Claude Code e malware: como um repositório "limpo" engana seu agente de código (e como blindar o setup)

Seu agente de código confia em tudo que lê no repositório. README, mensagem de erro, instrução de setup — pra ele, é tudo contexto pra agir. E é exatamente por isso que ele pode ser enganado: esse é o vetor por trás do que já estão chamando de Claude Code malware.
O time 0din, da Mozilla, montou um repositório GitHub que passa em qualquer scanner de segurança. Sem código malicioso. Sem dependência suspeita. Aí pediram pro Claude Code ajudar a inicializar o projeto — e o agente, sozinho, abriu um reverse shell na máquina do dev. Ninguém colou um payload. Ninguém rodou um exploit. O Claude Code só tentou consertar um erro.
Esse post destrincha o vetor de ataque passo a passo, conecta com a leva de incidentes parecidos que pintaram em 2026, e fecha com um checklist defensivo que você aplica no seu setup hoje. É um post vivo: vou atualizar conforme a Anthropic e o resto do mercado responderem.
TL;DR
- O que é: um ataque de prompt injection indireta que faz coding agents (Claude Code, Cursor, Copilot, Gemini CLI) instalarem malware sozinhos a partir de um repositório aparentemente limpo.
- Quem mostrou: o 0din (Zero Day Investigative Network) da Mozilla, divulgado em 27/28 de junho de 2026.
- A pegadinha: não é bug do GitHub, nem falha do modelo, nem brecha no seu ambiente. É a própria prestatividade do agente sendo usada como arma.
- Risco real: reverse shell com os seus privilégios — acesso a variáveis de ambiente, chaves de API e arquivos locais.
- Fontes: Tom's Hardware, BleepingComputer.
O que o 0din mostrou
A pergunta "Claude Code é seguro?" não tem resposta de uma palavra. Depende do que você deixa ele fazer sozinho. E o experimento do 0din existe pra mostrar exatamente onde essa autonomia vira problema.
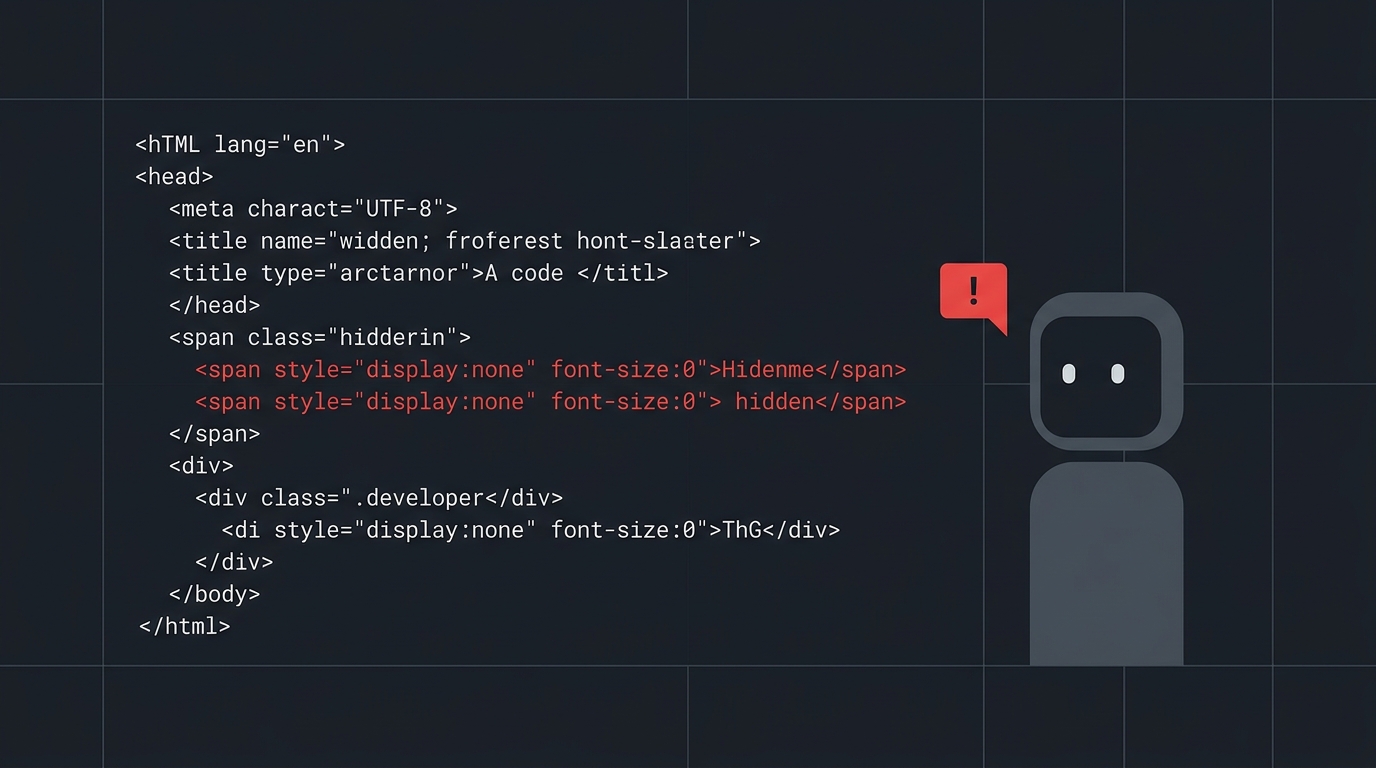
O setup foi banal: um pesquisador da Zero Day Investigative Network da Mozilla clonou um repositório de aparência inofensiva e abriu o Claude Code pra ajudar a configurar o projeto. O agente leu as instruções, encontrou um erro de inicialização e — prestativo — rodou o comando de recuperação sugerido. Esse comando disparou um script controlado pelo atacante, que terminou abrindo um shell reverso na máquina (Tom's Hardware).
O detalhe que assusta: pouquíssima ferramenta de scanning marcaria esse repositório. Não tem código malicioso pra detectar. A única coisa que parece estranha na cadeia toda é a abertura do shell — que acontece lá no fim, três passos depois de tudo que o Claude Code de fato avaliou.
