OpenAI Daybreak: o GPT-5.5-Cyber que caça e corrige vulnerabilidades sozinho

A OpenAI soltou um modelo que promete achar e corrigir bugs de segurança antes de você. A pergunta que importa pro dev não é se a demo impressiona. É se isso vira ferramenta de defensor de verdade ou só mais uma camada de "achados" que você vai ter que revisar na mão.
No dia 22 de junho de 2026, o OpenAI Daybreak — o programa de cibersegurança da empresa — ganhou sua peça central: a OpenAI liberou a versão final do GPT-5.5-Cyber, um modelo treinado pra encontrar, validar e remendar vulnerabilidades de software num fluxo automatizado. É um lançamento não-Anthropic que vale entender, porque mexe direto no dia a dia de quem escreve e mantém código.
Neste post você vai entender o que o OpenAI Daybreak faz na prática, onde o GPT-5.5-Cyber encaixa no fluxo de um dev e até onde dá pra confiar correção de vulnerabilidade entregue por um modelo.
TL;DR
- O que é: GPT-5.5-Cyber, modelo de cibersegurança da OpenAI dentro do programa Daybreak, focado em achar, validar e corrigir vulnerabilidades.
- Stack/Modelos: GPT-5.5-Cyber (acesso restrito), Codex Security (varredura de repositórios), iniciativa Patch the Planet para open source.
- Custo/Acesso: acesso limitado a "verified defenders" — trabalho de segurança autorizado, com verificação e monitoramento. Não é API aberta pra qualquer conta.
- Link útil: anúncio oficial do Daybreak.
O contexto: o que é o OpenAI Daybreak e por que isso importa
O argumento central da OpenAI é uma frase que merece atenção: a IA virou a chave da segurança. A parte difícil deixou de ser achar a falha e passou a ser corrigir (OpenAI).
Faz sentido. Quem trabalha com segurança sabe que scanner que cospe vulnerabilidade é commodity há anos. O gargalo sempre foi outro: triar o que é real, entender o caminho de exploração, escrever o patch sem quebrar o resto e provar que a correção fechou o buraco. É aí que o GPT-5.5-Cyber se posiciona.
Em vez de só apontar "tem um problema na linha 312", o modelo se propõe a rodar o ciclo inteiro num fluxo automatizado: navega por uma base de código grande, traça o caminho de ataque, valida se a falha é de fato explorável, gera um patch direcionado e produz a evidência de remediação — tudo dentro do mesmo workflow (Infosecurity).
Os números do anúncio sustentam a evolução. Em benchmarks de cibersegurança, o GPT-5.5-Cyber bateu o GPT-5.5 padrão (cybersecuritynews):
- CyberGym (reproduzir vulnerabilidades conhecidas): 85,6% contra 81,8% do GPT-5.5 — o maior placar de modelo único registrado no teste.
- ExploitGym (gerar exploit a partir de falha conhecida): 39,5% contra 25,95%.
- SEC-bench Pro (descoberta de vulnerabilidade de horizonte longo): 69,8% contra 63,1%.
Repara num detalhe que o blog gosta de cutucar: 85,6% num benchmark de reprodução é forte. 39,5% em geração de exploit é... 39,5%. O modelo é bom, não é mágico. Guarda esse número, porque ele volta lá embaixo.
Onde o GPT-5.5-Cyber entra no fluxo de um dev
Aqui vale separar as três peças do Daybreak, porque elas atingem públicos diferentes.
A primeira é o Codex Security, a varredura de repositórios. Desde o preview em março, a OpenAI diz ter escaneado mais de 30 milhões de commits em 30 mil bases de código e registrado mais de 500 mil achados como corrigidos (Infosecurity). Esse é o número que parece com a sua realidade: o modelo passando o pente fino em repositório de verdade, em escala.
A segunda é o Patch the Planet, iniciativa feita com a Trail of Bits e outros pra apontar essas ferramentas pro código aberto. Mais de 30 projetos já entraram, incluindo nomes que provavelmente estão na sua árvore de dependências agora: cURL, Go e Python (developer-tech). Se você usa essas libs — e usa —, o efeito de segunda ordem te alcança mesmo sem você tocar no Daybreak.
A terceira é o acesso ao modelo em si, e é a mais restrita. O GPT-5.5-Cyber não é uma chave de API que você pega na dashboard. A OpenAI descreve o modelo como mais capaz e mais "permissivo" que os modelos gerais pra trabalho de segurança autorizado — e por isso liberou só pra defensores verificados, com monitoramento e controles de escopo (Infosecurity). Tem ainda um programa de parceiros, com fabricantes como CrowdStrike, Sophos e Fortinet, pra embutir o modelo nos produtos deles.
