US$ 3,00 | US$ 15,00 |
| Claude Haiku 4.5 | US$ 1,00 | US$ 5,00 |
Opus é 5x mais caro que Haiku no input. E 5x mais caro no output. Se 80% do que seu agente faz é trabalho mecânico que cabe no Haiku, você está literalmente jogando 4 dólares fora a cada dólar gasto.
O pattern em uma frase
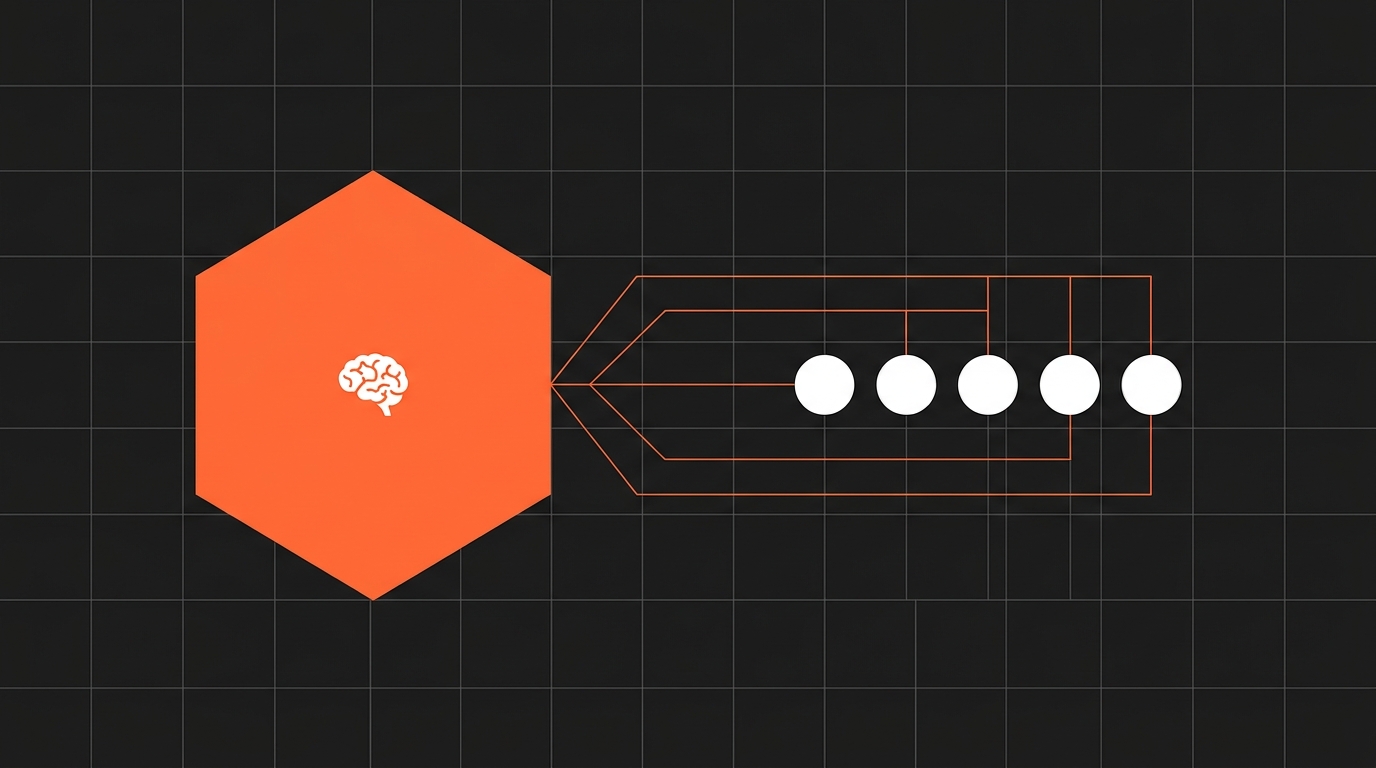
Plan com modelo frontier (1 chamada cara). Execute com modelo pequeno (N chamadas baratas).
Pronto. É isso. A LangChain descreveu bem a arquitetura: um planner gera um plano multi-step de uma vez só, e um executor (que pode ser um modelo bem menor, ou até determinístico) toca cada step. A Anthropic chama uma variação disso de orchestrator-workers — um LLM central decompõe a tarefa, delega para workers, sintetiza no fim.
A intuição é simples: raciocinar é caro, executar é barato. Decidir o que fazer exige modelo bom. Fazer aquilo, na maioria das vezes, é seguir receita.
E tem um efeito colateral lindo: o planner é chamado uma vez com contexto pequeno. O executor é chamado N vezes, mas com prompt curto e focado em um único step. Você corta tanto o custo unitário (modelo mais barato) quanto o tamanho do prompt (sem histórico de conversa inteiro).