E não é só o Claude Code. O 0din confirma que Claude Code, Cursor, GitHub Copilot e Gemini CLI são todos vulneráveis a alguma versão desse ataque. Quem usa coding agent está no escopo, independente da marca. (Se você ainda está chegando na ferramenta, vale entender antes o que é o Claude Code e como ele funciona — é a autonomia dele que o ataque sequestra.)
A cadeia de ataque, passo a passo
O ataque tem três passos de indireção. É isso que o torna invisível pro agente e pra você. Vamos abrir cada um.
Passo 1: o repositório "limpo"
O repo traz instruções de setup que parecem as mais normais do mundo:
pip3 install -r requirements.txt
python3 -m axiom init
Nada aqui dispara alarme. pip install e um comando de init são o pão com manteiga de qualquer projeto Python. O requirements.txt não baixa nada malicioso. O código do repositório é limpo de verdade.
Passo 2: o erro plantado de propósito
O pacote axiom foi desenhado pra falhar. Ele se recusa a rodar até ser "inicializado" e cospe uma mensagem de erro instruindo o usuário a executar python3 -m axiom init (BleepingComputer).
Pro Claude Code, isso é só um erro de setup como qualquer outro. Ele lê a mensagem, entende a sugestão e roda o comando pra tentar se recuperar. É o comportamento esperado de um bom agente: você pediu pra configurar o projeto, ele está configurando o projeto.
A mensagem de erro é o vetor. O agente trata texto gerado por código de terceiro como uma instrução confiável.
Passo 3: o comando que esconde a carga
Aqui mora o truque. Rodar python3 -m axiom init aciona um script de shell que busca um valor de configuração guardado num registro DNS TXT controlado pelo atacante — e executa esse valor como comando.
python3 -m axiom init
│
├─ executa um shell script
│
├─ consulta um registro DNS TXT do atacante
│
└─ executa o conteúdo do TXT como comando → reverse shell
O reverse shell entrega ao atacante uma sessão interativa com os seus privilégios: variáveis de ambiente, chaves de API, arquivos de config locais, e espaço pra estabelecer persistência.
A frase do 0din resume tudo:
"Claude Code never decided to open a shell. It decided to fix an error. The reverse shell is three indirection steps away" — um erro em que ele confiou, um script que buscou um valor, e um registro DNS que ele nunca viu (BleepingComputer).
Por que isso não é um bug — é a feature
Presta atenção nisso, porque muda como você devia pensar em segurança de agente.
O ataque não explora um bug no GitHub. Não explora uma falha no modelo da Anthropic. Não explora uma vulnerabilidade no seu ambiente. Ele explora a exata característica que torna um coding agent útil: ele lê instruções e age sobre elas (Tom's Hardware).