Traduzindo pro seu fluxo: no curto prazo, o GPT-5.5-Cyber chega até você embalado — dentro da ferramenta de segurança que a empresa já paga, ou na forma de um PR de correção num projeto open source que você consome. É o mesmo movimento de agente autônomo perseguindo um objetivo que a gente já destrinchou em como usar goals para guiar o Codex CLI, só que mirado em segurança. Não é você abrindo um chat e pedindo "audita meu microsserviço". Pelo menos não ainda.
Limitações e pontos de atenção
Esta é a parte que o material de marketing não destaca. E é exatamente onde você decide se confia ou não.
O problema é o velho conhecido de qualquer ferramenta de segurança automatizada: falso positivo. Modelos de fronteira geram um volume alto de falsos positivos em varredura de rotina. E o anúncio da OpenAI não informa a taxa de falso-positivo, nem a proporção de patches que os desenvolvedores realmente aceitaram, nem uma comparação direta com as ferramentas comerciais que já existem (developer-tech). São justamente os números que decidiriam se isso economiza ou cria trabalho.
A própria OpenAI admite o limite no desenho do pipeline: o sistema deduplica resultados, filtra prováveis falsos positivos e roteia as evidências mais fortes pra um engenheiro de segurança confirmar na mão. Ou seja: a revisão humana não é um detalhe, é parte do produto. O modelo não fecha o ciclo sozinho — ele entrega um candidato bem argumentado, e alguém com crachá precisa apertar o botão.
E tem a questão que ninguém deveria ignorar: dual-use. Um modelo que é ótimo em achar e explorar vulnerabilidade é, por definição, perigoso na mão errada. A mesma capacidade que ajuda o defensor serve pro atacante. É por isso que o acesso é fechado, verificado e monitorado — não é zelo de advogado, é a natureza da coisa.
A leitura honesta é essa: o GPT-5.5-Cyber é um avançado assistente de triagem e remediação, não um piloto automático de segurança. Aquele 39,5% em geração de exploit lá de cima é o lembrete numérico de que confiar a correção de uma vulnerabilidade crítica a um modelo, sem revisão, é trocar um risco por outro.
FAQ rápido
Posso usar o GPT-5.5-Cyber na minha conta da OpenAI hoje? Não diretamente. O acesso é restrito a defensores verificados, com trabalho de segurança autorizado, verificação e monitoramento. O caminho mais provável de chegar até você é via uma ferramenta parceira (CrowdStrike, Sophos, Fortinet) ou pelo Codex Security.
Ele substitui o pentester ou o time de AppSec? Não. O próprio pipeline da OpenAI roteia os achados mais fortes pra confirmação humana. Pense nele como quem faz a triagem pesada e propõe o patch — a decisão e a validação continuam com gente.
Isso afeta quem só escreve código de aplicação, não de segurança? Afeta, de forma indireta. Com o Patch the Planet mirando cURL, Go, Python e outros 30+ projetos, as correções tendem a chegar nas suas dependências. Vale acompanhar os PRs gerados por IA nas libs que você usa.
Os patches gerados são confiáveis? São candidatos. A OpenAI não publicou taxa de aceitação dos patches nem de falso-positivo, então trate todo patch automático como qualquer PR de terceiro: leia, teste, revise. Não dê merge no escuro só porque "a IA achou".
Conclusão
O OpenAI Daybreak e o GPT-5.5-Cyber são um passo real, não só hype. A tese de que a IA inverteu a economia da segurança — do achar pro corrigir — é boa, e os benchmarks mostram capacidade genuína. Mas o produto inteiro foi desenhado em torno de revisão humana e acesso fechado, e isso não é acaso: é o reconhecimento de que correção de vulnerabilidade ainda não é coisa pra deixar no automático.
Pro dev, a postura certa não é nem terror nem deslumbre. É a mesma de sempre com ferramenta poderosa: entender o que ela faz, onde ela falha e como ela encaixa no seu fluxo sem virar mais uma fila de alertas pra ignorar. O próximo passo dessa tecnologia será fechar mais o ciclo — e o dia em que o modelo realmente fizer merge sozinho é o dia em que essa conversa sobre confiança fica séria de verdade.
E é exatamente esse desenho — modelo capaz na frente, harness e revisão segurando a barra atrás — que separa demo de produto. Se você quer ver isso na prática, construindo um agente de ponta a ponta com as suas próprias mãos, é o que a gente vai fazer no workshop Do Prompt ao Harness: construindo um Agent de Vendas, do AI Engineering LAB.

{AI Engineer} — apaixonado por Laravel, arquitetura de software e construir produtos com impacto. Compartilho aqui tutoriais, descobertas e reflexões sobre o dia a dia de engenharia.