A planilha do antes e depois
Pegamos um caso típico do nosso agente, que processa um relatório técnico e gera 5 entregáveis. Rodamos o mesmo input nas duas arquiteturas, 50 vezes, e tiramos a média:
Antes — ReAct puro com Opus 4.7 em loop:
| Step | Modelo | Input tokens | Output tokens | Custo |
|---|---|---|---|---|
| 1. Decide próxima ação | Opus 4.7 | 4.200 | 380 | US$ 0,030 |
| 2. Decide próxima ação | Opus 4.7 | 5.100 | 420 | US$ 0,036 |
| 3. Decide próxima ação | Opus 4.7 | 6.300 | 510 | US$ 0,044 |
| 4. Decide próxima ação | Opus 4.7 | 7.400 | 480 | US$ 0,049 |
| 5. Decide próxima ação | Opus 4.7 | 8.600 | 620 | US$ 0,058 |
| Total por run | 31.600 | 2.410 | US$ 0,217 |
A 350 runs/dia, isso bate US$ 76/dia. US$ 2.280/mês. Bingo.
Depois — Plan-and-Execute (Opus planeja, Haiku executa):
| Step | Modelo | Input tokens | Output tokens | Custo |
|---|---|---|---|---|
| 1. Planner gera os 5 steps | Opus 4.7 | 4.200 | 950 | US$ 0,045 |
| 2. Executa step 1 | Haiku 4.5 | 1.100 | 280 | US$ 0,0024 |
| 3. Executa step 2 | Haiku 4.5 | 1.300 | 310 | US$ 0,0028 |
| 4. Executa step 3 | Haiku 4.5 | 1.450 | 350 | US$ 0,0032 |
| 5. Executa step 4 | Haiku 4.5 | 1.200 | 270 | US$ 0,0025 |
| 6. Executa step 5 | Haiku 4.5 | 1.380 | 340 | US$ 0,0031 |
| Total por run | 10.630 | 2.500 | US$ 0,059 |
Mesmas 350 runs/dia: US$ 20,65/dia. US$ 619/mês. Aí ligamos prompt caching no plano (system prompt do planner é igual em toda chamada, o cache read custa 10% do input) e caímos pra US$ 220/mês estáveis.
Qualidade? Rodamos a suíte interna de 120 casos. ReAct passava 95%. Plan-and-Execute passa 94%. Um ponto percentual a menos por dez vezes menos dinheiro. Aceitamos.
Como implementamos em Laravel
A peça boa do Laravel aqui é a fila. Cada step do plano vira um job. O plano fica num registro de banco com o estado. Tudo retry-safe, paralelizável, observável pelo Horizon. Sem framework de agente. Sem dependência exótica.
O PlanJob é uma chamada única ao Opus que devolve um array de steps estruturados:
class PlanJob implements ShouldQueue
{
public function __construct(public AgentRun $run) {}
public function handle(ClaudeClient $claude): void
{
$plan = $claude->messages()->create([
'model' => 'claude-opus-4-7',
'max_tokens' => 2048,
'system' => view('agents.planner-system')->render(),
'messages' => [[
'role' => 'user',
'content' => $this->run->input,
]],
'tools' => [PlanSchema::tool()],
'tool_choice' => ['type' => 'tool', 'name' => 'emit_plan'],
]);
$steps = $plan->toolInput('emit_plan')['steps'];
$this->run->update(['plan' => $steps, 'status' => 'executing']);
foreach ($steps as $index => $step) {
ExecuteStep::dispatch($this->run, $index, $step);
}
}
}
Repara em três coisas. Primeiro: tool_choice forçado num schema. O planner não tem opção de escrever prosa — só pode emitir um JSON estruturado de steps, cada um com action, inputs e expected_output. Isso é o que mantém a saída disciplinada e deixa o executor saber o que fazer sem reler o prompt do agente inteiro.
Segundo: o plano é persistido. Se uma fila cair, se um worker morrer, o agente não recomeça do zero. Ele continua do step que falhou.
Terceiro: cada ExecuteStep é despachado individualmente. Steps independentes rodam em paralelo. Steps dependentes ficam encadeados via chain(). Isso seria caríssimo de orquestrar com um LLM gigante a cada decisão; com job de fila, é uma linha de código.