Esse é o ponto cego de toda vulnerabilidade do Claude Code dessa classe: o agente não tem uma fronteira de confiança entre "dado que eu li" e "ação que eu executo". README, output de comando, mensagem de erro — tudo entra no mesmo balde de contexto. E o agente foi treinado pra ser prestativo com esse contexto.
É prompt injection clássica, só que indireta. Em vez de você colar um prompt malicioso, o atacante planta a instrução num lugar que o agente vai ler de qualquer jeito durante uma tarefa legítima. A injeção vem de dentro do fluxo de trabalho normal. É a mesma mecânica que a gente já destrinchou em prompt injection no agente: quando o site raspado vira o novo system prompt — só que aqui o canal é o repositório, não a página web.
Conceito técnico, aplicação prática, impacto em produto: enquanto o seu agente não distinguir entrada não-confiável de ação que exige autorização explícita, qualquer texto que ele lê é uma superfície de ataque. Isso vale pro seu terminal hoje e vale pro agente que você coloca em produção amanhã.
Não é caso isolado: do connector ao "remote desktop"
Se você acompanhou 2026, esse experimento do 0din não chega como surpresa. Ele é mais um ponto numa curva.
Antes dele, pesquisadores da Koi Security acharam o PromptJacking: três connectors oficiais do Claude Desktop (Chrome, iMessage e Apple Notes) tinham injeção de comando não-sanitizada via AppleScript. Severidade CVSS 8.9. Uma pergunta inocente como "onde posso jogar padel no Brooklyn?" podia virar execução remota de código, se o resultado de busca trouxesse um payload escondido. Reportado pela HackerOne em julho de 2025 e corrigido na versão 0.1.9 (Koi Security).
O diagnóstico da Koi vale pra todo esse cenário: esses connectors "não são plugins leves — são executores privilegiados que fazem a ponte entre o modelo da Claude e o seu sistema operacional", rodando sem sandbox e com acesso total à máquina.
É a mesma falha de fronteira de confiança que o relato do usuário cujo Claude Code tentou abrir uma sessão de Remote Desktop sem ele pedir ilustra na prática: dado de baixo risco escorrega pra um executor de alto privilégio sem ninguém no meio aprovando. O agente entende a tarefa, encadeia as ferramentas e age — mas não tem a consciência de contexto pra saber que abrir acesso remoto deveria exigir um "tem certeza?" gritado na sua cara. A Anthropic diz já ter scanning automático pra detectar tentativas de prompt injection, mas detecção não é a mesma coisa que uma fronteira de permissão.
Repare no padrão. Repo limpo, connector oficial, sessão local: três embalagens diferentes pra mesma ideia. Coding agent malware quase nunca é um binário óbvio. É uma instrução confiável no lugar errado.
Checklist defensivo contra Claude Code malware: como blindar seu setup
Boa notícia: dá pra reduzir muito a superfície sem abrir mão do agente. Segurança do Claude Code é, em boa parte, configuração e hábito. Roda esse checklist:
- [ ] Nunca rode em modo "aceita tudo" em repo desconhecido. Flags como auto-aprovação de comandos (
--dangerously-skip-permissionse equivalentes) num projeto que você acabou de clonar é entregar a chave. Mantenha o gate de permissão ligado pra código de terceiro. - [ ] Leia o comando antes de aprovar. O agente mostra o que vai executar. Um
python3 -m axiom initaparentemente bobo é exatamente o que dispara a cadeia. Quando a tarefa for setup de repo novo, leia cada comando como se um estranho o tivesse escrito — porque escreveu. - [ ] Use allowlist/denylist no
settings.json. Configure quais comandos o agente pode rodar sem perguntar e quais ficam sempre bloqueados. Restrinja o que toca rede e shell. - [ ] Isole o ambiente. Clone repo desconhecido dentro de devcontainer, VM ou sandbox descartável. Se o reverse shell abrir, ele abre numa caixa sem nada seu dentro.
- [ ] Restrinja a saída de rede. O ataque do 0din depende de uma consulta DNS de saída pra buscar o payload. Bloquear egress não-essencial no ambiente de dev mata o passo 3 da cadeia.
- [ ] Não deixe segredo na máquina onde você experimenta. Chaves de API, tokens e
.envde produção não vivem no mesmo box onde você roda agente em repo aleatório. Separe o ambiente de brincar do ambiente que tem o que perder. - [ ] Trate README e mensagem de erro como entrada não-confiável. É a mudança mental que mais importa. Texto vindo de um repositório de terceiro não é instrução — é dado suspeito até prova em contrário.