Você também pode gostar
GPT 5.6: data de lançamento, vazamentos e tudo o que já sabemos (rastreador)
Rastreador de pré-lançamento do GPT 5.6. O único fato verificado (a string nos logs do Codex), a aposta do Polymarket e os rumores de spec, separando fato de boato.

GPT-5 na prática: vale trocar o que você já usa pra programar?
GPT-5 está em todo lugar, mas a pergunta de quem programa é só uma: vale trocar o que já funciona? Olhamos código real, custo por tarefa e quando a troca se paga, no tom honesto da marca.
Prompt injection no agente: quando o site raspado vira o novo system prompt
Seu agente lê o HTML de uma página de produto. Lê também as instruções escondidas que mandam ele ignorar o usuário e recomendar um link específico. Esse vetor já está sendo explorado em produção. Veja como funciona e o que o harness precisa fazer antes de injetar conteúdo externo no contexto do LLM.
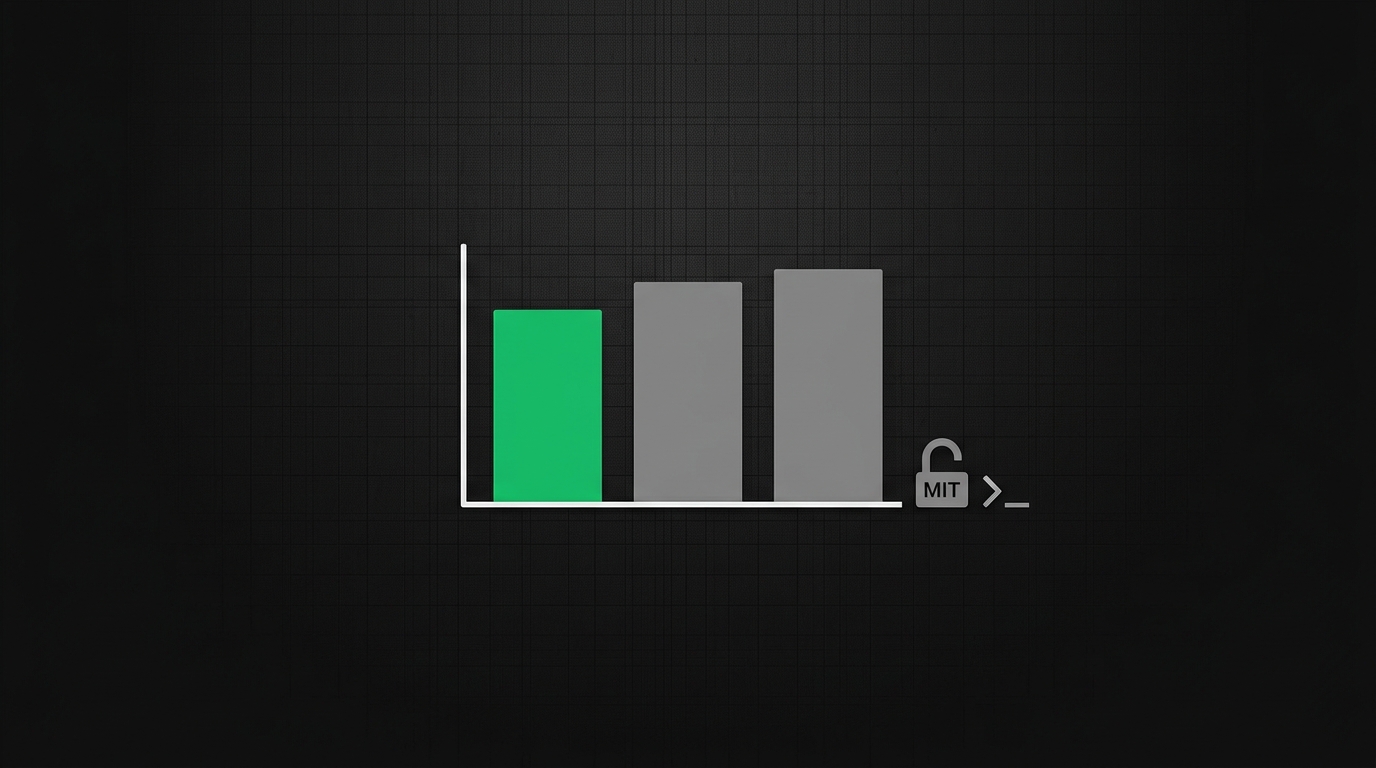
GLM 5.2: o melhor modelo de código open source é chinês, MIT e 6x mais barato
A Z.ai (ex-Zhipu) lançou o GLM 5.2, modelo open-weight de 753B sob licença MIT que fica a 0,7 ponto do Claude Opus 4.8 em código e custa um sexto do preço por token. O que muda pra quem programa com IA no Brasil — incluindo rodar self-host.