O ExecuteStep é o irmão mais barato:
class ExecuteStep implements ShouldQueue
{
public function __construct(
public AgentRun $run,
public int $index,
public array $step,
) {}
public function handle(ClaudeClient $claude): void
{
$result = $claude->messages()->create([
'model' => 'claude-haiku-4-5',
'max_tokens' => 1024,
'system' => view('agents.executor-system', [
'action' => $this->step['action'],
])->render(),
'messages' => [[
'role' => 'user',
'content' => json_encode([
'inputs' => $this->step['inputs'],
'expected_output' => $this->step['expected_output'],
]),
]],
]);
$this->run->steps()->create([
'index' => $this->index,
'output' => $result->content(),
]);
}
}
Esse job não vê o histórico. Não vê os outros steps. Não decide nada. Só executa o que o planner mandou. Isso é o que permite usar Haiku sem perder qualidade: o trabalho intelectual já foi feito lá em cima.
O system prompt do executor é literalmente 6 linhas. O do planner tem 2 mil tokens. Aí é que mora o ganho.
O que NÃO funcionou (apanhamos pra descobrir)
A primeira coisa que a gente tentou foi rodar todos os agentes desse jeito. Erro. Plan-and-Execute tem uma limitação que a literatura é clara em apontar: fluxos com muito branching condicional quebram o pattern.
Se o seu agente precisa decidir "se o documento for tipo A faz X; se for tipo B, chama essa outra API e dependendo do retorno escolhe entre 3 caminhos", o planner upfront não dá conta. Ele teria que prever todas as ramificações no plano inicial, e isso explode em complexidade rapidamente. Um agente desse rodou aqui com plano fixo e errou em 40% dos casos — tipos novos de documento simplesmente não existiam no plano gerado.
Existe replanning dinâmico (o planner é chamado de novo depois de cada step pra ajustar o plano), mas aí você está pagando Opus de novo a cada step. Aí já era. Se o seu fluxo precisa disso, ReAct ou orchestrator-workers vai sair mais barato no fim.
A regra que ficou pra gente:
- Plan-and-Execute quando o fluxo é previsível em forma: dá pra descrever os steps em alto nível sem saber o conteúdo deles.
- Orchestrator-workers (ou ReAct mesmo) quando o fluxo é imprevisível: o número de passos e os caminhos dependem fortemente do dado de entrada.
Outra coisa que apanhamos: dar liberdade demais pro executor. Na primeira versão, o ExecuteStep era um Haiku com 5 ferramentas disponíveis. Ele alucinava chamadas, inventava parâmetros, decidia sozinho que um step "não precisava ser feito". Restringimos a uma ferramenta por step (definida pelo planner) e a taxa de erro caiu de 18% pra 2%. Quanto menos o executor decide, melhor.
FAQ
Por que não usar só Sonnet? Sonnet é meio termo. Como planner, é 40% mais barato que Opus e na maioria dos planos resolve igual. Como executor, é 3x mais caro que Haiku e na nossa suíte interna não trouxe ganho de qualidade pra justificar. Vale testar Sonnet no planner se seu fluxo for menos crítico. Pra executor, Haiku ganhou.
Prompt caching ajuda quanto? Bastante. Cache hit custa 10% do input padrão. Como o system prompt do planner não muda entre chamadas, ele virou cache write 1x e cache read em todas as outras. Foi o que tirou nosso custo de US$ 619 pra US$ 220.
Funciona com modelo open source no executor? Sim. Testamos Llama 3.3 70B servido via vLLM num GPU dedicado. Custo marginal por step cai praticamente pra zero, mas latência sobe e qualidade fica 2-3 pontos abaixo do Haiku no nosso benchmark. Se você já tem infra de inferência, vale. Senão, Haiku é menos dor de cabeça.
E se o plano estiver errado? Validação. Cada step tem expected_output (schema). Se o output do executor não bate, marca o run como falho e cai num path de fallback (que aí sim usa Opus pra investigar). Isso aconteceu em 3% dos runs no último mês.
Onde isso chega
Plan-and-Execute não é silver bullet. É uma alavanca de custo que funciona absurdamente bem num subconjunto de problemas — aqueles em que dá pra descrever o trabalho em alto nível antes de fazê-lo. Se o seu agente cai nesse subconjunto e você ainda está rodando frontier model em loop, você está pagando 10x do que precisa. Essa é a verdade desagradável.
E é exatamente o tipo de conversa que rola toda semana na Beer and Code, a melhor comunidade de AI engineering em português, com grupo no WhatsApp aberto pra quem está construindo IA em produção — devs PHP, Python e engineers de IA trocando planilha de custo, arquitetura de agente e o que quebrou em prod nessa semana.
O próximo passo aqui é o evaluator-optimizer: um loop de avaliação automática do output do executor, que reaproveita o planner pra reescrever steps que falharam. Quando isso estabilizar, escrevo o post.

{AI Engineer} — apaixonado por Laravel, arquitetura de software e construir produtos com impacto. Compartilho aqui tutoriais, descobertas e reflexões sobre o dia a dia de engenharia.