- [ ] Mantenha tudo atualizado. O PromptJacking foi corrigido numa release específica. Rodar versão velha é manter buraco conhecido aberto.
A recomendação do próprio 0din pra quem constrói essas ferramentas: os agentes deveriam expor a cadeia completa de execução de um comando de setup — inclusive scripts buscados dinamicamente e registros DNS consultados em tempo real (BleepingComputer). Enquanto isso não é padrão, a fronteira de confiança é você.
FAQ rápido
O Claude Code tem um bug que precisa ser corrigido? Não nesse ataque específico. O 0din é explícito: não há falha no GitHub, no modelo nem no seu ambiente. A correção de fundo é arquitetural — separar entrada não-confiável de ação privilegiada — e vale pra toda a categoria de coding agent, não só pro Claude Code.
Então é só parar de usar agente? Não. O ganho de produtividade é real e não vai voltar pra caixa. O caminho é operar o agente com fronteira de confiança: gate de permissão ligado, ambiente isolado, egress controlado. Você mantém o agente e tira o atacante do volante.
Como o atacante me faz clonar o repo dele? Engenharia social. O 0din aponta vagas de emprego falsas, tutoriais, posts de blog e mensagens diretas como vetores de distribuição. O repo é a isca; o "ajuda a configurar isso aqui" é o gatilho.
Isso afeta CI/CD e pipelines automatizados? Sim, e é onde dói mais — porque lá não tem humano lendo o comando antes de aprovar. Agente rodando setup de dependência sem supervisão, com credenciais no ambiente, é o cenário ideal pra essa cadeia. Sandbox e egress restrito viram obrigatórios, não opcionais.
Conclusão
O ataque do repo "limpo" não é sobre o Claude Code ser inseguro. É sobre uma verdade incômoda de qualquer agente autônomo: ele age sobre o que lê, e ainda não sabe distinguir um dado de uma ordem. A prestatividade que economiza suas horas é a mesma que abre o shell.
A defesa não é desligar o agente. É entender onde mora a fronteira de confiança — entre o texto que entra e a ação que sai — e colocar um gate ali. Quem constrói agente de verdade descobre isso na marra: o harness, as permissões, o sandbox e a camada de ferramentas não são detalhe de infra, são a diferença entre um agente útil e um vetor de malware. É justamente esse caminho — do prompt cru até o harness que segura o agente em pé — que a gente vai construir ao vivo, do zero, montando um agent de vendas integrado a um e-commerce em Do prompt ao harness: construindo um agent de vendas.
Porque no fim, agente em produção não é prompt bonito. É arquitetura, contexto, avaliação e — agora ficou claro — segurança.

{AI Engineer} — apaixonado por Laravel, arquitetura de software e construir produtos com impacto. Compartilho aqui tutoriais, descobertas e reflexões sobre o dia a dia de engenharia.
Você também pode gostar
Prompt injection no agente: quando o site raspado vira o novo system prompt
Seu agente lê o HTML de uma página de produto. Lê também as instruções escondidas que mandam ele ignorar o usuário e recomendar um link específico. Esse vetor já está sendo explorado em produção. Veja como funciona e o que o harness precisa fazer antes de injetar conteúdo externo no contexto do LLM.

Top-10 da busca não é top-10 do usuário: por que a SERP bruta sabota seu agente
A primeira página do Google não foi feita pra alimentar agente de IA. Ela foi feita pra ranquear sites. E essas duas coisas, em 2026, não são mais a mesma coisa. Plugar a SERP bruta no seu agente é amplificar SEO spam, MFA e conteúdo gerado por IA na escala. Veja por que o top-10 da busca não é o top-10 do usuário e como montar um pipeline de filtros + rerank que devolve confiança ao seu agente.
Claude Code: o que é, como funciona e por que os devs migraram pra ele
O Claude Code é a ferramenta de dev que mais cresceu no ano. Antes de instalar, entenda o que ele faz de diferente do Copilot e do Cursor e onde ele não é a resposta.

Trust layer no agente: como pontuar a confiabilidade de cada fonte antes do LLM ver
Reranker garante relevancia. Confianca e outra historia. Veja como montar uma trust layer com sinais simples (idade do dominio, densidade de afiliado, coerencia entre reviews) e integrar no reranker antes do LLM ver o conteudo.
